目录
Base-N 算法加密解密实现:
Base64 加密解密:(C 语言、python)
Base32 加密解密:(C 语言)
Base-N 算法加密解密实现:
Base64 加密解密:(C 语言、python)
Base64 介绍:
Base64 是一种基于 64 个可打印字符来表示二进制数据的表示方法。由于 2^6=64,所以每 6 个比特为一个单元,对应某个可打印字符。3 个字节有 24 个比特,对应于 4 个 Base64 单元,即 3 个字节可由 4 个可打印字符来表示。它可用来作为电子邮件的传输编码。在 Base64 中的可打印字符包括字母 A-Z、a-z、数字 0-9,这样共有 62 个字符,此外两个可打印符号在不同的系统中而不同。一些如 uuencode 的其他编码方法,和之后 BinHex 的版本使用不同的 64 字符集来代表 6 个二进制数字,但是不被称为 Base64。
Base64 常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据,包括 MIME 的电子邮件及 XML 的一些复杂数据。 -----维基百科
编码规则:
第一步,将每三个字节作为一组,一共是 24 个二进制位
第二步,将这 24 个二进制位分为四组,每个组有 6 个二进制位
第三步,在每组前面加两个 00,扩展成 32 个二进制位,即四个字节
第四步,根据下表,得到扩展后的每个字节的对应符号,这就是 Base64 的编码值
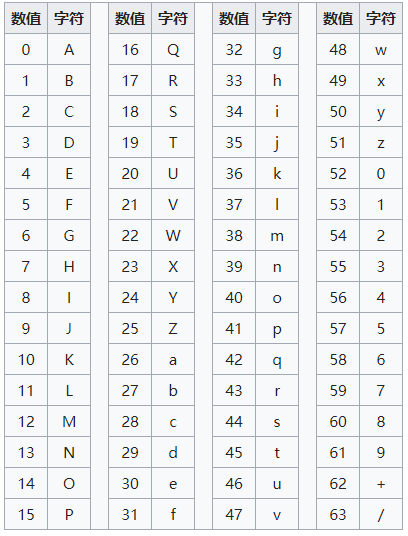
特别的:
如果要编码的字节数不能被 3 整除,最后会多出 1 个或 2 个字节,那么可以使用下面的方法进行处理:先使用 0 字节值在末尾补足,使其能够被 3 整除,然后再进行 Base64 的编码。
在编码后的 Base64 文本后加上一个或两个 = 号,代表补足的字节数。也就是说,当最后剩余两个八位字节( 2 个byte)时,最后一个 6 位的 Base64 字节块有四位是 0 值,最后附加上两个等号;如果最后剩余一个八位字节( 1 个byte)时,最后一个 6 位的 base 字节块有两位是 0 值,最后附加一个等号。
参考下表:

由于逆向中涉及 base64 加密解密很多次了,每次都不能一眼看出来,所以自己用 python 和 C 语言各仿照着写了一遍流程,希望能给以后加深印象。
Base64 加密解密的 C 语言实现:
逻辑流程图梳理:
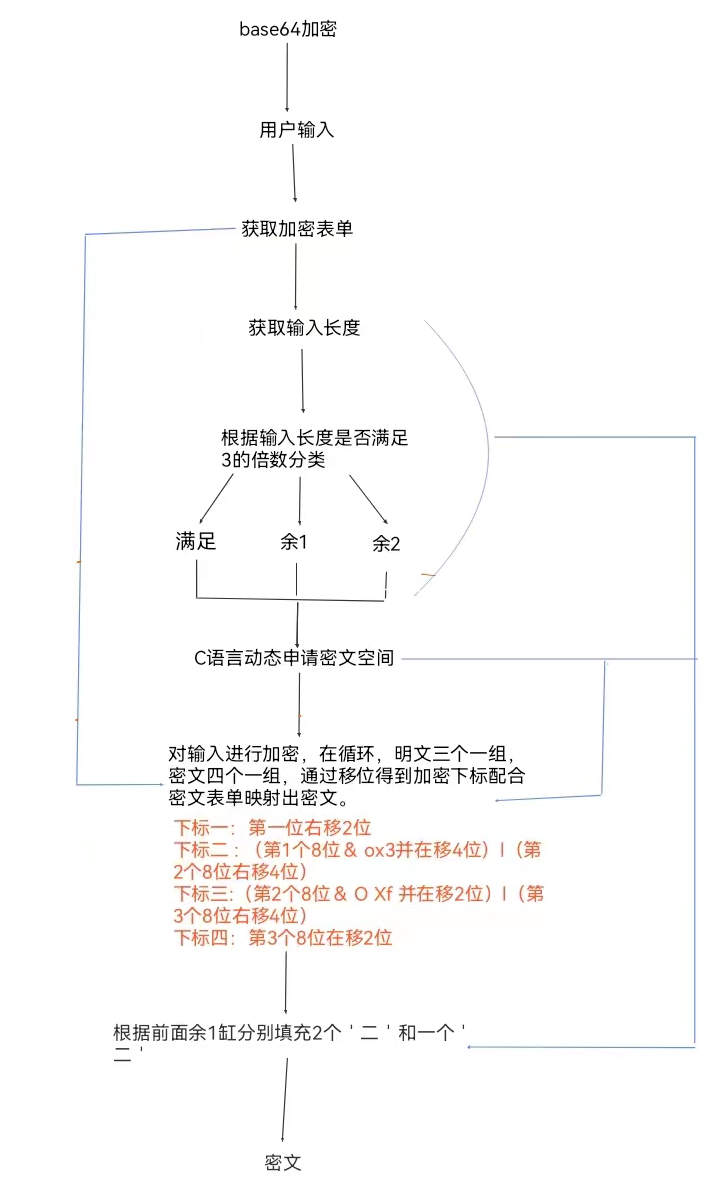
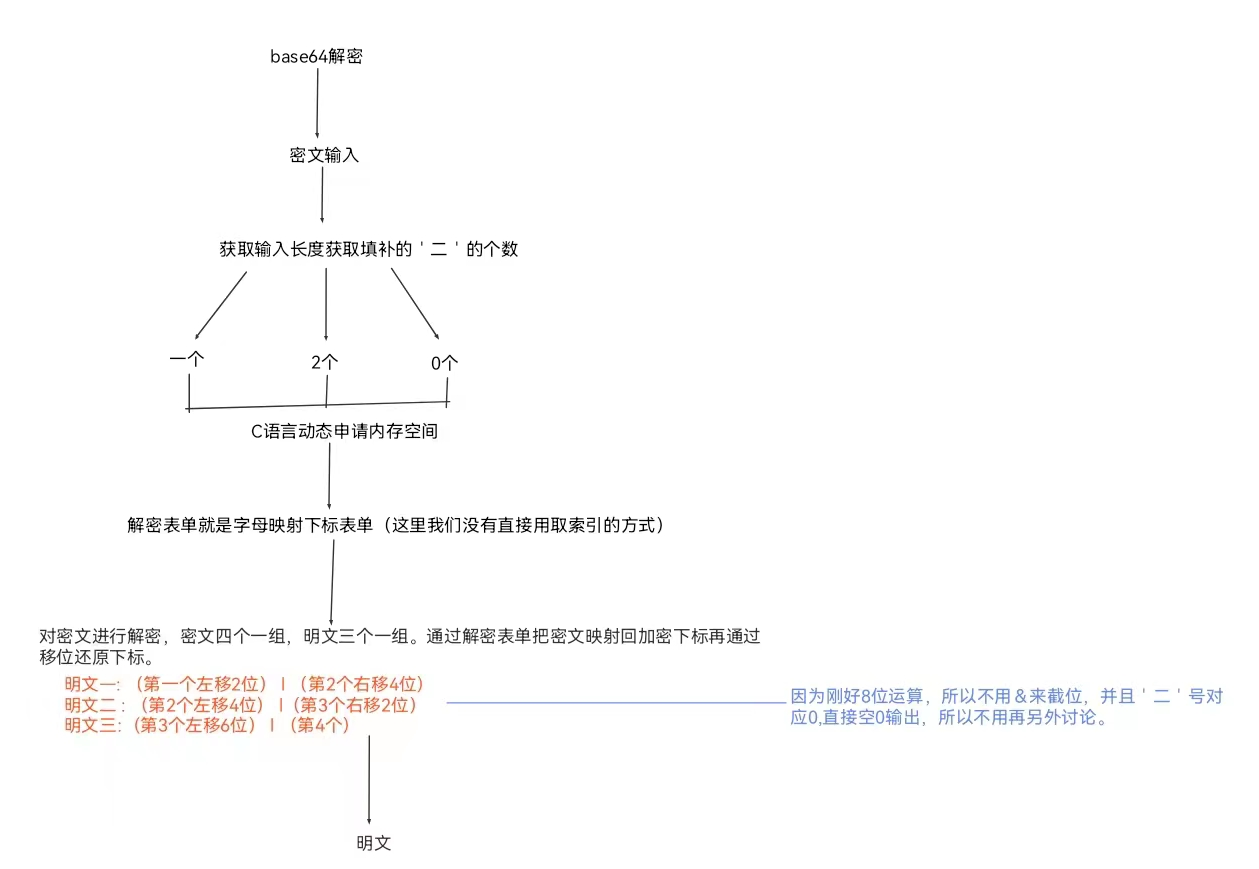
根据流程图写代码:
#include<stdio.h>
#include<stdint.h>
#include<string.h>
#include<stdlib.h>
char *base64encry(char* input) //base64 加密函数
{
int len=0,str_len=0;
char *encry;
char *table64="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
len=strlen(input); //获取输入长度
if (len%3==0)
str_len=(len/3)*4;
else
str_len=((len/3)+1)*4;
encry=(char *)malloc(sizeof(char)*str_len+1);
for(int i=0,j=0;i<len;i+=3,j+=4)
{
encry[j]=table64[input[i]>>2];
encry[j+1]=table64[((input[i]&0x3)<<4)|((input[i+1])>>4)];
encry[j+2]=table64[((input[i+1]&0xf)<<2)|(input[i+2]>>6)];
encry[j+3]=table64[input[i+2]&0x3f];
}
switch(len%3)
{
case 1: encry[str_len-1]='=';
encry[str_len-2]='=';
break;
case 2: encry[str_len-1]='=';
break;
}
encry[str_len]='\0';
return encry;
}
char * base64decry(char *input)
{
int table[]={0,0,0,0,0,0,0,0,0,0,0,0, //根据base64表,以字符找到对应的十进制数据 ,这里是int类型,移位的时候要转换成char地址。
0,0,0,0,0,0,0,0,0,0,0,0, //主要是没用下标索引类的函数,这里的ascii表示从0开始的
0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,62,0,0,0,
63,52,53,54,55,56,57,58,
59,60,61,0,0,0,0,0,0,0,0,
1,2,3,4,5,6,7,8,9,10,11,12,
13,14,15,16,17,18,19,20,21,
22,23,24,25,0,0,0,0,0,0,26,
27,28,29,30,31,32,33,34,35,
36,37,38,39,40,41,42,43,44,
45,46,47,48,49,50,51
};
int len=0,str_len=0;
char *decry;
len=strlen(input);
if (strstr(input,"=="))
str_len=(len/4)*3-2;
else if (strchr(input,'='))
str_len=(len/4)*3-1;
else
str_len=(len/4)*3;
decry=(char *)malloc(sizeof(char)*str_len+1);
for (int i=0,j=0;i<len;i+=4,j+=3)
{
decry[j]=(table[input[i]]<<2)|(table[input[i+1]]>>4);
decry[j+1]=(table[input[i+1]]<<4)|(table[input[i+2]]>>2);
decry[j+2]=(table[input[i+2]]<<6)|(table[input[i+3]]);
}
decry[str_len]='\0';
return decry;
}
int main()
{
char buff[100],*encry,*decry;
printf("请输入要加密的字符:");
scanf("%s",buff);
encry=base64encry(buff);
printf("\n加密后的字符:%s",encry);
decry=base64decry(encry);
printf("\n解密后的字符:%s",decry);
return 0;
}
用法:

Base64 加密解密的 python 实现:
base64="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" #准备好base64的基表
def encryption(inputstring): #定义加密函数
ascii=['{:0>8}'.format(str(bin(ord(i))).replace('0b','')) for i in inputstring] #把每个输入字符保证8位一个,才能3*8变4*6。
#{:0>8}是右对齐8位然后左边补0,因为python是自己判断数据大小类型的,所以必须强制满足8位。bin转化二进制会带0b前缀,所以要用replace('0b','')去掉。
encrystr='' #while外的变量,返回base64加密后的字符串
equalnumber=0 #while外的变量,记录拆分后不足4的倍数时需要补齐的等号个数
while ascii:
subascii=ascii[:3] #用一个子列表subascii每次取输入的三位进行操作,前面操作后每位都是8位
while len(subascii)<3: #这里其实是最后一段截取中才会用上的,不满足3位时要单独取出,记录equalnumber数量用于后期补'='号,然后补齐8位的0免得干扰后面3*8拆分成4*6
equalnumber+=1 #计算要补‘=’的个数
subascii+=['0'*8] #补8个0来填充够3的倍数,这然后面就不会出错。
substring=''.join(subascii)#用substring合并subascii的3个8位,准备进行拆分操作
encrystringlist=[substring[x:x+6] for x in [0,6,12,18]] #开始进行3*8变4*6的拆分,每次拆分一组24位。
encrystringlist=[int(x,2) for x in encrystringlist] #把前面拆分的6位一组转成10进制,就不用进行位数补齐操作了,这是用来后面对应base64基表的下标。
if equalnumber:
encrystringlist=encrystringlist[0:4-equalnumber] #如果前面不足3字符补了0,比如2个8位字符16位,拆分后就要用3个6位共18位,所以有效位是4-equalnumber
encrystr+=''.join(base64[x] for x in encrystringlist) #这里encrystringlist已经在前面拆分成4*6且转换成10进制了,所以对应基表的下标。
ascii=ascii[3:] #每次向后取3个列表元素,对应while循环条件
encrystr+='='*equalnumber #因为前面encrystringlist[0:4-equalnumber]去掉了补0位,所以这里最后补齐'='号
return encrystr
def decryption(inputstring):
ascii=['{0:0>6}'.format(str(bin(base64.index(i))).replace('0b',''))for i in inputstring if i!='=']#从加密字符中取除补位'='之外加密字符,即6位生成的base64基表下标的数,按6位一组排列,准备拆分
decrystr=''#准备while外的解密后的字符
equalnumber=inputstring.count('=')#这里计数补位的'='号的个数,后面不够8位时会根据'='号补加位数。
while ascii:
subascii=ascii[:4]#取加密字符的4个6位一组共24位准备拆分合并成3*8
substring=''.join(subascii)#先连成一串24位
if len(substring)%8!=0:
substring=substring[0:-1*equalnumber*2]
#截取到倒数第equalnumber*2个元素。对不足8位的组补位,因为加密时1个8位要来2个6位,两个'='号,截取到8位就是倒数第4位1*2*2。2个8位要3个6位,要一个'='号,截取到16位就是倒数第2位1*1*2。
decrystringlist=[substring[x:x+8] for x in [0,8,16]]#开始进行4*6变3*8的拆分,每次拆分4个6位一组24位。
decrystringlist=[int(x,2) for x in decrystringlist if x]#把前面拆分的8位一组转成10进制,用来对应十进制ASCII码,if x功能不清楚,但不可缺少,应该是要排除空格吧。
decrystr+=''.join([chr(x) for x in decrystringlist])#这里decrystringlist已经在前面拆分成3*8且转换成10进制了,现在转换成ASCII码。
ascii=ascii[4:]#每次向后取4个列表元素,对应while循环条件
return decrystr
if __name__=="__main__":
print(encryption('a'))
print(decryption('YQ=='))
Base32 加密解密:(C 语言)
base32 简介:
Base32 编码使用 32 个 ASCII 字符对任何数据进行编码, Base32 与 Base64 的实现原理类似,同样是将原数据二进制形式取指定位数转换为 ASCII 码。首先获取数据的二进制形式,将其串联起来,每 5 个比特为一组进行切分,每一组内的 5 个比特可转换到指定的 32 个 ASCII 字符中的一个,将转换后的 ASCII 字符连接起来,就是编码后的数据。
base32 字典:
Base32 依赖更小的字典,Base32 编码时每 5 个字符为一个分组,字典的长度为 25 + 1=33。
Base32 通用的字典定义如下:
| Value | Encoding | Value | Encoding | Value | Encoding | Value | Encoding |
| 0 | A | 9 | J | 18 | S | 27 | 3 |
| 1 | B | 10 | K | 19 | T | 28 | 4 |
| 2 | C | 11 | L | 20 | U | 29 | 5 |
| 3 | D | 12 | M | 21 | V | 30 | 6 |
| 4 | E | 13 | N | 22 | W | 31 | 7 |
| 5 | F | 14 | O | 23 | X | padding | = |
| 6 | G | 15 | P | 24 | Y | | |
| 7 | H | 16 | Q | 25 | Z | | |
| 8 | I | 17 | R | 26 | 2 | | |
Base32 还提供了另外一种字典定义,即 Base32 十六进制字母表:
| Value | Encoding | Value | Encoding | Value | Encoding | Value | Encoding |
| 0 | 0 | 9 | 9 | 18 | I | 27 | R |
| 1 | 1 | 10 | A | 19 | J | 28 | S |
| 2 | 2 | 11 | B | 20 | K | 29 | T |
| 3 | 3 | 12 | C | 21 | L | 30 | U |
| 4 | 4 | 13 | D | 22 | M | 31 | V |
| 5 | 5 | 14 | E | 23 | N | padding | = |
| 6 | 6 | 15 | F | 24 | O | | |
| 7 | 7 | 16 | G | 25 | P | | |
| 8 | 8 | 17 | H | 26 | Q | | |
Base32 加密解密的 C 语言实现:
逻辑流程图梳理:


#include<stdio.h>
#include<stdint.h>
#include<string.h>
#include<stdlib.h>
char *base32encry(char* input) //base64 加密函数
{
int len=0,str_len=0;
char *encry;
char *table32="ABCDEFGHIJKLMNOPQRSTUVWXYZ234567";
len=strlen(input); //获取输入长度
if (len%5==0)
str_len=len/5*8;
else
str_len=((len/5)+1)*8;
encry=(char *)malloc(sizeof(char)*str_len+1);
for(int i=0,j=0;i<len;i+=5,j+=8)
{
encry[j]=table32[input[i]>>3];
encry[j+1]=table32[((input[i]&0x7)<<2)|((input[i+1])>>6)];
encry[j+2]=table32[(input[i+1]>>1)&0x1f];
encry[j+3]=table32[((input[i+1]&0x1)<<4)|((input[i+2])>>4)];
encry[j+4]=table32[((input[i+2]&0xf)<<1)|((input[i+3])>>7)];
encry[j+5]=table32[(input[i+3]>>2)&0x1f];
encry[j+6]=table32[((input[i+3]&0x3)<<3)|((input[i+4])>>5)];
encry[j+7]=table32[input[i+4]&0x1f];
}
switch(len%5)
{
case 1:encry[str_len-1]='\0';
encry[str_len-2]='\0';
encry[str_len-3]='\0';
encry[str_len-4]='\0';
encry[str_len-5]='\0';
encry[str_len-6]='\0';
break;
case 2:encry[str_len-1]='\0';
encry[str_len-2]='\0';
encry[str_len-3]='\0';
encry[str_len-4]='\0';
break;
case 3:encry[str_len-1]='\0';
encry[str_len-2]='\0';
encry[str_len-3]='\0';
break;
case 4:encry[str_len-1]='\0';
break;
}
encry[str_len]='\0';
return encry;
}
char * base32decry(char *input)
{
int table[]={0,0,0,0,0,0,0,0,0,0,0,0, //根据base64表,以字符找到对应的十进制数据 ,这里是int类型,移位的时候要转换成char地址。
0,0,0,0,0,0,0,0,0,0,0,0, //主要是没用下标索引类的函数,这里的ascii表示从0开始的
0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,
0,0,0,26,27,28,29,30,
31,0,0,0,0,0,0,0,0,0,0,
1,2,3,4,5,6,7,8,9,10,11,12,
13,14,15,16,17,18,19,20,21,
22,23,24,25,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0
};
int len=0,str_len=0;
char *decry;
len=strlen(input);
if ((len%8)==0)
str_len=(len/8)*5;
else
str_len=((len/8)+1)*5;
decry=(char *)malloc(sizeof(char)*str_len+1);
for (int i=0,j=0;i<len;i+=8,j+=5)
{
decry[j]=(table[input[i]]<<3)|(table[input[i+1]]>>2);
decry[j+1]=((table[input[i+1]]&0x3)<<6)|(table[input[i+2]]<<1)|(table[input[i+3]]>>4);
decry[j+2]=((table[input[i+3]]&0xf)<<4)|(table[input[i+4]]>>1);
decry[j+3]=((table[input[i+4]]&0x1)<<7)|(table[input[i+5]]<<2)|(table[input[i+6]]>>3);
decry[j+4]=((table[input[i+6]]&0x7)<<5)|(table[input[i+7]]);
}
switch(len%8)
{
case 2:decry[str_len-1]='\0';
decry[str_len-2]='\0';
decry[str_len-3]='\0';
decry[str_len-4]='\0';
break;
case 4:decry[str_len-1]='\0';
decry[str_len-2]='\0';
decry[str_len-3]='\0';
break;
case 5:decry[str_len-1]='\0';
decry[str_len-2]='\0';
break;
case 6:decry[str_len-1]='\0';
break;
}
decry[str_len]='\0';
return decry;
}
int main()
{
char buff[100],*encry,*decry;
printf("请输入要加密的字符:");
scanf("%s",buff);
encry=base32encry(buff);
printf("\n加密后的字符:%s",encry);
decry=base32decry(encry);
printf("\n解密后的字符:%s",decry);
return 0;
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)