文 | 小戏
在 GPT-4 屠榜了 NLP,SAM 零样本分割一切让 CV 消失后,不知道大家会不会有好奇 AI 三大现实应用的另一边岁月静好的推荐系统有没有感受到来自遥远大模型带来的巨大压力。
尽管 ChatGPT 的训练过程似乎没有对推荐系统太多的兼容,但是就现在 ChatGPT + 一切的大势来看,ChatGPT 把手伸到推荐系统也是或早或晚的事。
不过先说一个好消息,在阿里团队针对 ChatGPT 应用于推荐系统的细致测评后,终于,推荐算法工程师的工作看起来是保住了 !ChatGPT 在许多任务上的表现都差强人意,ChatGPT 强大的泛化能力似乎在推荐系统中暂时失效了 。
但是,总还带着一个但是,研究也发现,当不使用传统的评价方法,而采用真人评估时,ChatGPT 似乎更能真正理解提供的信息并生成更清晰、更合理的结果 ,并且这还是在完全没有使用 ChatGPT 在专门的推荐数据集上训练得到的结果。
这似乎暗示了虽然现在 ChatGPT 还不能向对 NLP 那样颠覆现有的研究范式,但是这类大规模语言模型在推荐系统中似乎未来可期 ……那么就一起来看看今天的这篇工作吧!
论文题目: Inducing anxiety in large language models increases exploration and bias 论文链接: https://arxiv.org/abs/2304.10149
各个大模型的研究测试传送门 阿里通义千问传送门: https://tongyi.aliyun.com/chat
百度文心一言传送门: https://yiyan.baidu.com/
ChatGPT传送门(免墙,可直接测试): https://yeschat.cn
GPT-4传送门(免墙,可直接测试,遇到浏览器警告点高级/继续访问即可): https://gpt4test.com
从协同过滤到 ChatGPT 简单回想一下推荐系统近年来的发展,从最开始的协同过滤,到后来将深度学习技术引入推荐系统,衍生出基于内容的推荐、基于知识的推荐等等。但是,这些方法共同具有的显著制约在于它们都是特定于任务的,因此需要特定的数据进行训练 。而过去 NLP 所说的范式转移,恰恰是构建了不同的预训练模型,显著增强了这些模型的泛化能力。
因此,最近一段时间,也有不少关于推荐系统的预训练语言模型出现,譬如 P5 以及 M6-Rec 。伴随着这几个月 ChatGPT 风头正起,ChatGPT 在句子重述、情感分析及机器翻译等任务上都颇具竞争力,那一个随着而来的问题就是 ChatGPT 是否能在经典的推荐任务中保持良好的性能呢 ?这篇文章就此展开。
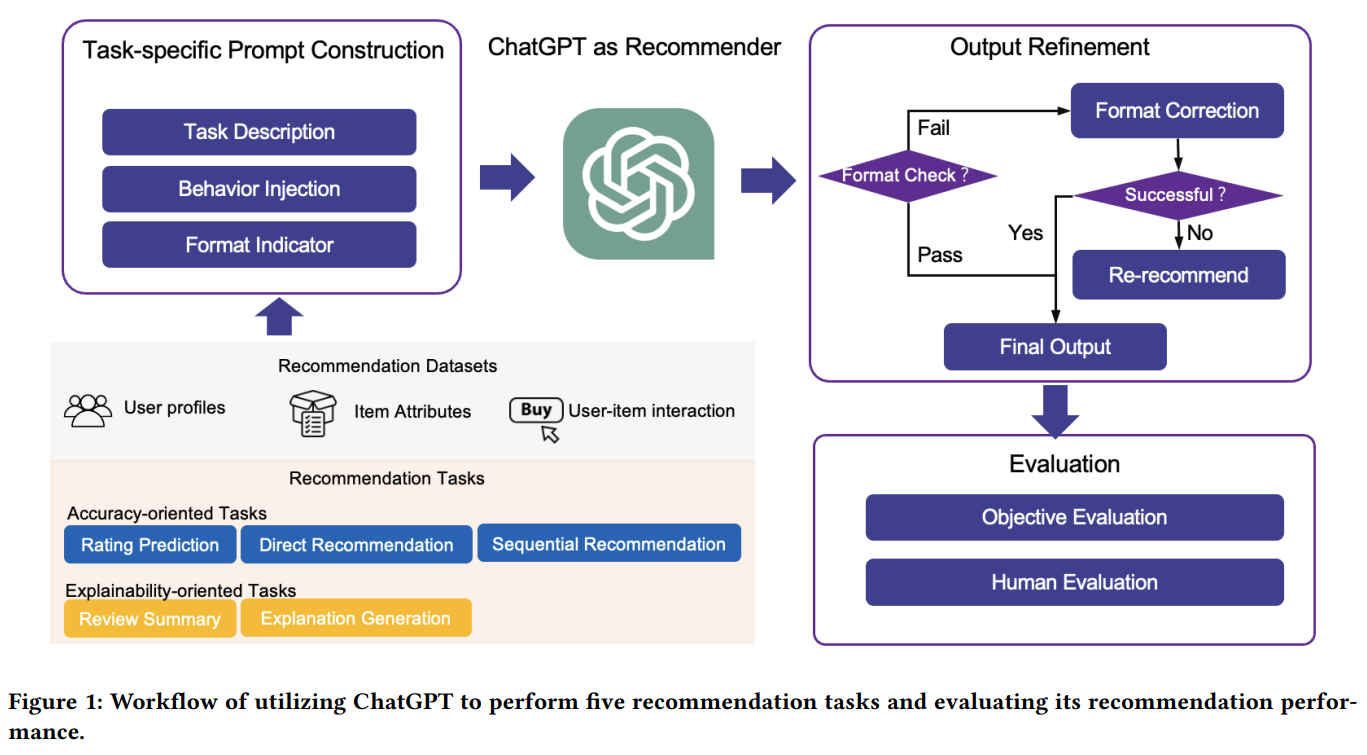
整个将 ChatGPT 用于推荐的工作流如下图所示,针对不同的推荐任务,论文设计了一系列不同的 Prompt,将 ChatGPT 作为一个黑盒式的推荐器,通过一步为保证输出稳定性的输出精炼步骤,得到最终推荐结果 。区别于传统的推荐系统,在使用 ChatGPT 的整个过程中,都没有对 ChatGPT 进行微调,而直接考验其的泛化能力。
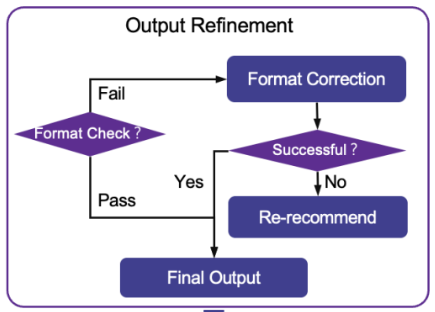
Prompt 设计 针对不同任务的 Prompt 主要由三部分构成,分别是任务描述(Task Description),行为注入(Behavior Injection)以及格式指示(Format Indicator) 。其中任务描述用来将推荐任务表述为自然语言处理任务,行为注入被设计用来捕捉用户的偏好与需求,格式指示则用于规范输出格式,使得推荐结果更易理解和评估。特别的,由于 ChatGPT 生成模型的特质,其回复生成过程被人为的引入了随机性,这一点在推荐系统中将会导致推荐的输出结果不可靠,从而使得评估推荐系统的表现出现困难 。因此,论文设计了输出精炼(Output Refinement)模块,对输出进行格式检查,如果输出通过了格式检查,则代表其格式可以用于后续评估工作,而如果没有通过,则基于规则进行格式修正,直到满足格式要求为至。
具体而言,针对五种经典的推荐系统任务,其 zero-shot 与 few-shot Prompt 设计如下:
正确率导向型任务
评分预测 :评分预测旨在预测用户对特定项目的评分,如上图所示,黑字部分代表任务的描述,评分预测被翻译为“How will user rate this product_title?”,灰字表示当前的输入,即要求用户评分的项目,红字表示针对输出的格式要求,在评分预测任务中,要求有“1 being lowest and 5 being highest”和“Just give me back the exact number a result”;
序列推荐 :序列推荐任务要求系统根据用户过去的序贯行为预测其之后的行为,如上图所示,论文为该任务设计了三种 Prompt 格式,分别是基于交互历史直接预测用户的下一个行为,从候选列表中选出可能的下一个行为以及判断指定行为成为用户下一个行为的可能性;
直接推荐 :直接推荐指通过利用用户评分或评论信息直接显示反馈推荐的任务,论文将这一任务的 Prompt 设计为从潜在的候选项中选择出最适合的一项;
生成导向型任务
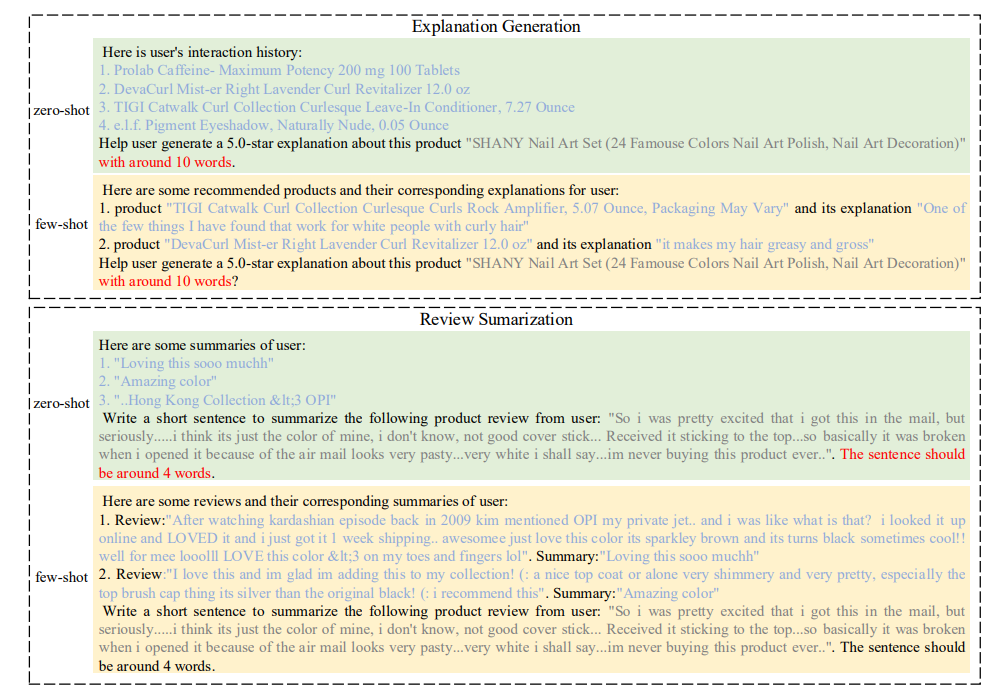
解释生成 :解释生成是为用户提供解释以澄清为什么会推荐此项的推荐系统任务,具体地,如上图所示,论文要求 ChatGPT 生成一个文本解释,以阐明解释生成过程,对每个类别,可以包含如提示词或星级评分等的辅助信息;
评论总结 :旨在使用推荐系统自动生成用户评论摘要。通过输入用户的评论信息,Prompt 提示推荐系统总结评论的主要含义。
测评!ChatGPT 到底是不是一个好的推荐器? 为了测评 ChatGPT 的推荐能力,论证在亚马逊的真实数据集 Beauty 上进行了广泛的实验,旨在回答如下三个问题:
与现有的推荐模型相比,ChatGPT 表现究竟如何?
具体而言,论文将商品标题作为元信息,收集用户点击或互动过的 n 件物品(n=10)和 k 条历史记录(k=3),隐式学习用户的兴趣。对于序列推荐任务的三种任务描述,第一种通过论文按顺序输入用户的历史交互物品,并让 ChatGPT 直接预测进行实现,第二种在评估中设置正样本数为 1,负样本数为 99,从而形成一个长度为 100 的候选列表,用于 ChatGPT 进行选择的任务。第三种则使用 Bert 计算标题向量与所有向量的相似度,选择相似度最高的物品作为候选。而对于生成型任务,论文对每个任务采样了一些不同方法的结果,由人工手动进行评分和排名。
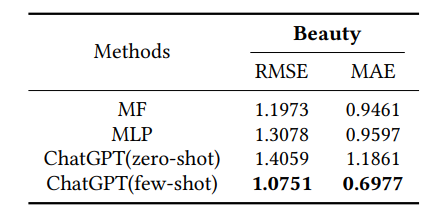
评分预测
评分预测主要使用 RMSE(Root Mean Square Error,RMSE) 和 MSE(Mean Absolute Error,MAE) 进行评估,如上表所示,对比 MF 和 MLP 方法,可以看出,使用 few-shot 的 ChatGPT 评分优于两种传统方法,体现了这类大规模语言模型在这种预测任务中的良好性能 。
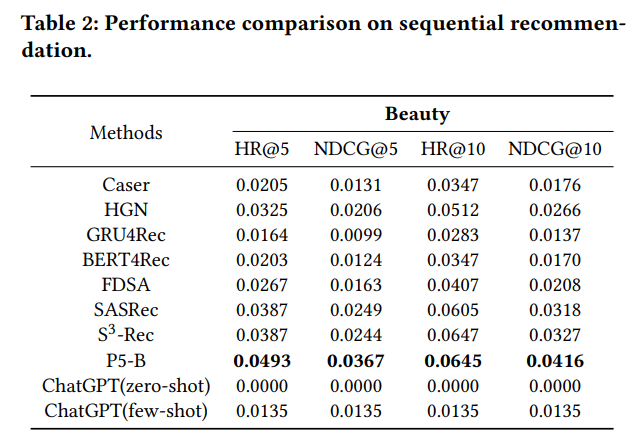
序列推荐
序列推荐任务主要使用 HR@k(top-k Hit Ratio,HR@k)以及 NDCG@k(top-k Normalized Discounted Cumulative Gain,NDCG@k)进行评估。对比传统模型(传统深度学习推荐模型及预训练推荐系统模型),可以明显发现在 zero-shot 下 ChatGPT 表现几乎全线低于所有基准模型,而当使用了 few-shot 时,尽管看得出来性能有所提示,在 NDCG@5 中超过了 GRU4Rec,但是依旧明显弱于其他所有传统模型 。对于这一结果,论文猜测可能是由于 ChatGPT 输入字符的限制,导致推荐物品主要以标题作为表示,这使得物品之间的关系无法被有效表示,这对推荐任务来说可能是至关重要的。同时,ChatGPT 也有可能生成不存在于数据集中的项目标题,但是论文作者表示,尽管他们已经使用相似性匹配将预测标题映射到了数据集中现有的标题中,但是这种映射并没有带来显著的增益。
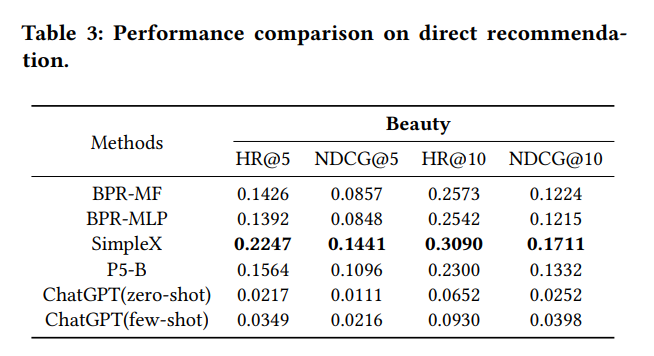
直接推荐
直接推荐使用了与序列推荐相似的评价标准,从结果可以看到,当使用 zero-shot 时,推荐性能依然显著低于传统方法,这可能源于给 ChatGPT 的信息不足,导致无法捕捉用户的兴趣。当然,虽然使用了 few-shot 方法对模型性能带来了提升,但是依然没有打败传统方法 。
而更有意思的一点是,论文发现 ChatGPT 的推荐似乎非常依赖了构建的候选池中项目的顺序 。在极端情况下,当正确值被放在候选池中的第一个位置时,ChatGPT 的评估指标比打乱时高于十倍。这一点似乎表明 ChatGPT 进行推荐时更多的参考的答案 A,B,C,D 的位置,并且带有偏差的得出了越靠前的选项越重要,换言之 ChatGPT 似乎通过大量刷题,没有学到试卷里的要考察的真正知识,而是学到了选 A,B 的概率要大于选 C,D 的概率这一信息,这个错误的知识会为 ChatGPT 在许多任务的应用中带来巨大的麻烦,也为 ChatGPT 的智能性提出了挑战 。
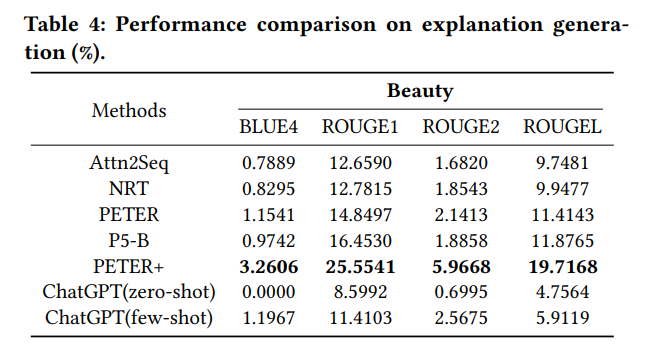
解释生成
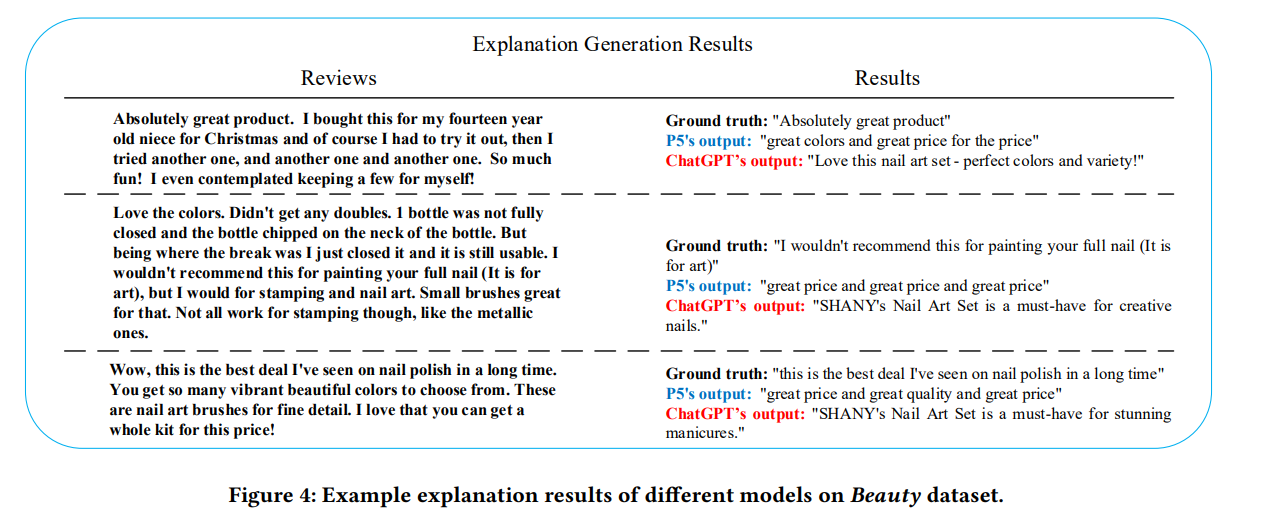
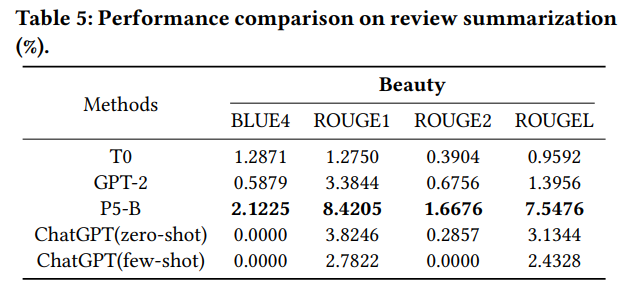
对于生成类任务,论文使用了双语替换评测(Bilingual Evaluation Understudy,BLEU-n)以及 n-gram 召回导向评价(Recall-Oriented Understudy for Gisting Evaluation,ROUGE-n)来评估解释生成和评论总结任务。从指标的角度来看,以 P5 为代表的预训练推荐系统似乎表现更加出色,但是作者在考察来了 ChatGPT 生成的句子后,如下图所示,可以看到 ChatGPT 的生成能力十分出色,因此作者开始思考是否是传统的评价指标带来了这种评价偏差 。
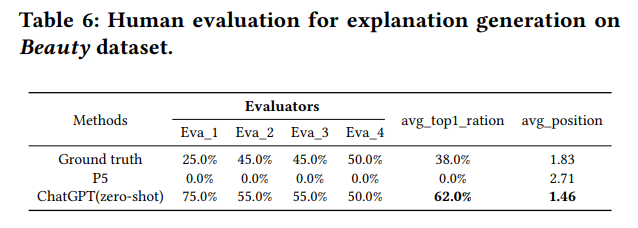
论文认为,由于 P5 的学习方式更加专注于文本结构与语法规则,因此似乎表现更加出色。而 ChatGPT 由于其对话生成的特性,更加考虑了语言交互和多样性,因此可能并不受这些传统的指标的青睐 。而如果引入真实人类进行评价,如下图所示,我们可以看到,尽管四位人工注释者的结果有一定程度的主观性,但得分分布相对一致,普遍认为 ChatGPT 生成的解释更清晰更合理,甚至优于基准解释。与此同时,P5 的表现最差,其生成结果往往得出并不流畅的句子 。
评论摘要 类似于解释生成,论文首先对比在 BLEU 和 ROUGE 指标下不同模型的生成结果。
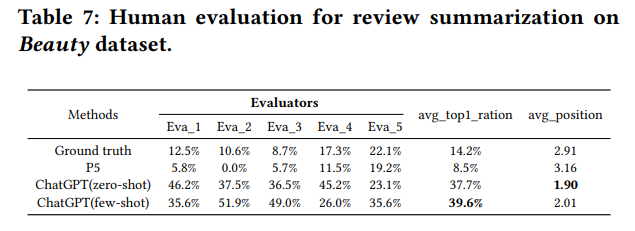
显然,在传统指标中,依然是 P5 占优,通过考察 P5 的生成结果,发现 P5 的摘要经常性的会遗漏关键词,尽管符合句法逻辑,但是这类摘要却忽略了评论中最有意义的信息。而 ChatGPT 则通过深入地理解和总结生成了更有效的摘要 。
通过进行人类评估也可以发现,所有注释者一致认为 ChatGPT 表现最佳,远超基准和 P5。
总结 这篇论文通过构建 ChatGPT 用于推荐任务的工作流,横向对比评估了 ChatGPT 在不同推荐任务中的性能,可以看到在评分类、生产类的任务中,ChatGPT 都取得了领先,这大概率源于 ChatGPT 自身学习时具有的独特能力。
但是 ChatGPT 在真正“推荐”上,由于其输入字符等的局限性,导致表现普遍差于现有的方法,甚至使用 ChatGPT 的推荐,还暗含了许多没有被注意到的内部偏差,这些都对 ChatGPT 在推荐中的应用埋下隐患**。
但是,现在的 ChatGPT 还是一个完全没有经过微调,也没有在特定数据集上进行学习过的模型,而其蕴含的对顺序偏好的误差,一方面表明 ChatGPT 似乎不那么聪明,但另一方面又能代表 ChatGPT 强大的归纳统计能力。这篇论文很清晰的点出了 ChatGPT 用于推荐的局限性,但是也可以开启人们对于这类强大模型用于推荐的讨论。
ChatGPT 的强大能力是令人感到欣喜的,尽管这一阵子写了不少 ChatGPT 取代这取代那的文章,但是与其说是取代,倒不如说是 ChatGPT 的出现开始倒逼我们不断去思考去重新定义我们所处的行业、所做的工作、所用的技术 。倒也不用担忧未来 GPT-78910 对我们生活林林总总的影响,至少目前,归根结底,ChatGPT 还只是一个背答案的大小孩而已。