什么是时序数据库
时序数据库-为万物互联插上一双翅膀 – 有态度的HBase/Spark/BigData
总体介绍
Apache IoTDB 始于清华大学软件学院,是一款时序数据库。主要使用场景是在物联网相关行业,如:车联网、风力发电、地铁、飞机监控等等,具体应用案例及公司详情可以查看:IoTDB在实际公司中的使用信息收集。它采用了列式存储、数据编码、预计算和索引技术,具有类 SQL 的接口,可支持每秒每节点写入数百万数据点,可以秒级获得超过数万亿个数据点的查询结果。它还可以很容易地与 Apache Hadoop、MapReduce 和 Apache Spark 集成以进行分析。
物联网数据采集的特点
物联网的特点是都会存在一个或多个设备,他们以各种各样的形式组织到一起,用来观测或记录同一时间里相同环境所产生的数据。
Apache IoTDB 的前世今生
2012年,三一重工在实际业务中,20 万设备保存了 3 年的数据,TB级别的数据使得 Oracle 被拖的根本吃不消。关键的问题点还不仅仅是存量数据大,新增数据依然以非常快的速度在增长。后来公司联系到了 IoTDB 的第一批开发者,但是当时的方案还是基于 Cassandra 来做设计,当时规划了 5 台机器的集群,性能刚满足,但随着时间推移设备总量在增加,业务系统的查询请求量在增加。
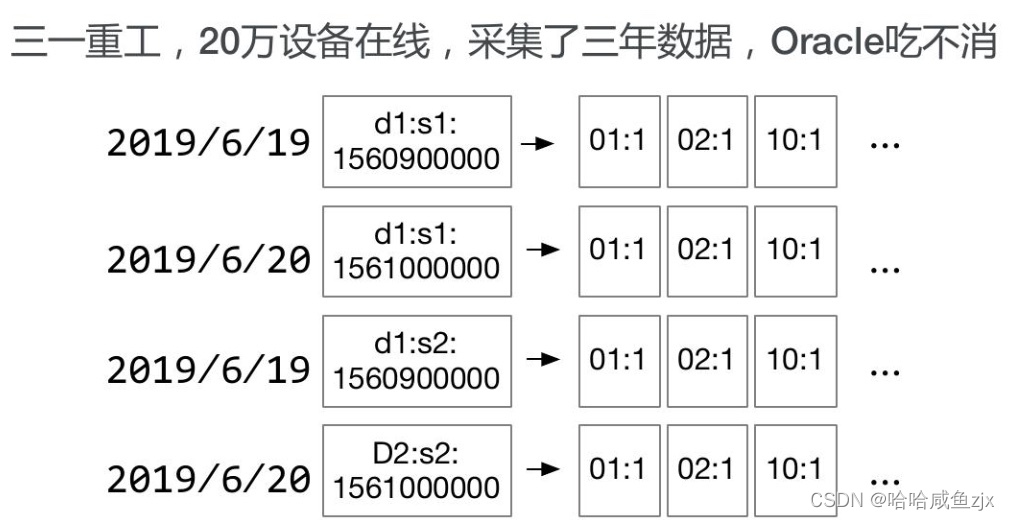
2015年,开始基于Cassandra研发分布式时序数据库,但由于并非完全自研,有点受制于人,而且Cassandra 在经过大量的努力之后,最后发现如果再改可能就需要大面积的重构 Cassandra 数据的代码了,最终决定重新设计一个存储方式,来解决物联网场景下的时序数据高效写入、低延迟读取、高压缩比持久化。IoTDB项目开始诞生,走向了自主研发的道路。后来将IoTDB项目捐献给Apache基金会项目进行孵化,后来毕业,才发展成现在的Apache IoTDB。
系统架构
IoTDB 套件由若干个组件构成,共同形成“数据收集-数据写入-数据存储-数据查询-数据可视化-数据分析”等一系列功能。如下图展示了使用 IoTDB 套件全部组件后形成的整体应用架构。下文称所有组件形成 IoTDB 套件,而 IoTDB 特指其中的时间序列数据库组件。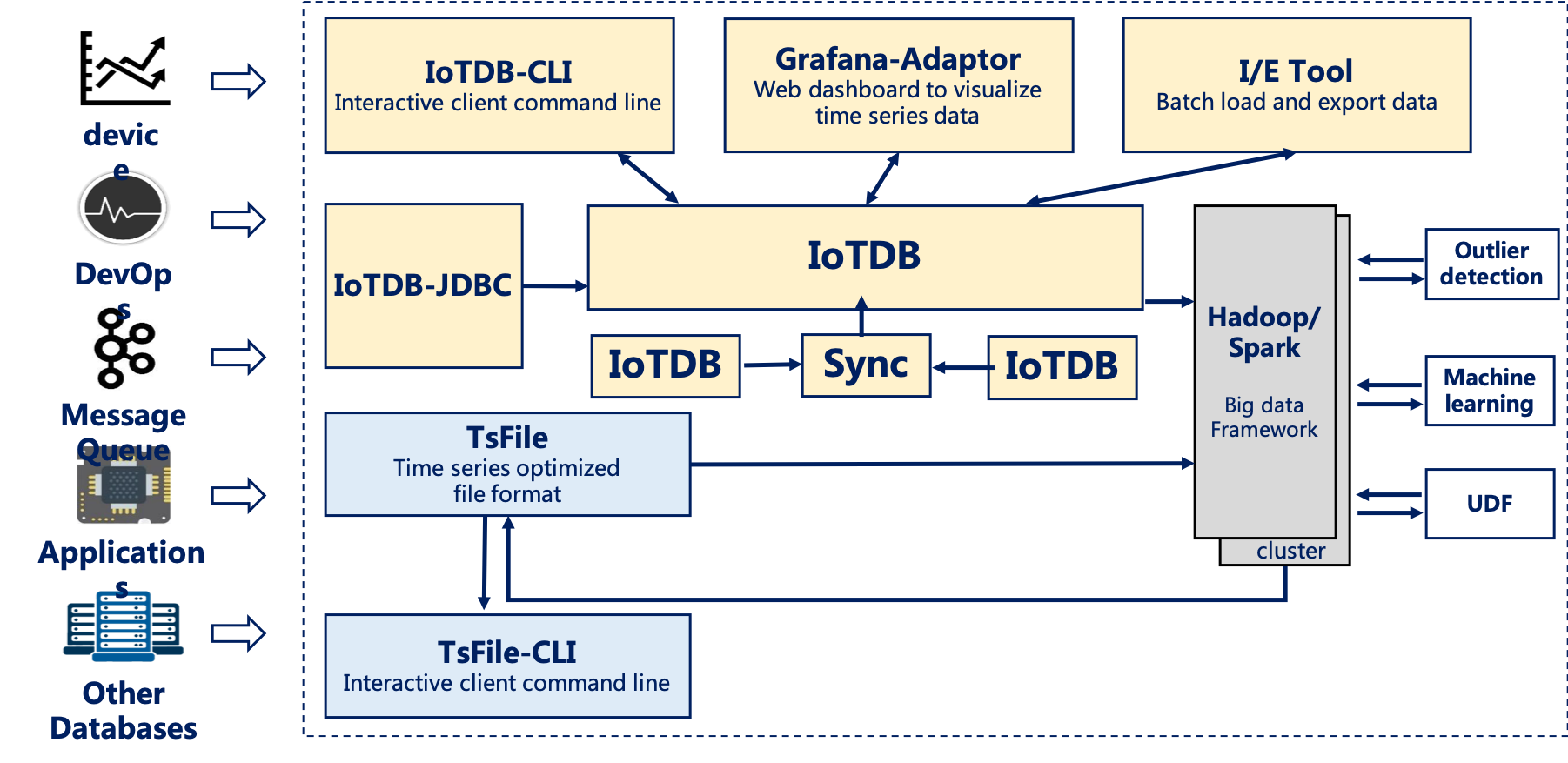
在上图中,用户可以通过 JDBC 将来自设备上传感器采集的时序数据、服务器负载和 CPU 内存等系统状态数据、消息队列中的时序数据、应用程序的时序数据或者其他数据库中的时序数据导入到本地或者远程的 IoTDB 中。用户还可以将上述数据直接写成本地(或位于 HDFS 上)的 TsFile 文件。
可以将 TsFile 文件写入到 HDFS 上,进而实现在 Hadoop 或 Spark 的数据处理平台上的诸如异常检测、机器学习等数据处理任务。
对于写入到 HDFS 或者本地的 TsFile 文件,可以利用 TsFile-Hadoop 或 TsFile-Spark 连接器允许 Hadoop 或 Spark 进行数据处理。
对于分析的结果,可以写回成 TsFile 文件。
IoTDB 和 TsFile 还提供了相应的客户端工具,满足用户查看和写入数据的 SQL 形式、脚本形式和图形化形式等多种需求
性能对比
测试工具使用的是由清华大学大数据实验室开发的
1.写入性能对比
| 数据集2 | 客户端 | 存储组 | 设备 | 变量 | batchsize | LOOP | 数据量 | 写入速度(point/s) | 硬盘数据大小 |
| IoTDB | 10 | 10 | 10 | 10 | 1000 | 1000000 | 1.00E+11 | 24750321.93 | 38306092 |
| InfluxDB | 10 | 10 | 10 | 10 | 1000 | 1000000 | 1.00E+11 | | 304682932 |
| TimescaleDB | 10 | 10 | 10 | 10 | 1000 | 1000000 | 1.00E+11 | 737689.22 | 1610219064 |
| 数据集1 | 客户端 | 存储组 | 设备 | 变量 | batchsize | LOOP | 数据量 | 写入速度(point/s) | 硬盘数据大小 |
| IoTDB | 10 | 10 | 10 | 10 | 1000 | 100000 | 10000000000 | 20706345.15 | 3599732 |
| InfluxDB | 10 | 10 | 10 | 10 | 1000 | 100000 | 10000000000 | 1729907.81 | 30546560 |
| TimescaleDB | 10 | 10 | 10 | 10 | 1000 | 100000 | 10000000000 | 715857 | 161026468 |
| KairosDB | 10 | 10 | 10 | 10 | 10000 | 10000 | 10000000000 | 24924.97 | 76263380 |
上面一组数据可以看出写入性能高于同款数据库10倍有余,单机写入速度高达到每秒2千万。且硬盘占用是最小的,这在数据比较大的线上业务中,可能每个月会差出来1到2块硬盘。
2. 查询性能对比
原始数据查询
| 客户端 | 存储组 | 设备 | 序列-数据量 | 变量 | 查询点数 | LOOP | 速度(point/s) | AVG | MIN |
| IoTDB | 10 | 10 | 10 | 1.00E+09 | 1 | 1000000 | 100 | 12942984.85 | 740.27 | 457.04 |
| InfluxDB | 10 | 10 | 10 | 1.00E+09 | 1 | 1000000 | 100 | 1779606.4 | 5591 | 4666.39 |
| TimescaleDB | 10 | 10 | 10 | 1.00E+09 | 1 | 1000000 | 100 | 3781467.52 | 2345.69 | 1193.78 |
聚合数据查询
| 客户端 | 存储组 | 设备 | 序列-数据量 | 变量 | LOOP | 范围 | 速度(point/s) | AVG | MIN |
| IoTDB-1 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.0001 | 49.75 | 27.87 | 18.03 |
| IoTDB-2 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.001 | 49.75 | 49.14 | 19.87 |
| IoTDB-3 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.01 | 49.76 | 48.69 | 22.32 |
| IoTDB-4 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.1 | 48.68 | 99.14 | 25.56 |
| IoTDB-5 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 1 | 14 | 595.61 | 45.54 |
| InfluxDB-1 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.0001 | 234.32 | 40.28 | 21.63 |
| InfluxDB-2 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.001 | 28.88 | 341.9 | 238.1 |
| InfluxDB-3 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.01 | 3.07 | 3226.87 | 2664.86 |
| TimescaleDB-1 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.0001 | 42.39 | 220.57 | 120.5 |
| TimescaleDB-2 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.001 | 5.8 | 1502.9 | 754.15 |
| TimescaleDB-3 | 10 | 10 | 10 | 1.00E+09 | 1 | 100 | 0.01 | 1.02 | 9711.55 | 7148.69 |
3. 对比图
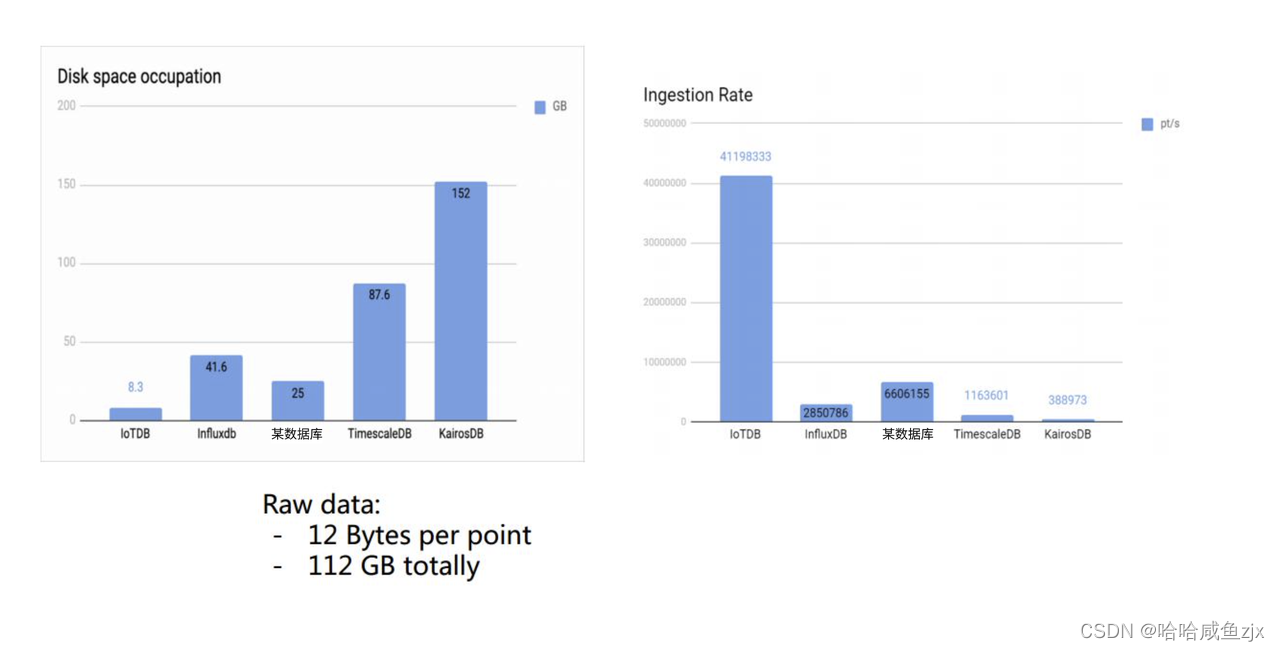
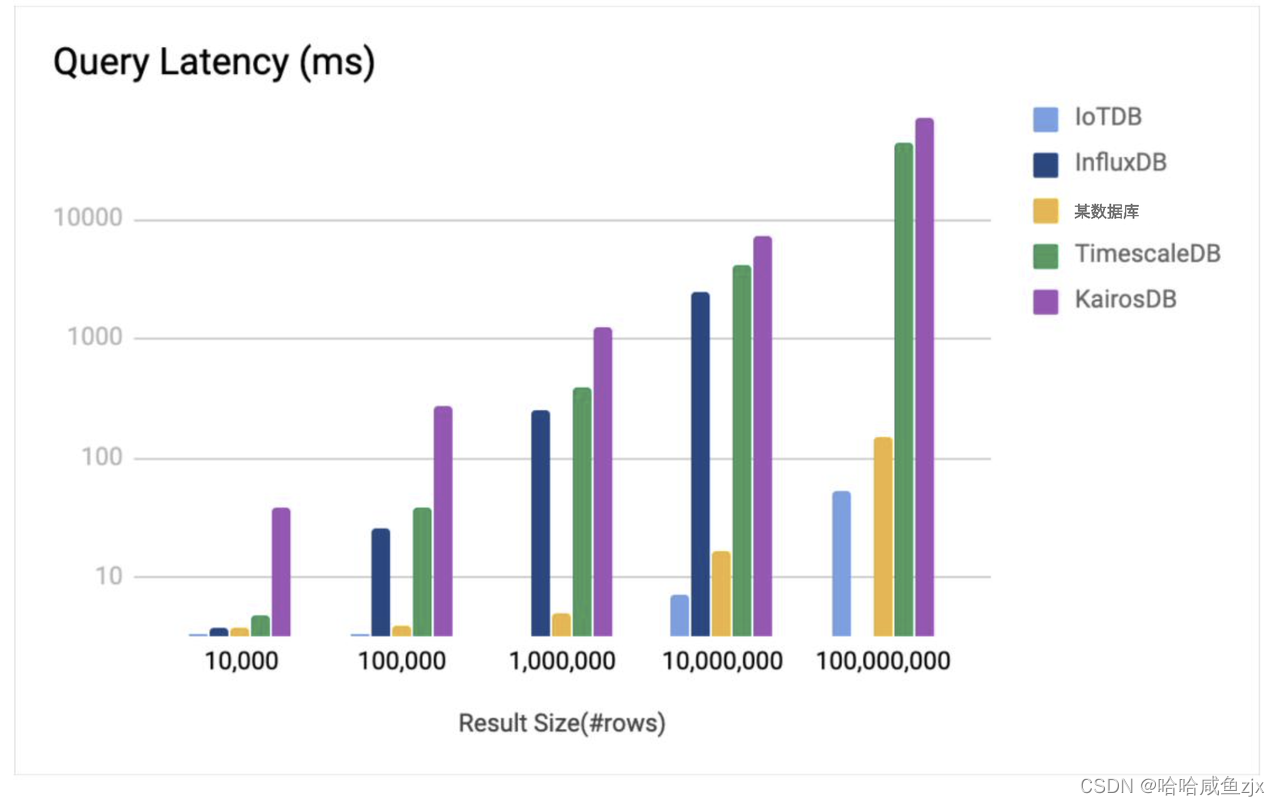 整体来看
整体来看 IoTDB 无论在写入、原始数据查询还是聚合查询,都几乎是10倍的性能于竞品数据库,而且硬盘占用又小于同款数据库10倍。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)