1. 地址重定位
所谓的地址重定位(也叫地址翻译)就是修改程序中的内存地址,使得程序被载入内存后,那些地址能够指向正确的内存空间。
例如,程序中包含 call 40 语句,如果程序被加载到内存地址 1000 处,则需要修改 40 为 1040。
- 编译时重定位:在程序编译时进行地址重定位,此时需要预先知道程序将被加载到内存空间的哪个部分。
- 载入时重定位:在加载程序进内存时执行地址重定位。
- 运行时重定位:在执行每条指令时执行地址重定位。
2. 分段
分段就是在整体上将一个程序分为多个段,如,代码段、堆段、栈段等。这样加载程序时就可以分别加载每个程序段。且每个段位于内存中的不同地方,物理上不必连续。此外,每个段的长度可以不同,也可以在运行时动态变化,如,堆段、栈段。
如果不将程序分段,则载入时需要一次性将整个程序加载到一片连续的物理内存中。如果无法在内存中找到一片满足所需大小的连续内存空间,则无法运行该程序。此外,随着进程的运行,其所需的内存空间越来越多,如果此时无法满足所需大小的连续内存空间,则需要将整个程序移至其它合适的地方。
每个段在逻辑上都是从 0 开始编址的,且其地址空间也是连续的。此外,每个段也可以有不同的保护级别,如,只读、可读写等。进程会通过段表来维护每个段(段号)的基址、长度、保护级别等信息。
虚拟内存就是用户(即,程序员)所看到、进程所使用的内存视图。在引入虚拟内存之后,分段机制是作用于虚拟内存上的,即,虚拟内存(不再是物理内存)会被划分为多个段。
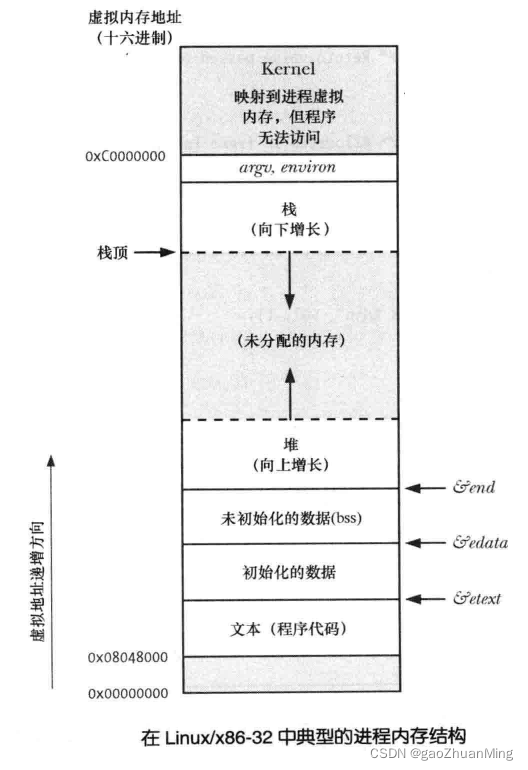
3. 分页
因为每个段的大小各不相同,如果以段为单位来管理内存,则很容易产生大量的内存碎片。当然,可以使用内存紧缩(compaction)的方式来合并这些内存碎片,但在内存紧缩期间,每个段的起始地址都会改变,所以,此时用户进程都会处于挂起的状态,而且内存紧缩通常需要花费较长的时间。
分页机制就是将物理内存分为许多大小相同的页框(page frame,也叫页帧),如,大小为 4KB。然后以页框为单位来管理内存。此时,处于段间的内存碎片会转移到页框内部,但一个内存碎片总会小于页框的大小。
分页机制也会把虚拟内存划分为一系列大小相同的页(page),页的大小和页框的大小相同。虚拟内存的大小可以大于实际的物理内存空间,因此,页的数量可以多于页框的数量。通常,每个进程都会维护一个属于自己的页表,以维持页到页框的映射关系。
因为页的数量可以大于页框的数量,因此就会存在多个页映射到同一个页框的情况。此时可以使用内存交换技术来解决此问题:
- 换出(swap out):将页框中的数据保存到磁盘中,同时设置页表中的相应表项为无效,之后该页框便空闲出来了。
- 换入(swap in):加载磁盘中的页框数据至指定页框中,然后设置页表中的相应表项。
如果虚拟内存过大、页过小,则会导致页表项过多、页表过大的情况。例如,设虚拟内存的大小为 4GB(32位地址),页大小为 4KB,则一共存在
4
G
B
/
4
K
B
=
2
20
4GB/4KB = 2^{20}
4GB/4KB=220 个表项,如果每个表项的大小为 4B,则页表的大小为
2
20
×
4
B
=
4
M
B
2^{20} \times 4B = 4MB
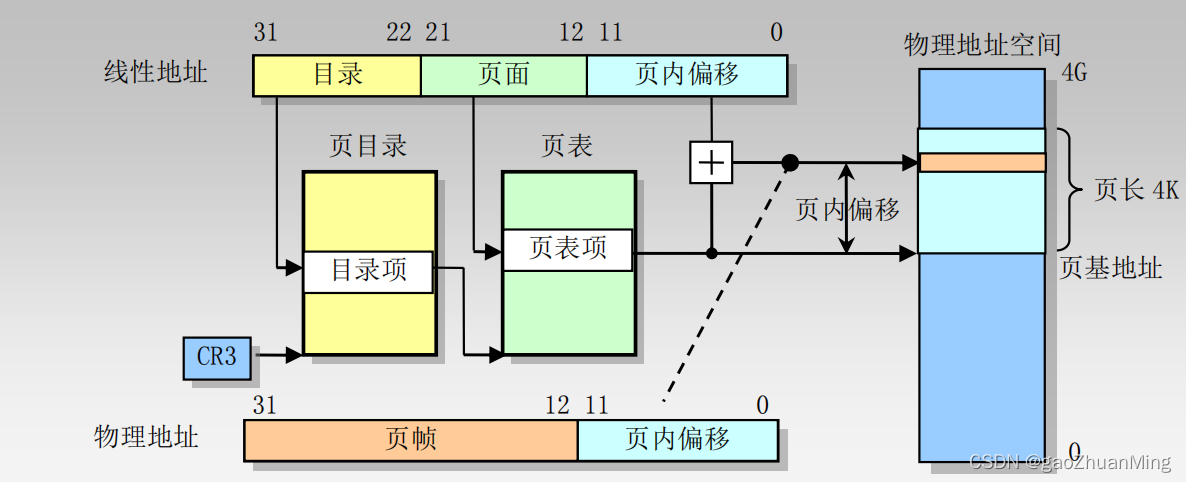
220×4B=4MB。此外,为了加速页表项的查找过程,需要保证页表所占内存空间是连续的(类似于数组,直接根据页号来定位页表项)。此时可以使用多级页表技术来解决此问题。此处以二级页表为例。
- 页大小仍为 4KB,即页内偏移字段将占用地址的12比特;
- 余下20比特中,前10比特用于一级页表(也叫页目录),后10比特用于二级页表;则一级页表、二级页表各有
2
10
2^{10}
210 个页表项;
- 每个页表项的大小为 4B,则一级页表、以及每个二级页表的大小为
2
10
×
4
B
=
4
K
B
2^{10} \times 4B = 4KB
210×4B=4KB;
- 一级页表中的每个项分别指向下一级页表,此时允许不同的页表放在不同的内存位置,而不必物理上连续;
- 另外,每个页目录项都有一个存在位,以指示该项指向的页表是否存在;如果程序所需的内存较少,则不会有很多的二级页表存在,从而能够减少页表所占的总的内存空间;
- 对应的地址翻译过程是:首先根据虚拟地址(也叫线性地址)的前10比特在页目录中找到对应的目录项,从而找到相应页表的基址;然后根据之后10比特在相应页表中找到对应的页表项,从而得到对应的页框号;最后拼接页框号和页内偏移,即可得到对应的物理地址。
多级页表的缺点是增加了地址翻译过程所需的页表项查找次数(内存访问次数)。为了解决此问题,可以使用 TLB(Translation Lookaside Buffer)技术,也就是根据引用局部性原理,将某些地址对应的 页号 -> 页框号 的映射关系给缓存下来。之后进行地址翻译前,总是先查看 TLB 是否命中,如果不命中,则继续使用正常的地址翻译过程。
4. 总结
因此,一个程序在整体上被分为多个段,一个段又会占用多个页,且一个段对应的页框在物理内存上是可以离散的,而不必连续。
在启用分段和分页机制的情况下,地址的翻译过程是:
逻
辑
地
址
→
虚
拟
地
址
→
物
理
地
址
逻辑地址 \rightarrow 虚拟地址 \rightarrow 物理地址
逻辑地址→虚拟地址→物理地址。
-
逻辑地址
→
虚拟地址
\textbf{逻辑地址} \rightarrow \textbf{虚拟地址}
逻辑地址→虚拟地址:逻辑地址就是
段号:段内偏移 的形式,如,逻辑地址 cs:ip 指向代码段内当前正在执行的指令。逻辑地址通过段表(分段)映射为虚拟地址,即,段基址 + 段内偏移。虚拟地址具有 |页号|页内偏移| 的形式(如果是二级页表,则具有 |页目录号|页号|页内偏移| 的形式)。 -
虚拟地址
→
物理地址
\textbf{虚拟地址} \rightarrow \textbf{物理地址}
虚拟地址→物理地址:虚拟地址通过页表(分页)映射为物理地址。物理地址具有
|页框号|页内偏移| 的形式。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)