利用chain mapreduce,依次执行两个mapreduce Job。第一个Job抽取donor_city(城市名)、total(捐赠金额)字段,并按照城市名实现捐赠金额聚合,实现数据过滤、聚合;第二个Job,按照捐赠金额排降序。
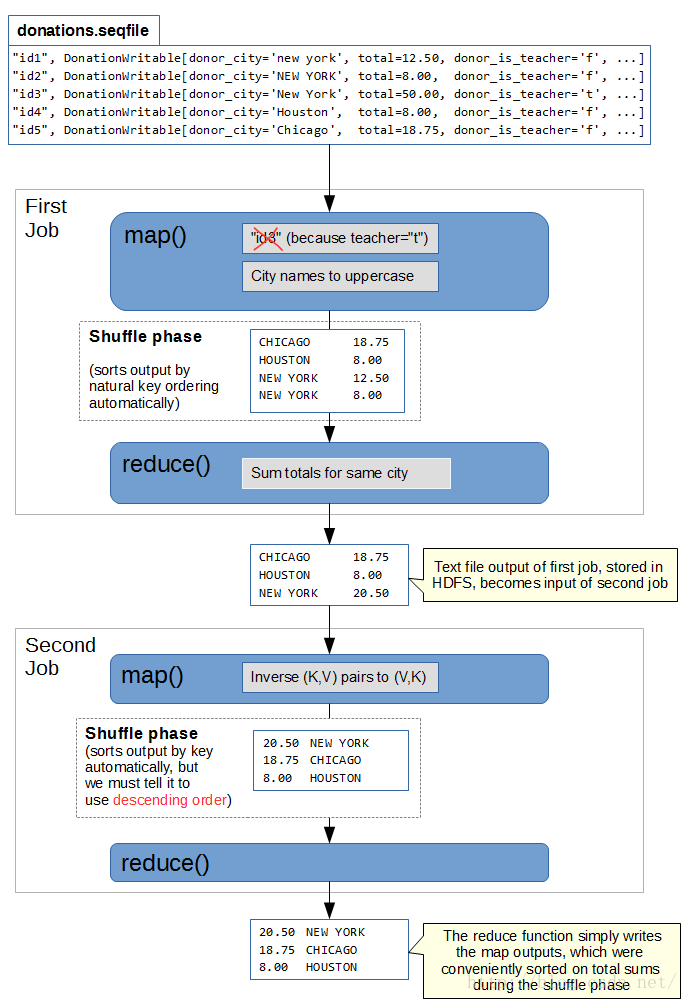
- 第一个Job Mapper:抽取donor_city(城市名)、total(捐赠金额)字段。
- 第一个Job Combiner:按照donor_city,累加该filesplit的total。减少中间数据传送。
- 第一个Job Reducer: 按照donor_city,累加total。输出数据存储为donor_city、total。
- 第二个Job Mapper:读入第一个Job Reducer输出结果,交换key、value,输出total、donor_city。
- 第二个Job Reducer:自定义sortComparator,实现double按照降序排序。经过shuffle排序后,输出排降序的total、donor_city。
注意事项:
1、对内置数据类型,如DoubleWritable,自定义排序顺序时候,可以使用sortComparatorClass()。通过自定义排序类,继承自对应数据类型,实现排序。
2、chain mapreduce,上一个job的输出文件(存放在hdfs),直接作为下一个job的输入文件。
3、对于可能的异常,可以使用Mrunit进行测试。
执行结果:
$ hdfs dfs -cat output/donation-price/p* |head -n 20
3514021.3 New York
2328154.0 San Francisco
815354.1 Seattle
677975.6 Chicago
508308.2 West Berlin
500588.5 Los Angeles
447923.0 Brooklyn
418111.1 Oklahoma City
343251.9 Indianapolis
215072.7 Framingham
209319.9 Springfield
158270.3 Charlotte
153875.1 San Ramon
149707.1 Washington
131766.5 Tulsa
119922.8 Raleigh
115334.9 Houston
108732.2 Baltimore
101028.8 Dallas
==========donation job1==========
User: xuefei
Name: donation-job1
Application Type: MAPREDUCE
Application Tags:
YarnApplicationState: FINISHED
FinalStatus Reported by AM: SUCCEEDED
Started: 星期五 五月 13 09:24:57 +0800 2016
Elapsed: 57sec
Tracking URL: History
Diagnostics:
Map input records=4631337
Map output records=1502321
Map output bytes=27150482
Map output materialized bytes=2375954
Input split bytes=1632
Combine input records=1502321
Combine output records=115926
Reduce input groups=24224
Reduce shuffle bytes=2375954
Reduce input records=115926
Reduce output records=24224 //压缩了80%记录数,减少shuffle数据量
Spilled Records=231852
Shuffled Maps =12 //共12个split,启动12个Map进程
Failed Shuffles=0
Merged Map outputs=12
GC time elapsed (ms)=6325
CPU time spent (ms)=93630
Physical memory (bytes) snapshot=3480043520
Virtual memory (bytes) snapshot=10956181504
Total committed heap usage (bytes)=2666004480
==========donation job2==========
User: xuefei
Name: donation-job2
Application Type: MAPREDUCE
Application Tags:
YarnApplicationState: FINISHED
FinalStatus Reported by AM: SUCCEEDED
Started: 星期五 五月 13 09:25:56 +0800 2016
Elapsed: 21sec
Tracking URL: History
Diagnostics:
Map input records=24224
Map output records=24224
Map output bytes=454936
Map output materialized bytes=503390
Input split bytes=132
Combine input records=0
Combine output records=0
Reduce input groups=5990
Reduce shuffle bytes=503390
Reduce input records=24224
Reduce output records=24224
Spilled Records=48448
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=62
CPU time spent (ms)=4010
Physical memory (bytes) snapshot=451493888
Virtual memory (bytes) snapshot=1703575552
Total committed heap usage (bytes)=402653184
程序代码:
<span style="font-size:14px;"><span style="font-size:18px;"><span style="font-size:14px;">package donation1;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.StringUtils;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import donation1.Donation.Descdouble;
public class Donation extends Configured implements Tool {
//自定义sortComparatorClass,对第二个job实现按照total排降序
public static class Descdouble extends WritableComparator {
public Descdouble() {
super(DoubleWritable.class, true);
// TODO Auto-generated constructor stub
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
// TODO Auto-generated method stub
DoubleWritable lhs=(DoubleWritable)a;
DoubleWritable rhs=(DoubleWritable)b;
return ((rhs.get()-lhs.get())>0)?1:-1;
}
}
public static class Djob2mapper extends
Mapper<LongWritable, Text, DoubleWritable, Text>{
DoubleWritable outputKey=new DoubleWritable();
Text outputValue=new Text();
@Override
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String []words=StringUtils.split(value.toString(), '\t');
outputKey.set(Double.parseDouble(words[1]));
outputValue.set(words[0]);
context.write(outputKey, outputValue);
}
}
public static class Djobreducer1 extends
Reducer<Text, DoubleWritable, Text, DoubleWritable>{
DoubleWritable outputValue=new DoubleWritable();
@Override
protected void reduce(Text key, Iterable<DoubleWritable> values,
Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
double sumtotal=0.0;
for(DoubleWritable value:values){
sumtotal+=value.get();
}
outputValue.set(sumtotal);
context.write(key, outputValue);
}
}
public static class Djobmapper1 extends
Mapper<LongWritable, Text, Text, DoubleWritable> {
Text outputKey=new Text();
DoubleWritable outputValue=new DoubleWritable();
@Override
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
//对输入行按照“,”进行分列
String []words=value.toString().split("\",\"");
if(words[0].equals("_donationid")||words[7].substring(1, 1).equals("t")||words[4].isEmpty() || words[11].isEmpty())
return;
String city=words[4];
String strprice=words[11];
strprice=strprice.substring(1, strprice.length()-1); //删除price末尾的双引号
Double total=Double.parseDouble(strprice);
outputKey.set(city);
outputValue.set(total);
context.write(outputKey, outputValue);
}
}
public int run(String []args) throws Exception{
Job job1=Job.getInstance(getConf(), "donation-job1");
Configuration conf1=job1.getConfiguration();
job1.setJarByClass(getClass());
FileInputFormat.setInputPaths(job1, new Path("data/donation"));
Path out1=new Path("output/donation-city");
out1.getFileSystem(conf1).delete(out1, true);
FileOutputFormat.setOutputPath(job1, out1);
job1.setInputFormatClass(TextInputFormat.class);
job1.setOutputFormatClass(TextOutputFormat.class);
job1.setMapperClass(Djobmapper1.class);
job1.setMapOutputKeyClass(Text.class);
job1.setMapOutputValueClass(DoubleWritable.class);
job1.setCombinerClass(Djobreducer1.class);
job1.setReducerClass(Djobreducer1.class);
job1.setOutputKeyClass(DoubleWritable.class);
job1.setOutputValueClass(Text.class);
//实现chain mapreduce的关键。如果job1能够成功执行,则继续继续后面代码;否则退出。
if(job1.waitForCompletion(true)==false)
return 1;
Job job2=Job.getInstance(getConf(), "donation-job2");
Configuration conf2=job2.getConfiguration();
job2.setJarByClass(getClass());
FileInputFormat.setInputPaths(job2, out1);
Path out2=new Path("output/donation-price");
out2.getFileSystem(conf2).delete(out2, true);
FileOutputFormat.setOutputPath(job2, out2);
job2.setInputFormatClass(TextInputFormat.class);
job2.setOutputFormatClass(TextOutputFormat.class);
job2.setMapperClass(Djob2mapper.class);
job2.setMapOutputKeyClass(DoubleWritable.class);
job2.setMapOutputValueClass(Text.class);
job2.setSortComparatorClass(Descdouble.class);
job2.setReducerClass(Reducer.class);
job2.setOutputKeyClass(DoubleWritable.class);
job2.setOutputValueClass(Text.class);
return job2.waitForCompletion(true)?0:1;
}
public static void main(String []args){
int result=0;
try{
result=ToolRunner.run(new Configuration(), new Donation(), args);
}catch(Exception e){
e.printStackTrace();
}
System.exit(result);
}
}
========Mrunit========
package donation1test;
import java.io.IOException;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mrunit.mapreduce.MapDriver;
import org.junit.Before;
import org.junit.Test;
import donation1.Donation.Djobmapper1;
public class DonationTest {
MapDriver<LongWritable, Text, Text, DoubleWritable> mapdriver;
@Before
public void setup(){
Djobmapper1 djm=new Djobmapper1();
mapdriver=MapDriver.newMapDriver(djm);
}
@Test
public void testMapper() throws IOException{
LongWritable inputKey = new LongWritable(0);
Text inputValue=new Text("\"b1e82d0b63b949927b205441c543f249\",\"8a61c8ab4d91632dbf608ae6b1a832f3\",\"90b8c62c2e07a03d2cae3a0a52f18687\",\"\",\"NEWYORK\",\"NY\",\"100\",\"f\",\"2007-12-21 18:55:13.722\",\"85.00\",\"15.00\",\"100.00\",\"100_and_up\",\"t\",\"no_cash_received\",\"f\",\"t\",\"f\",\"f\",\"f\",\"f\",\"t\",\"\"");
mapdriver.withInput(inputKey, inputValue);
Text outputKey = new Text("NEWYORK");
mapdriver.withOutput(outputKey, new DoubleWritable(0));
mapdriver.runTest();
}
}</span></span></span>