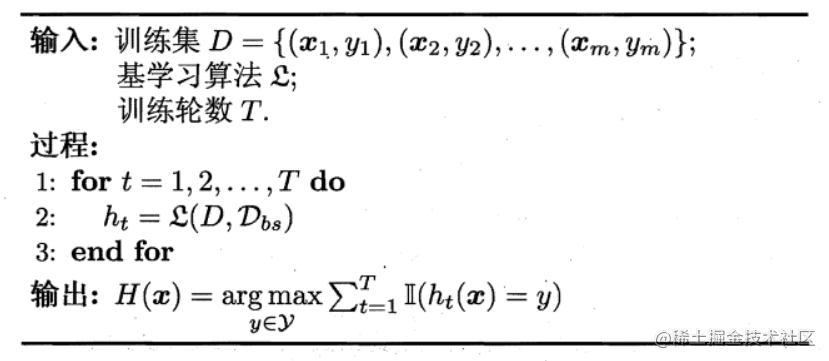简单分析,考虑对于二分类问题
y
∈
{
−
1
,
+
1
}
y\in \{-1,+1\}
y∈{−1,+1}和真实函数
f
f
f,假定基分类器的错误率为
ϵ
\epsilon
ϵ,即对每个基分类器有:
P
(
h
i
(
x
)
≠
f
(
x
)
)
=
ϵ
P(h_i(x)\neq f(x))=\epsilon
P(hi(x)=f(x))=ϵ 假设通过简单投票法结合
T
T
T个基分类器,若有超过半数的基分类器分类正确,则集成分类就正确:
F
(
x
)
=
s
i
g
n
(
∑
i
=
1
T
h
i
(
x
)
)
F(x)=sign(\sum_{i=1}^T h_i(x))
F(x)=sign(i=1∑Thi(x)) 假设基分类器的错误率相互独立,则由Hoeffding不等式有,集成错误率为
P
(
F
(
x
)
≠
f
(
x
)
)
=
∑
k
=
0
[
T
/
2
]
C
T
k
(
1
−
ϵ
)
k
ϵ
T
−
k
≤
e
−
1
2
T
(
1
−
2
ϵ
)
2
P(F(x)\neq f(x)) =\sum_{k=0}^{[T/2]} C_T^k(1-\epsilon)^k\epsilon^{T-k}\\ \le e^ { -\displaystyle\frac{1}{2}T(1-2\epsilon)^2}
P(F(x)=f(x))=k=0∑[T/2]CTk(1−ϵ)kϵT−k≤e−21T(1−2ϵ)2
上式体现出,随着个体分类器数目
T
T
T的增大,集成错误率将指数级下降,最终趋向于0。但我们要注意到假设中基学习器的误差相互独立,在现实任务中,个体学习器是为了解决同一个问题训练出来的,因此显然不会相互独立。所以如何产生并结合“好而不同”的学习器,是集成学习研究的核心。
Boosting算法的工作机制类似:先根据初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复,直到基学习器的数目先到达
T
T
T,最终将
T
T
T个学习器进行加权结合。
Boosting族算法中的代表算法是AdaBoost算法。可以采用“加性模型”,即基学习器的线性组合
H
(
x
)
=
∑
i
=
1
T
α
i
h
t
(
x
)
H(x)=\sum_{i=1}^T \alpha_ih_t(x)
H(x)=i=1∑Tαiht(x) 来最小化指数损失函数:
ϑ
e
x
p
(
H
∣
D
)
=
E
x
∼
D
[
e
−
f
(
x
)
H
(
x
)
]
\vartheta_{exp}(H|D)=E_{x\sim D}[e^{-f(x)H(x)}]
ϑexp(H∣D)=Ex∼D[e−f(x)H(x)] 该损失函数是指,若
f
(
x
)
f(x)
f(x)和
H
(
x
)
H(x)
H(x)的预测结果一致,则其乘积为1,其负数的指数就会越小。
若
H
(
x
)
H(x)
H(x)能使得指数损失函数最小,则对指数损失函数求
H
(
x
)
H(x)
H(x)的偏导:
∂
ϑ
e
x
p
(
H
∣
D
)
∂
H
(
x
)
=
−
e
−
H
(
x
)
P
(
f
(
x
)
=
1
∣
x
)
+
e
H
(
x
)
P
(
f
(
x
)
=
−
1
∣
x
)
\frac{\partial \vartheta_{exp}(H|D)}{\partial H(x)}=-e^{-H(x)}P(f(x)=1|x)+e^{H(x)}P(f(x)=-1|x)
∂H(x)∂ϑexp(H∣D)=−e−H(x)P(f(x)=1∣x)+eH(x)P(f(x)=−1∣x) 令偏导为0可得:
H
(
x
)
=
1
2
ln
P
(
f
(
x
)
=
1
∣
x
)
P
(
f
(
x
)
=
−
1
∣
x
)
H(x)=\frac{1}{2} \ln \frac{P(f(x)=1|x)}{P(f(x)=-1|x)}
H(x)=21lnP(f(x)=−1∣x)P(f(x)=1∣x) 因此有:
s
i
g
n
(
H
(
x
)
)
=
{
1
,
P
(
f
(
x
)
=
1
∣
x
)
>
P
(
f
(
x
)
=
−
1
∣
x
)
−
1
,
P
(
f
(
x
)
=
1
∣
x
)
<
P
(
f
(
x
)
=
−
1
∣
x
)
=
arg
max
y
∈
{
1
,
−
1
}
P
(
f
(
x
)
=
y
∣
x
)
sign(H(x)) = \begin{cases} 1\space \space \space ,P(f(x)=1|x)>P(f(x)=-1|x)\\ -1,P(f(x)=1|x)< P(f(x)=-1|x) \end{cases}\\ \space\space \space \space = \mathop{\arg \max}_{y\in \{1,-1\}}P(f(x)=y|x)
sign(H(x))={1,P(f(x)=1∣x)>P(f(x)=−1∣x)−1,P(f(x)=1∣x)<P(f(x)=−1∣x)=argmaxy∈{1,−1}P(f(x)=y∣x) 这意味着
s
i
g
n
(
H
(
x
)
)
sign(H(x))
sign(H(x))达到了贝叶斯最优错误率。即指数损失函数可以替代原本的0/1损失函数。
再AdaBoost算法中,第一个基分类器
h
1
h_1
h1是直接将基学习算法用于初始数据分布得到的。此后迭代地生产
h
t
h_t
ht和
α
t
\alpha_t
αt,当基分类器
h
t
h_t
ht基于分布
D
t
D_t
Dt产生后,该分类器的权重
α
t
\alpha_t
αt应该使得
α
t
h
t
\alpha_th_t
αtht最小化指数损失函数:
ϑ
e
x
p
(
α
t
h
t
∣
D
t
)
=
E
x
∼
D
t
[
e
−
f
(
x
)
α
t
h
t
(
x
)
]
=
E
x
∼
D
t
[
e
−
α
t
Ⅱ
(
f
(
x
)
=
h
t
(
x
)
)
+
[
e
α
t
Ⅱ
(
f
(
x
)
≠
h
t
(
x
)
)
]
=
e
−
α
t
P
x
∼
D
t
(
f
(
x
)
=
h
t
(
x
)
)
+
e
α
t
P
x
∼
D
t
(
f
(
x
)
≠
h
t
(
x
)
)
=
e
−
α
t
(
1
−
ϵ
t
)
+
e
α
t
ϵ
t
\vartheta_{exp}(\alpha_th_t|D_t) =E_{x\sim D_t}[e^{-f(x)\alpha_t h_t(x)}] =E_{x\sim D_t}[e^{-\alpha_t}Ⅱ(f(x)=h_t(x))+[e^{\alpha_t}Ⅱ(f(x)\neq h_t(x))]\\ =e^{-\alpha_t}P_{x\sim D_t}(f(x)=h_t(x))+e^{\alpha_t}P_{x\sim D_t}(f(x)\neq h_t(x)) =e^{-\alpha_t}(1-\epsilon_t)+e^{\alpha_t}\epsilon_t
ϑexp(αtht∣Dt)=Ex∼Dt[e−f(x)αtht(x)]=Ex∼Dt[e−αtⅡ(f(x)=ht(x))+[eαtⅡ(f(x)=ht(x))]=e−αtPx∼Dt(f(x)=ht(x))+eαtPx∼Dt(f(x)=ht(x))=e−αt(1−ϵt)+eαtϵt
对指数损失函数求导:
∂
ϑ
e
x
p
(
α
t
h
t
∣
D
t
)
∂
α
t
=
−
e
−
α
t
(
1
−
ϵ
t
)
+
e
α
t
ϵ
t
\frac{\partial \vartheta_{exp}(\alpha_th_t|D_t) }{\partial \alpha_t}=-e^{-\alpha_t(1-\epsilon_t)+e^{\alpha_t}\epsilon_t}
∂αt∂ϑexp(αtht∣Dt)=−e−αt(1−ϵt)+eαtϵt 令上式为0,得到权重更新公式:
α
t
=
1
2
ln
(
1
−
ϵ
t
ϵ
t
)
\alpha_t=\frac{1}{2}\ln (\frac{1-\epsilon_t}{\epsilon_t})
αt=21ln(ϵt1−ϵt)
+++
AdaBoost算法在得到
H
t
−
1
H_{t-1}
Ht−1之后样本分布将进行调整,使得下一轮的基学习器
h
t
h_t
ht能够纠正
H
t
−
1
H_{t-1}
Ht−1的一些错误。方法是最小化
ϑ
(
H
t
−
1
+
α
t
h
t
∣
D
)
\vartheta(H_{t-1}+\alpha_th_t|D)
ϑ(Ht−1+αtht∣D),可以简化为:
ϑ
(
H
t
−
1
+
α
t
h
t
∣
D
)
=
E
x
∼
D
[
e
−
f
(
x
)
(
H
t
−
1
(
x
)
+
h
t
(
x
)
)
]
=
E
x
∼
D
[
e
−
f
(
x
)
H
t
−
1
(
x
)
e
−
f
(
x
)
h
t
(
x
)
]
\vartheta(H_{t-1}+\alpha_th_t|D) =E_{x\sim D}[e^{-f(x)(H_{t-1}(x)+h_t(x))}]\\ =E_{x\sim D}[e^{-f(x)H_{t-1}(x)}e^{-f(x)h_t(x)}]
ϑ(Ht−1+αtht∣D)=Ex∼D[e−f(x)(Ht−1(x)+ht(x))]=Ex∼D[e−f(x)Ht−1(x)e−f(x)ht(x)] 注意到
f
2
(
x
)
=
h
t
2
(
x
)
=
1
f^2(x)=h_t^2(x)=1
f2(x)=ht2(x)=1,用
e
−
f
(
x
)
h
t
(
x
)
e^{-f(x)h_t(x)}
e−f(x)ht(x)泰勒展开得到:
ϑ
(
H
t
−
1
+
α
t
h
t
∣
D
)
=
E
x
∼
D
[
e
−
f
(
x
)
H
t
−
1
(
x
)
(
1
−
f
(
x
)
h
t
(
x
)
+
f
2
(
x
)
h
t
2
(
x
)
2
)
]
=
E
x
∼
D
[
e
−
f
(
x
)
H
t
−
1
(
x
)
(
1
−
f
(
x
)
h
t
(
x
)
+
1
2
)
]
\vartheta(H_{t-1}+\alpha_th_t|D) =E_{x\sim D}[e^{-f(x)H_{t-1}(x)}(1-f(x)h_t(x)+\frac{f^2(x)h_t^2(x)}{2})]\\ =E_{x\sim D}[e^{-f(x)H_{t-1}(x)}(1-f(x)h_t(x)+\frac{1}{2})]
ϑ(Ht−1+αtht∣D)=Ex∼D[e−f(x)Ht−1(x)(1−f(x)ht(x)+2f2(x)ht2(x))]=Ex∼D[e−f(x)Ht−1(x)(1−f(x)ht(x)+21)] 于是理想的基学习器
h
t
(
x
)
=
arg
max
h
E
x
∼
D
[
e
−
f
(
x
)
H
t
−
1
(
x
)
E
x
∼
D
[
e
−
f
(
x
)
H
t
−
1
(
x
)
]
f
(
x
)
h
(
x
)
)
]
h_t(x)=\mathop{\arg \max}_{h}\space E_{x\sim D}[\frac{e^{-f(x)H_{t-1}(x)}}{E_{x\sim D}[e^{-f(x)H_{t-1}(x)}]}f(x)h(x))]
ht(x)=argmaxhEx∼D[Ex∼D[e−f(x)Ht−1(x)]e−f(x)Ht−1(x)f(x)h(x))] 令
D
t
D_t
Dt表示一个分布,有
D
t
=
D
(
x
)
e
−
f
(
x
)
H
t
−
1
(
x
)
E
x
∼
D
[
e
−
f
(
x
)
H
t
−
1
(
x
)
]
D
t
+
1
(
x
)
=
D
t
(
x
)
⋅
e
−
f
(
x
)
α
t
h
t
(
x
)
E
x
∼
D
[
e
−
f
(
x
)
H
t
−
1
(
x
)
]
E
x
∼
D
[
e
−
f
(
x
)
H
t
(
x
)
]
D_t=\frac{D(x)e^{-f(x)H_{t-1}(x)}}{E_{x\sim D}[e^{-f(x)H_{t-1}(x)}]}\\ \\ D_{t+1}(x)=D_t(x) \cdot e^{-f(x)\alpha_th_t(x)}\frac{E_{x\sim D}[e^{-f(x)H_{t-1}(x)}]}{E_{x\sim D}[e^{-f(x)H_t(x)}]}
Dt=Ex∼D[e−f(x)Ht−1(x)]D(x)e−f(x)Ht−1(x)Dt+1(x)=Dt(x)⋅e−f(x)αtht(x)Ex∼D[e−f(x)Ht(x)]Ex∼D[e−f(x)Ht−1(x)] 理想的
h
t
h_t
ht将在分布
D
t
D_t
Dt下最小化分类误差。因此弱分类器将基于分布
D
t
D_t
Dt来训练。且针对
D
t
D_t
Dt的分类误差应该小于0.5。
按照该方法,我们可以采样出
T
T
T个含有
m
m
m个训练样本的采样集,基于每个采样集训练出一个基学习器。Bagging往往采用 简单投票法(分类)/简单平均法(回归) 对多个基学习器的结果进行决策。从偏差-方差分解的角度看,Bagging主要关注降低方差,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效用更为明显。
具体来说,就是传统决策书在选择划分属性时是根据当前结点的属性集合中选择一个最优属性;在随机森林中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含
k
k
k个属性的子集,再从这个子集中选择一个最优属性进行划分。这里的参数
k
k
k控制了随机性的引入程度。一般情况,推荐
k
=
log
2
d
k=\log_2d
k=log2d。
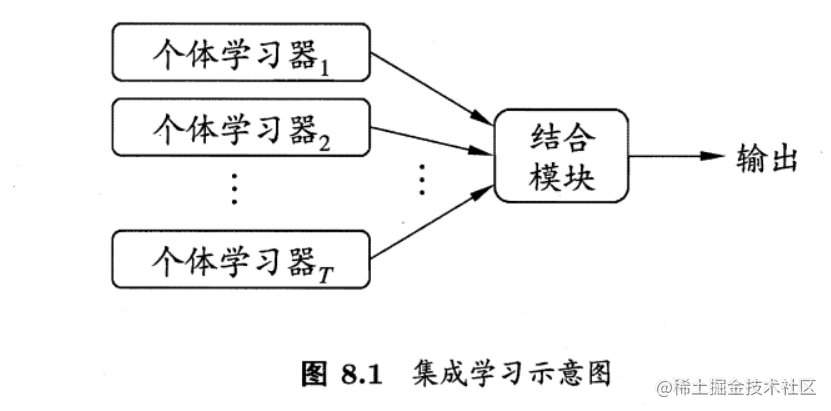
假定集成包含
T
T
T个学习器
{
h
1
,
h
2
,
…
,
h
T
}
\{h_1,h_2,…,h_T\}
{h1,h2,…,hT},其中
h
i
h_i
hi在示例
x
x
x上的输出为
h
i
(
x
)
h_i(x)
hi(x)。
4.1 平均法
简单平均法:
H
(
x
)
=
1
T
∑
i
=
1
T
h
i
(
x
)
H(x)=\frac{1}{T}\sum_{i=1}^Th_i(x)
H(x)=T1i=1∑Thi(x) 加权平均法:
H
(
x
)
=
∑
i
=
1
T
w
i
h
i
(
x
)
H(x)=\sum_{i=1}^T w_ih_i(x)
H(x)=i=1∑Twihi(x)
有研究表明,采用初基学习器的输出类概率作为茨基学习器的输入属性,用多响应线性回归(Multi-response Linear Regression, MLR)作为次级学习算法的效果较好。
5 多样性
5.1 误差-分歧分解
假定我们用个体学习器
h
1
,
h
2
,
…
,
h
T
h_1,h_2,…,h_T
h1,h2,…,hT通过加权平均法结合产生的集成完成回归学习任务
f
:
R
d
↦
R
f:R^d\mapsto R
f:Rd↦R,对示例
x
x
x,定义学习器
h
i
h_i
hi的**“分歧”**为:
A
(
h
i
∣
x
)
=
(
h
i
(
x
)
−
H
(
x
)
)
2
A(h_i|x)=(h_i(x)-H(x))^2
A(hi∣x)=(hi(x)−H(x))2
分歧表示的是个体学习器在样本
x
x
x上的不一致性,即在一定程度上反映了个体学习器的多样性。个体学习器和集成的平方误差分别为:
E
(
h
i
∣
x
)
=
(
f
(
x
)
−
h
i
(
x
)
)
2
E
(
H
∣
x
)
=
(
f
(
x
)
−
H
(
x
)
)
2
E(h_i|x)=(f(x)-h_i(x))^2\\ E(H|x)=(f(x)-H(x))^2
E(hi∣x)=(f(x)−hi(x))2E(H∣x)=(f(x)−H(x))2 令
E
ˉ
(
h
∣
x
)
=
∑
i
=
1
T
w
i
E
(
h
i
∣
x
)
\bar E(h|x)=\sum_{i=1}^Tw_iE(h_i|x)
Eˉ(h∣x)=∑i=1TwiE(hi∣x)表示个体学习器误差的加权均值,有 $$
令
p
(
x
)
p(x)
p(x)表示样本的概率密度,则在全样本上有
∑
i
=
1
T
w
i
∫
A
(
h
i
∣
x
)
p
(
x
)
d
x
=
∑
i
=
1
T
w
i
∫
E
(
h
i
∣
x
)
p
(
x
)
d
x
−
∫
E
(
H
∣
x
)
p
(
x
)
d
x
\sum_{i=1}^Tw_i\int A(h_i|x)p(x)dx=\sum_{i=1}^Tw_i\int E(h_i|x)p(x)dx- \int E(H|x)p(x)dx
i=1∑Twi∫A(hi∣x)p(x)dx=i=1∑Twi∫E(hi∣x)p(x)dx−∫E(H∣x)p(x)dx 类似的,个体学习器在全样本上的泛化误差和分歧项分别为:
E
i
=
∫
E
(
h
i
∣
x
)
p
(
x
)
d
x
A
i
=
∫
A
(
h
i
∣
x
)
p
(
x
)
d
x
E_i=\int E(h_i|x)p(x)dx\\ A_i=\int A(h_i|x)p(x)dx
Ei=∫E(hi∣x)p(x)dxAi=∫A(hi∣x)p(x)dx 集成的泛化误差为
E
=
∫
E
(
H
∣
x
)
p
(
x
)
d
x
E=\int E(H|x)p(x)dx
E=∫E(H∣x)p(x)dx 令
E
ˉ
=
∑
i
=
1
T
w
i
E
i
,
A
ˉ
=
∑
i
=
1
T
w
i
A
i
\bar E=\sum_{i=1}^Tw_iE_i,\space\space \bar A=\sum_{i=1}^Tw_iA_i
Eˉ=∑i=1TwiEi,Aˉ=∑i=1TwiAi表示个体学习器的加权分歧值,有
E
=
E
ˉ
−
A
ˉ
E=\bar E-\bar A
E=Eˉ−Aˉ 该式表示:个体学习器的准确性越高,多样性越大,则集成越好。但我们很难直接通过“误差-分歧分解”来优化目标,因为
A
ˉ
\bar A
Aˉ不是一个可直接操作的多样性度量,尽在集成构造好之后才进行估计。且上面的推导只适用回归,不适用分类。
给定数据集
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
…
,
(
x
m
,
y
m
)
}
D=\{(x_1,y_1),(x_2,y_2),…,(x_m,y_m)\}
D={(x1,y1),(x2,y2),…,(xm,ym)},对二分类任务,
y
i
∈
{
+
1
,
−
1
}
y_i\in \{+1,-1\}
yi∈{+1,−1},分类器
h
i
h_i
hi和
h
j
h_j
hj的预测结果列联表为:
h
i
=
+
1
h_i=+1
hi=+1
h
i
=
−
1
h_i=-1
hi=−1
h
j
h_j
hj=+1
a
a
a
c
c
c
h
j
=
−
1
h_j=-1
hj=−1
b
b
b
d
d
d
其中,
a
a
a表示两个分类器预测结果均为+1的样本数目,且
a
+
b
+
c
+
d
=
m
a+b+c+d=m
a+b+c+d=m,常用的多样性度量:
不合度量:
d
i
s
i
j
=
b
+
c
m
dis_{_ij}=\frac{b+c}{m}
disij=mb+c
相关系数:
ρ
i
j
=
a
d
−
b
c
(
a
+
b
)
(
a
+
c
)
(
c
+
d
)
(
b
+
d
)
\rho_{_ij}=\frac{ad-bc}{\sqrt{(a+b)(a+c)(c+d)(b+d)}}
ρij=(a+b)(a+c)(c+d)(b+d)ad−bc
Q-统计量:
Q
i
j
=
a
d
−
b
c
a
d
+
b
c
Q_{_ij}=\frac{ad-bc}{ad+bc}
Qij=ad+bcad−bc
κ
\kappa
κ-统计量:
p
1
p_1
p1是分类器取得一致的概率,
p
2
p_2
p2是分类器偶然达成一致的概率。
κ
=
p
1
−
p
2
1
−
p
2
p
1
=
a
+
d
m
p
2
=
(
a
+
b
)
(
a
+
c
)
+
(
c
+
d
)
(
b
+
d
)
m
2
\kappa=\frac{p_1-p_2}{1-p_2}\\ p_1=\frac{a+d}{m}\\ p_2=\frac{(a+b)(a+c)+(c+d)(b+d)}{m^2}
κ=1−p2p1−p2p1=ma+dp2=m2(a+b)(a+c)+(c+d)(b+d)