论文链接
github
Abstract
1. Introduction
CNN能保留位置信息,但经过用于分类的全连接神经网络时会丢失位置信息。最近的NIN和GoogLeNet使用全卷积网络、避免使用全连接层,来减少参数量的同时保持模型高性能。

在ILSVRC benchmark的弱监督定位方法上,本文模型的错误率接近AlexNet
1.1. Related Work
图像分类任务可以衍生到目标定位上,介绍了本文相关工作的两条主线
Weakly-supervised object localization(有关CNNs的弱监督物体监督能力的研究)
前人研究的不足包括没有端到端的训练,一个网络需要用多个前向传递来定位物体,使其很难应用于真实世界的数据集。但本文进行了端到端的训练并用一个前向传递来定位。
和本文工作最接近的前人工作是Oquab等人的工作。不过Oquab用的是全局最大池化(GMP),也就是说他们的结果只能在图像中定位到目标物体的边缘点而不是内部区域;而本文用的是全局平均池化(GAP),可以定位目标物体的全部区域,此外作者还用CAM(class activation maps)热力图进行物体标注。作者在此特地申明了,GAP不是本文提出来的,是NIN提出来的。
Visualizing CNN(有关可视化CNNs学习到的内部特征以便更好地理解其特性的研究)
前人的不足:只分析了卷积层,忽视了全连接层。本文将全连接层换为GAP层来进行网络的从头到尾的可解释性分析。
还有人对CNNs的语义编码(visual encoding)进行了分析,但是他们只展示了深度特征里的信息,没有分析该信息的相对重要性,也没办法提取图中重要区域。
2. Class Activation Mapping
Fig2介绍了在CNNs中使用GAP来生成CAM(class activation maps)的流程:

f
k
(
x
,
y
)
,
f
k
为最后一层卷积层输出的
f
e
a
t
u
r
e
m
a
p
中,第
k
个
c
h
a
n
n
e
l
上
(
x
,
y
)
的激活值
f_k\left( x,y \right) ,f_k为最后一层卷积层输出的feature map中,第k个channel上(x,y)的激活值
fk(x,y),fk为最后一层卷积层输出的featuremap中,第k个channel上(x,y)的激活值
F
k
=
∑
x
,
y
f
k
(
x
,
y
)
,
F
k
为
c
h
a
n
n
e
l
k
的
G
A
P
值
F^k=\sum_{x,y}{f_k\left( x,y \right)},F^k为channel \ k的GAP值
Fk=x,y∑fk(x,y),Fk为channel k的GAP值
w
k
c
为单位
k
对应类别
c
的权重,从本质上讲,
w
k
c
表示
F
k
对类
C
的重要性,间接反映了
c
h
a
n
n
e
l
k
对类别
C
的贡献
w_{k}^{c}为单位k对应类别c的权重,从本质上讲,w_{k}^{c}表示F^k对类C的重要性,间接反映了channel \ k对类别C的贡献
wkc为单位k对应类别c的权重,从本质上讲,wkc表示Fk对类C的重要性,间接反映了channel k对类别C的贡献
M
c
(
x
,
y
)
=
∑
k
w
k
c
f
k
(
x
,
y
)
,
M
c
为类别
C
的
C
A
M
,为矩阵
M_c\left( x,y \right) =\sum_k{w_{k}^{c}f_k\left( x,y \right)},M_c为类别C的CAM,为矩阵
Mc(x,y)=k∑wkcfk(x,y),Mc为类别C的CAM,为矩阵
S
c
=
∑
x
,
y
w
k
c
F
k
=
∑
x
,
y
∑
k
w
k
c
f
k
(
x
,
y
)
=
∑
x
,
y
M
c
(
x
,
y
)
,
S
c
为类别
C
的在
s
o
f
t
m
a
x
上的输入值,即类别
C
的线性分类
l
o
g
i
t
值,为标量
S_c=\sum_{x,y}{w_{k}^{c}F_k}=\sum_{x,y}{\sum_k{w_{k}^{c}f_k\left( x,y \right) =\sum_{x,y}{M_c\left( x,y \right)}}},S_c为类别C的在softmax上的输入值,即类别C的线性分类logit值,为标量
Sc=x,y∑wkcFk=x,y∑k∑wkcfk(x,y)=x,y∑Mc(x,y),Sc为类别C的在softmax上的输入值,即类别C的线性分类logit值,为标量
P
c
=
exp
(
S
c
)
∑
c
exp
(
S
c
)
,
P
c
为类别
C
的
s
o
f
t
m
a
x
输出值
P_c=\frac{\exp \left( S_c \right)}{\sum_c{\exp \left( S_c \right)}},P_c为类别C的softmax输出值
Pc=∑cexp(Sc)exp(Sc),Pc为类别C的softmax输出值
这里b站同济子豪兄对各层参数有详细分析
此处忽略了偏置项,即将softmax的输入偏置项设为0,使其对于最终的分类结果没有没有影响。
每个feature map(一个channel产生一个feature map)代表了一个卷积核从图像中提取出的一类视觉特征,而
w
k
c
w_{k}^{c}
wkc间接反映了该特征对于类别C的重要程度。将CAM上采样至原图尺寸即可识别到和特定类最相关的图像区域了。
Fig3为CAMs的例子,不同类别的discriminative region可以被定位。

Fig4展示了即使是同一张图片,在进行不同分类时,定位出来的discriminative region也是不一样的

Global average pooling (GAP) vs global max pooling (GMP):
GAP:关键区域范围内的特征都有影响,也就是更关注区域
GMP:只关注最大值,非最大值的特征怎么变化都没用(因为无梯度)
两者的分类性能接近,但是定位性能不同,明显GAP的定位性能更好
3. Weakly-supervised Object Localization
评估在ILSVRC 2014 benchmark的dataset上训练出来的CAM的定位能力
3.1. Setup
在AlexNet、VGGNet和GoogLeNet上使用CAM,并且用后跟全连接softmax层的GAP替换全连接层。需要注意的是,移除全连接层会大幅度减少网络参数量(比如说VGGNet的参数量减少了90%),而且也会带来分类性能的下降。
如下,映射分辨率mapping resolution的定义,和AlexNet-GAP,VGGnet-GAP和GoogLeNet-GAP的结构和训练

- 分类:AlexNet-GAP,VGGnet-GAP和GoogLeNet-GAP和原始AlexNet,VGGnet和GoogLeNet做对比。在ILSVRC验证集上进行评估。
- 定位:AlexNet-GAP,VGGnet-GAP和GoogLeNet-GAP和原始GoogLeNet,NIN做对比并使用back propagation而不是用CAMs。在验证集和训练集上进行评估。
本文模型的定位和分类评估方法都是使用和ILSVRC一样的top-1和top-5的error metrics。
3.2. Results
先汇报了分类结果,以说明本文方法并不会大幅减损模型的分类性能;再展示了本文方法在弱监督物体定位的高效性。
Classification

可以看到,模型错误率普遍提升1-2%,而且AlexNet受影响最大,而AlexNet*-GAP(在GAP之前加了两层卷积层)要比原始AlexNet表现性能更好。
如预期,GoogLeNet-GAP和GoogLeNet-GMP在分类上的性能相近
Localization
本文通过简单的threshold技术来分割热力图,来用CAMs来生成bounding box(也就是定位框);
第一次分割区域取值为大于最大值20%
Table 2为在测试集上测试各模型的top-1和top-5错误率

如图,GoogLeNet-GAP的错误率比GoogLeNet,基于反向传播的GoogLeNet和GoogLeNet-GMP要低
Fig5 为输出示例

Fig6 为定位框输出对比

Table 3为各模型在验证集上的top-5错误率

4. Deep Features for Generic Localization
作者将本文方法与以下SUN397、MIT Indoor67等场景和物体分类方法进行对比
Table5 展示了作者抽取的时本文表征最好的网络特征进行比较,AlextNet的f7、GoogLeNet的ave pool和GoogLeNet-GAP 的gap

可见GoogLeNet-GAP和GoogLeNet表现比AlexNet好
而在网络层数更少的情况下,GoogLeNet-GAP的表现优于GoogLeNet
总的来说,作者发现GoogLeNet-GAP与当今sota方法相比仍具有竞争力
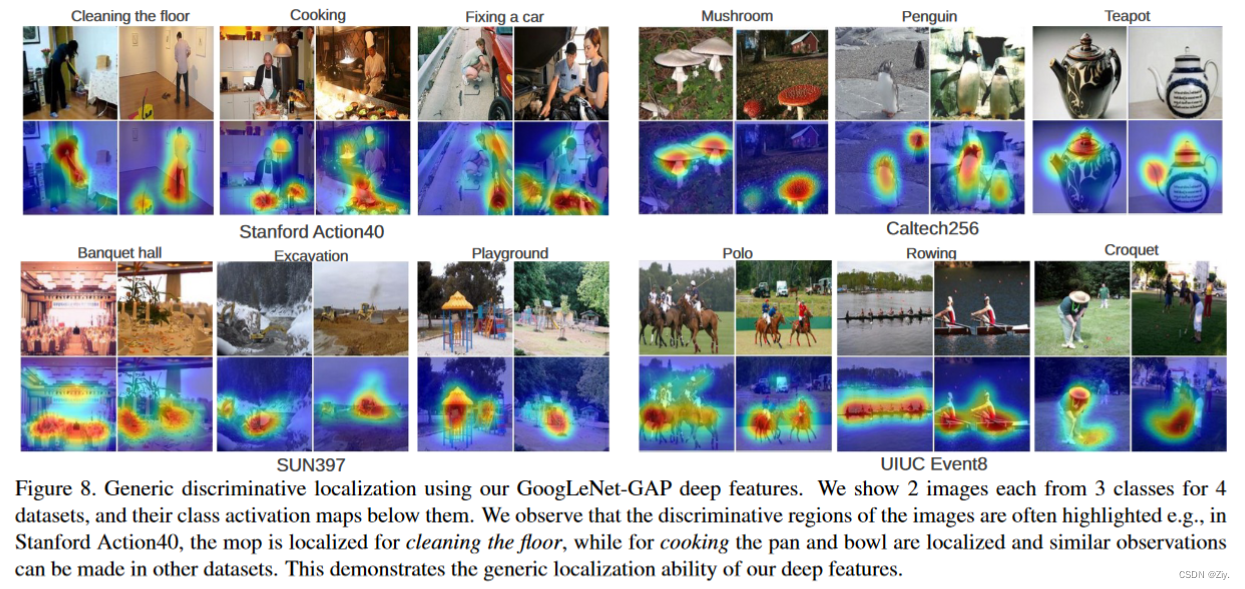
此外,作者还想知道GoogLeNet-GAP使用CAM技术生成的定位图是否在场景中是带有有效信息的。
Fig8 展示了各数据集的一些定位图示例,作者发现模型泛化较好,最具区分力的区域在所有数据集上都被高亮了出来,也就是说本文方法在generic task的生成可定位的深度特征时是有效的。
4.1. Fine-grained Recognition(细粒度图像分类)
CUB-200-2011数据集用于识别200种类的鸟,作者使用此数据集是因为其中包含的定位框标注可用于评估本文模型的定位能力。
Table4 为评估结果

其中Train/Test Anno.项中的n/a表示train和test数据集中皆没有定位框标注,BBox表示皆有定位框标注
可以看到没有任何定位框标注,且训练集和测试集使用整张图像时,GoogLeNet-GAP精确度可达到63%,当使用定位框标注时准确度升至70.5%
考虑到模型的定位能力,作者使用了3.2的从CAM使用threshhold生成定位框方法来先在测试集和训练集中生成鸟的定位框,再使用GoogLeNet-GAP来从裁剪后的定位框里提取特征进行训练测试。作者发现这种细粒化方法能够将无定位框标注的分类结果从63%提升至67.8%,这种方法也能高亮出区分不同类别物体的特征(如鹈鹕和其他鸟类最不同的特征为鹈鹕的嘴巴)。
此外,作者发现,GoogLeNet-GAP 能够在 0.5 联合交集 (IoU) 标准下准确定位 41.0% 的图像中的鸟类,而随机模型性能为 5.5%,Figure7 为一些可视化示例

4.2. Pattern Discovery(概念语义发现)
作者在GoogLeNet-GAP的GAP层上训练了一个线性SVM并且使用CAM技术来识别重要区域。之后使用提取出来的深层特征进行三个模式识别实验
Discovering informative objects in the scenes(场景中发现关键物体)
从SUN(场景标注+目标检测)数据集中取出10个场景类图片组成全标注图像数据集,作者在每个场景类上训练了one vs all 线性SVM并使用该线性SVM权重计算了CAMs
Fig9 中绘制了预测场景类的CAM并列举了和两个场景类的最高CAM激活区域重叠频率最多的top 6物体,作者发现最高激活区域往往对应着表示特定场景类别的对象

Concept localization in weakly labeled images(弱监督定位短语概念)
使用hard-negative mining algorithm,作者学习了concept detector并且使用CAM来定位图像中的concept
Fig10 可视化了两个concept detector案例

Weakly supervised text detector(弱监督文字检测器)
使用的包含SVT数据集文本的350 Google StreetView图像数据集作为positive set,并从SUN数据集中户外场景图像随机取样组成negative set。
虽然是分类模型,但是本文方法没有使用定位框标注而能准确高亮文本

Interpreting visual question answering(VQA视觉问答)
本文方法能在图像中高亮预测答案的相关区域

5. Visualizing Class-Specific Units

每一行:每个类别找出ranked softmax weighed最大的三个channel
每一列:再找到该channel中高激活值在原图的区域(感受野)
结论:不同channel提取不同特征,但都对应特定类别的相关语义
比如在living room类别中,第一行提取出的是沙发,第二行提取出的是餐桌,第三行提取出的是壁炉(还是电视??),即模型将这三个特征重要性排序为沙发>餐桌>壁炉
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)