学习基于hadoop2.5.2版本
WordCount做为hadoop的hello world程序,今天花了半天时间,终于跑出了结果,以下记录过程:
1.建立maven工程,加载hadoop相关jar包。
目录结构如下:
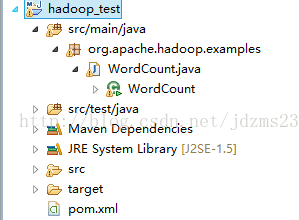
pom.xml配置如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>hadoop_test</groupId>
<artifactId>hadoop_test</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>hadoop_test</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hbase.version>0.94.2</hbase.version>
<hadoop.version>2.5.2</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-client</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-common</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-server-common</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase</artifactId>
<version>${hbase.version}</version>
<exclusions>
<exclusion>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>org.apache.hadoop.examples.WordCount</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
其中WordCount程序从hadoop源码,路径为:hadoop-2.5.2-src\hadoop-mapreduce-project\hadoop-mapreduce-examples\src\main\java\org\apache\hadoop\examples拷贝,具体代码在附件中。
2.打包成jar

上传jar包到服务器
3.建立WordCount的input文件
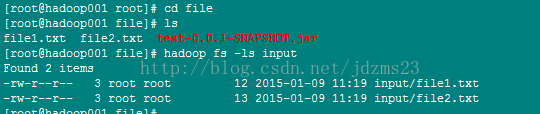
4.运行程序
![]()
5.查看运行结果

可以看到Hadoop个数为1
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)