约束条件下的最优化问题
在上文中我们得到了SVM的目标函数,是一个约束最优化问题,下面来求解这个问题。
1.约束最优化问题
既然是约束,就可以分为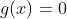 和
和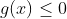 两种形式(注意后面也有等于,不是<),如下图所示,分别是在一条线上和一片区域上寻找最优解。
两种形式(注意后面也有等于,不是<),如下图所示,分别是在一条线上和一片区域上寻找最优解。

(1)最优解特点:
观察等式约束情况,可以发现直线上的最优解正好与等高线相切。这种情况是必然的,在最优解处目标函数的梯度方向如果不与直线的切线垂直的话,那么梯度方向必然存在一个分量与切线方向相同,也就是最优解还可以向这个方向移动,这里就不是最优解。有如下三个推论:
推论1:在那个宿命的相遇点 (也就是等式约束条件下的优化问题的最优解),原始目标函数
(也就是等式约束条件下的优化问题的最优解),原始目标函数 的梯度向量
的梯度向量 必然与约束条件
必然与约束条件 的切线方向垂直。
的切线方向垂直。
推论2:函数的梯度方向也必然与函数自身等值线切线方向垂直。
推论3:“函数与函数 的等值线在最优解点处相切,即两者在点的梯度方向相同或相反”
的等值线在最优解点处相切,即两者在点的梯度方向相同或相反”
由推论3可以得出以下结果:

这就是构造拉格朗日函数的原因,将约束条件与目标函数整合到一起,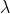 就是拉格朗日乘子,它用来缩放使两个梯度求和为0。同时我们还有g(x)=0这个条件,构造拉格朗日函数
就是拉格朗日乘子,它用来缩放使两个梯度求和为0。同时我们还有g(x)=0这个条件,构造拉格朗日函数 ,对x和 求偏导等于0即可。
,对x和 求偏导等于0即可。
2.KKT条件
但是SVM的目标函数里的约束条件是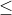 ,此时最优解x有两种可能:
,此时最优解x有两种可能:

(1)x在g(x)边界
此时与条件相同,不难理解这时最优解x在g(x)上的梯度和在f(x)上的梯度是相反的,也就是此时>0
(2)x在g(x)内部
此时约束条件是没有起到作用的,因为不管怎么优化都能满足约束条件,所以此时=0
综合上面两种情况,可以求得:

这个就是KKT条件
3.拉格朗日对偶
之前我们构造了在等式约束条件下的拉格朗日函数,但那是基于三个推论,因为目标函数与约束条件在最优解处有相同或相反方向的梯度,而在不等式下没有这个条件。不过如果能构造出一种函数,使它在可行解区域内与目标函数一致,在可行解区域外无限大,这个函数就可以等价原最优化问题。下面讲解拉格朗日对偶
(1)原目标函数

(2)新构造的目标函数
构造广义拉格朗日函数作为新的目标函数,注意此时是最大化,优化的自变量是a和b


![\theta_P(\boldsymbol{x})=\max_{\boldsymbol{\alpha},~\boldsymbol{\beta};~\beta_j\geq0}L(\boldsymbol{x},\boldsymbol{\alpha},\boldsymbol{\beta})= f(\boldsymbol{x})+\max_{\boldsymbol{\alpha},~\boldsymbol{\beta};~\beta_j\geq0}\left[ \sum_{i=1}^m\alpha_i h_i(\boldsymbol{x})+\sum_{j=1}^n\beta_j g_j(\boldsymbol{x}) \right]](https://www.zhihu.com/equation?tex=%5Ctheta_P%28%5Cboldsymbol%7Bx%7D%29%3D%5Cmax_%7B%5Cboldsymbol%7B%5Calpha%7D%2C~%5Cboldsymbol%7B%5Cbeta%7D%3B~%5Cbeta_j%5Cgeq0%7DL%28%5Cboldsymbol%7Bx%7D%2C%5Cboldsymbol%7B%5Calpha%7D%2C%5Cboldsymbol%7B%5Cbeta%7D%29%3D+f%28%5Cboldsymbol%7Bx%7D%29%2B%5Cmax_%7B%5Cboldsymbol%7B%5Calpha%7D%2C~%5Cboldsymbol%7B%5Cbeta%7D%3B~%5Cbeta_j%5Cgeq0%7D%5Cleft%5B+%5Csum_%7Bi%3D1%7D%5Em%5Calpha_i+h_i%28%5Cboldsymbol%7Bx%7D%29%2B%5Csum_%7Bj%3D1%7D%5En%5Cbeta_j+g_j%28%5Cboldsymbol%7Bx%7D%29+%5Cright%5D+)
上式的讨论需要分为在可行解区域内和可行解区域外:
可行解区域内:此时满足h(x)=0,并且g(x)<=0,而系数b>=0,所以max最大只能是0
![\max_{\boldsymbol{\alpha},~\boldsymbol{\beta};~\beta_j\geq0}\left[ \sum_{i=1}^m\alpha_i h_i(\boldsymbol{x})+\sum_{j=1}^n\beta_j g_j(\boldsymbol{x}) \right] =0,~\textrm{for}~ \boldsymbol{x}\in\Phi](https://www.zhihu.com/equation?tex=%5Cmax_%7B%5Cboldsymbol%7B%5Calpha%7D%2C~%5Cboldsymbol%7B%5Cbeta%7D%3B~%5Cbeta_j%5Cgeq0%7D%5Cleft%5B+%5Csum_%7Bi%3D1%7D%5Em%5Calpha_i+h_i%28%5Cboldsymbol%7Bx%7D%29%2B%5Csum_%7Bj%3D1%7D%5En%5Cbeta_j+g_j%28%5Cboldsymbol%7Bx%7D%29+%5Cright%5D+%3D0%2C~%5Ctextrm%7Bfor%7D~+%5Cboldsymbol%7Bx%7D%5Cin%5CPhi)
可行解区域外:此时要么 ,要么
,要么 ,都可以使得max的优化结果为正无穷
,都可以使得max的优化结果为正无穷
![\max_{\boldsymbol{\alpha},~\boldsymbol{\beta};~\beta_j\geq0}\left[ \sum_{i=1}^m\alpha_i h_i(\boldsymbol{x})+\sum_{j=1}^n\beta_j g_j(\boldsymbol{x}) \right] =+\infty,~\textrm{for}~ \boldsymbol{x}\notin \Phi](https://www.zhihu.com/equation?tex=%5Cmax_%7B%5Cboldsymbol%7B%5Calpha%7D%2C~%5Cboldsymbol%7B%5Cbeta%7D%3B~%5Cbeta_j%5Cgeq0%7D%5Cleft%5B+%5Csum_%7Bi%3D1%7D%5Em%5Calpha_i+h_i%28%5Cboldsymbol%7Bx%7D%29%2B%5Csum_%7Bj%3D1%7D%5En%5Cbeta_j+g_j%28%5Cboldsymbol%7Bx%7D%29+%5Cright%5D+%3D%2B%5Cinfty%2C~%5Ctextrm%7Bfor%7D~+%5Cboldsymbol%7Bx%7D%5Cnotin+%5CPhi)
所以在x的分布下我们的目标函数为如下:

此时已经没有了约束条件,下面可以求解最优化问题![\min_{\boldsymbol{x}}\left[\theta_P(\boldsymbol{x})\right]](https://www.zhihu.com/equation?tex=%5Cmin_%7B%5Cboldsymbol%7Bx%7D%7D%5Cleft%5B%5Ctheta_P%28%5Cboldsymbol%7Bx%7D%29%5Cright%5D)
(3)对偶问题
上式很难建立 的显示表达式(由于x的取值不同表达不同),所以将其改为对偶形式。我们上面构造的函数如下:
的显示表达式(由于x的取值不同表达不同),所以将其改为对偶形式。我们上面构造的函数如下:
![\min_{\boldsymbol{x}}\left[\theta_P(\boldsymbol{x})\right]= \min_{\boldsymbol{x}}\left[ \max_{\boldsymbol{\alpha},\boldsymbol{\beta}:\beta_j\geq0}L(\boldsymbol{x},\boldsymbol{\alpha},\boldsymbol{\beta}) \right]](https://www.zhihu.com/equation?tex=+%5Cmin_%7B%5Cboldsymbol%7Bx%7D%7D%5Cleft%5B%5Ctheta_P%28%5Cboldsymbol%7Bx%7D%29%5Cright%5D%3D+%5Cmin_%7B%5Cboldsymbol%7Bx%7D%7D%5Cleft%5B+%5Cmax_%7B%5Cboldsymbol%7B%5Calpha%7D%2C%5Cboldsymbol%7B%5Cbeta%7D%3A%5Cbeta_j%5Cgeq0%7DL%28%5Cboldsymbol%7Bx%7D%2C%5Cboldsymbol%7B%5Calpha%7D%2C%5Cboldsymbol%7B%5Cbeta%7D%29+%5Cright%5D)
在构造另一个函数 ,以及它的优化为:
,以及它的优化为:
![\max_{\boldsymbol{\alpha},\boldsymbol{\beta}:\beta_j\geq0}\left[\theta_D(\boldsymbol{\alpha},\boldsymbol{\beta})\right]= \max_{\boldsymbol{\alpha},\boldsymbol{\beta}:\beta_j\geq0} \left[ \min_{\boldsymbol{x}}L(\boldsymbol{x},\boldsymbol{\alpha},\boldsymbol{\beta}) \right]](https://www.zhihu.com/equation?tex=+%5Cmax_%7B%5Cboldsymbol%7B%5Calpha%7D%2C%5Cboldsymbol%7B%5Cbeta%7D%3A%5Cbeta_j%5Cgeq0%7D%5Cleft%5B%5Ctheta_D%28%5Cboldsymbol%7B%5Calpha%7D%2C%5Cboldsymbol%7B%5Cbeta%7D%29%5Cright%5D%3D+%5Cmax_%7B%5Cboldsymbol%7B%5Calpha%7D%2C%5Cboldsymbol%7B%5Cbeta%7D%3A%5Cbeta_j%5Cgeq0%7D+%5Cleft%5B+%5Cmin_%7B%5Cboldsymbol%7Bx%7D%7DL%28%5Cboldsymbol%7Bx%7D%2C%5Cboldsymbol%7B%5Calpha%7D%2C%5Cboldsymbol%7B%5Cbeta%7D%29+%5Cright%5D)
这就是上一节函数的对偶问题,可以证明这两个问题有相同的解。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)