参考链接:
(1)对抗攻击常见方法汇总 https://blog.csdn.net/qq_43367558/article/details/121694626
(2)对抗性样本攻击方法汇总 https://zhuanlan.zhihu.com/p/136304195
(3)对抗样本攻击方法总结 对抗样本攻击方法总结_huitailangyz的博客-CSDN博客_对抗样本攻击
一、对抗攻击常见方法汇总
对抗样本的攻击主要分为:
- 无特定目标攻击(即只要求分类器对对抗样本错误分类,而不特定要求错误分类到哪一类);
- 特定目标攻击(即要求分类器将对抗样本错误分类到特定类别)。
常见的对抗样本攻击方法或算法有:FGSM、BIM、StepLL、MI-FGSM、DIM、TIM、SI-NI等。
| 算法 | Attack or Defense | Details |
|---|
| 攻击目标函数 | / |   ,其中 ,其中 为输入图像, 为输入图像, 为对抗样本图像,y为输入图像的真实类别标签。 为对抗样本图像,y为输入图像的真实类别标签。
对抗样本生成时候的约束是基于真实样本的 距离小于 距离小于 。 。 函数J一般为交叉熵函数: ,其中N表示分类的类别数,y为one-hot的输入图像的类别标签,C为分类器。 ,其中N表示分类的类别数,y为one-hot的输入图像的类别标签,C为分类器。 |
|---|
| FGSM | White Attack | 1、原理详细: https://www.cnblogs.com/tangweijqxx/p/10615950.html 2、参数解释详细: https://blog.csdn.net/qq_35414569/article/details/80770121 激活函数学习链接: https://liam.page/2018/04/17/zero-centered-active-function/
主要思想: 添加一个与梯度方向一致且在阈值内的扰动使分类错误。(所有基于梯度的攻击方法都是基于让梯度增大这一点来做的) 3、公式来源于Explaining and harnessing adversarial examples [2015ICLR]  ,该论文提出的是单步方法,直接将损失函数J对输入图像x求导,再根据导数的符号得到每个像素的扰动方向,并乘以扰动大小。 ,该论文提出的是单步方法,直接将损失函数J对输入图像x求导,再根据导数的符号得到每个像素的扰动方向,并乘以扰动大小。
|
|---|
| BIM(I-FGSM) | White Attack | 1、 基于文献写作顺序: https://blog.csdn.net/StardustYu/article/details/104803620/
2、 基于原理:https://blog.csdn.net/ilalaaa/article/details/106070091
PGD 和BIM 的区别: 迭代次数增加了和随机噪声初始化 3、公式来源于Adversarial examples in the physical world [2016] 

该论文提出的是迭代的攻击方法,一共迭代攻击T步,每次的攻击步长为 |
|---|
| PGD(K-FGSM,K表示迭代的次数) | White Attack | 1、学习链接: https://www.cnblogs.com/tangweijqxx/p/10617752.html
2、联系与区别:
1) FGSM是仅仅做一次迭代,走一大步,而PGD是做多次迭代,每次走一小步,每次迭代都会将扰动clip到规定范围内。
2) 一般来说,PGD的攻击效果比FGSM要好,首先,如果目标模型是一个线性模型,那么用FGSM就可以了,因为此时loss对输入的导数是固定的,换言之,使得loss下降的方向是明确的,即使你多次迭代,扰动的方向也不会改变。而对于一个非线性模型,仅仅做一次迭代,方向是不一定完全正确的,这也是为什么FGSM的效果一般的原因了。 |
|---|
| MI-FGSM(Momentum Iterative Fast Gradient Sign Method) | / | 1、公式来源于Boosting adversarial attacks with momentum [2018CVPR] 

其中为衰退因子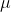 ,该论文中取值为1。该论文提出的方法在BIM方法的基础上,使用一个动量来记录前面迭代时的优化方向,再结合当前步的导数,从而确定当前步的最终优化方向,该方法可以提高黑盒攻击时的迁移性。 ,该论文中取值为1。该论文提出的方法在BIM方法的基础上,使用一个动量来记录前面迭代时的优化方向,再结合当前步的导数,从而确定当前步的最终优化方向,该方法可以提高黑盒攻击时的迁移性。 |
|---|
| MIM(类似PGD) | White Attack | 1、 学习链接: https://www.cnblogs.com/tangweijqxx/p/10623831.html
2、 MIM攻击全称是 Momentum Iterative Method,其实这也是一种类似于PGD的基于梯度的迭代攻击算法。它的本质就是,在进行迭代的时候,每一轮的扰动不仅与当前的梯度方向有关,还与之前算出来的梯度方向相关。其中的衰减因子就是用来调节相关度的,decay_factor在(0,1)之间,decay_factor越小,那么迭代轮数靠前算出来的梯度对当前的梯度方向影响越小。 |
|---|
| DeepFool | White Attack | 1、 学习链接: https://zhuanlan.zhihu.com/p/220421894
2、 贡献一: 量化了分类器的鲁棒性并提出使用不精确的方法来计算对抗性扰动可能会导致关于鲁棒性的不同甚至是误导性的结论。
贡献二: 提出了简单而有效的方法,基于分类器的迭代线性化,计算足以更改标签的最小扰动(基于超平面分类,最小的扰动就是将x移动到超平面上,这个样本到超平面的距离就是代价最小的地方) |
|---|
| C&W | Write Attack | 1、 学习链接: https://www.jianshu.com/p/9440af6c640f
2、 CW是一个基于优化的攻击,主要调节的参数是c和k , c用来调节两个损失函数,k是置信度。它的优点在于,可以调节置信度,生成的扰动小,可以破解很多的防御方法,缺点是,很慢。条件一,保证了生成样本与原始干净样本尽量的相似。条件二,保证了生成样本确实能成功攻击模型。(包括防御蒸馏)
3、 loss1 = nn.MSELoss(reduction=’sum’)(a, images):表示优化目标函数的第一项损失函数。loss2 = torch.sum(self.c*f(a)):表示优化目标函数的第二项损失函数。 |
|---|
| Boundary | Black Attack | 
1、 学习链接: https://zhuanlan.zhihu.com/p/377633699
2、 主要思想: 首先寻找到一个不限制扰动大小的对抗样本 , 然后依据一定策略将该对抗样本沿着原样本的方向移动 , 直到该对抗样本离原样本最近 , 其结果依然保持较强的对抗性。
拓展:
3、 gradient-based: 知道模型的细节信息(梯度、结构),利用对应图片的梯度进行攻击;
4、 score-based:(需要input+每一个类别的概率)不知道模型的细节信息,但是知道模型预测的概率或者logits。
5、 transfer-based: 不依赖模型的信息,但是依赖训练数据的信息,可以利用训练数据训练替代模型,从而生成可迁移的扰动;如果对抗样本是攻击很多替代模型集成而得到的,攻击成功率可以达到近100%。
6、 decision -based: (需要input和 label(例如预测数字为label=2) |
|---|
| Evolutionary | Black Attack | 1、 学习链接: https://zhuanlan.zhihu.com/p/379040824 https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/103342334
2、原理: 为了探索下一个可行解,我们需要进行采样。黑色椭圆表示采样概率分布,其服从高斯分布。该分布的中心点为当前可行解,协方差矩阵是则是根据历史可行解进行估计的,其基本思想是:根据历史探索点,我们可以计算出各个方向的探索成功率;沿着成功率大的方向继续探索,更容易找到下一个可行解。 |
|---|
| N-Attack | Black Attack | 
1:学习链接:https://www.dazhuanlan.com/chunranjewel/topics/959748
2、 原理:
1) 将 θ \thetaθ 定义为正态分布的均值和方差参数,从而通过 θ \thetaθ 可以从正态分布中采样得到大量的值,将这些值称为种子(seed),然后通过映射函数将种子映射为与图片尺寸相同的向量即可。注意这里的映射函数不应该有任何可训练的参数,否则 p i ( x ′ ∥ θ ) pi(x^{\prime}\|\theta)pi(x ′∥θ) 就不只有 θ \thetaθ 这一个参数。
2) 有了生成模型,我们需要做的只剩下优化模型的参数 θ \thetaθ。
3) 作者给出的方法是不直接去求 J ( θ ) J(\theta)J(θ) 关于 θ \thetaθ 的导数,想办法求近似值来代替,然后利用梯度下降法优化 θ \thetaθ。求近似值的方法来源于 NES(Natural Evolution Strategies,2008)。首先认为 ,即对某输入x的导数等于在x周围随机取样得到输出的平均值对x的导数。 ,即对某输入x的导数等于在x周围随机取样得到输出的平均值对x的导数。 |
|---|
| NES | Black Attack | 1、学习链接: https://echenshe.com/class/ea/3-03-evolution-strategy-natural-evolution-strategy.html
2、Policy Gradient: https://zhuanlan.zhihu.com/p/42055115(与NES算法思想很相似,Policy Gradient是强化学习中的算法)
Natural ES 后面简称 NES, 应该就是算一种用适应度诱导的梯度下降法, 如果用一句话来概括 NES: 生宝宝, 用好宝宝的梯度辅助找到前进的方向,NES作为梯度估计技术,并且用PGD算法生成对抗样本。 |
|---|
| ZOO | Black Attack | 
1、 学习链接: https://blog.csdn.net/qq_34206952/article/details/115469971
2、 原理清晰: https://www.jianshu.com/p/cb452f48685c
3、 算法过程: 随机选取一个坐标,估计梯度;获得近似梯度后,利用一阶或二阶方法(Adam 方法或newton方法)来获取best梯度;获得best梯度后,输入目标model,如果出错则保留修改后的x,否则,循环算法过程直到产生best梯度。 |
|---|
| SPSA | Black Attack | Chen 等 [35] 提出了零阶优化 (Zeroth Order Optimization, ZOO) 来估计目标模型的梯度以产生对抗样本。其假设目标模型能够被查询以获得所有类的概率得分 , 然后使用差分数值近似估计目标函数关于输入的梯度 , 进而使用基于梯度的方法进行攻击。类似地 , Jonathan等 [36] 提出了一种使用同时扰动随机逼近算法(Simultaneous Perturbation Stochastic Approximation, SPSA) 进行梯度估计实施攻击的方法,通过特征降维以及随机抽样比 ZOO 取得了更高的效率。 |
|---|
| StepLL(Single-Step Least-Likely Class Method) | / | 1、公式来源于Adversarial Machine Learning at Scale [2017ICLR] 
 ,其中C为分类器。 ,其中C为分类器。
该论文提出的是单步的攻击方法,与FGSM方法中增大图像与真实标签之间的距离不同,该方法是约束图像与分类概率最低的类别之间的距离。 |
|---|
| DIM(Diverse Inputs Method) | / | 1、来源于Improving transferability of adversarial examples with input diversity [2018] 该方法提出对输入的真实图像进行随机变换(以一定的概率进行resize、padding等操作),然后再作为分类器的输入,并进行后续的求导操作。该方法可以与MI-FGSM等方法结合,同样可以提高攻击的迁移性。 |
|---|
| TIM(Translation-Invariant Method) | / | 1、公式来源于Evading Defenses to Transferable Adversarial Examples by Translation-Invariant Attacks [2019CVPR] TI-FGSM: TI-BIM: 其中W是高斯卷积核。 该论文提出的方法,在正常将交叉熵函数对输入求导后,再经过一个高斯核的卷积变换,将得到的值再作为图像的更新方向进行修改,该方法也同样可以和MI-FGSM和DIM等方法进行结合。 |
|---|
| SI-NI | / | 1、来源于Nesterov Accelerated Gradient and Scale Invariance for Adversarial Attacks [2020ICLR],是在MI-FGSM的基础上提出了两点改进。 1)NI-FGSM(Nesterov Iterative Fast Gradient Sign Method):与MI-FGSM相比,NI-FGSM在每次迭代前,在前面累积梯度方向先再前进一步,然后再进行更新。公式为: 

2)SIM(Scale-Invariant attack Method):该方法首先将输入图像在数值上进行不同尺度的缩放,即 。 。 再对不同数值缩放过的图像分别经过分类器,得到类别概率后计算交叉熵,再将各个模型的损失函数计算均值,即 

该论文中m的取值为4,即将[0-1]范围内的输入图像,最小缩放至[0-1/16]范围,以提高对抗攻击在黑盒攻击时的迁移性 |
|---|
二、对抗样本攻击方法汇总
对比代码:
https://github.com/HobbitLong/CMC
https://github.com/jiaxiaojunQAQ/Comdefend
https://github.com/carlini/nn_robust_attacks
https://github.com/dangeng/Simple_Adversarial_Examples/blob/master/adversarial_example.ipynb
https://github.com/akshaychawla/Adversarial-Examples-in-PyTorch
https://github.com/google/unrestricted-adversarial-examples
https://github.com/sarathknv/adversarial-examples-pytorch
https://github.com/duoergun0729/adversarial_examples
http://www.premilab.com/Workshops.ashx
https://medium.com/@ODSC/adversarial-attacks-on-deep-neural-networks-ca847ab1063
1、防御对抗样本的代码:https://modelzoo.co/model/diffai
DIFFERENTIABLE ABSTRACT INTERPRETATION FOR PROVABLY ROBUST NEURAL NETWORKS
abstract:DiffAI is a system for training neural networks to be provably robust and for proving that they are robust.
我们提出了一种训练系统,它可以证明比以前可能的防御更大的神经网络,包括ResNet-34和DenseNet-100。我们的方法基于可区分的抽象解释,并引入了两个新颖的概念:(i)用于微调抽象的精度和可伸缩性的抽象层;(ii)用于描述将抽象与抽象相结合的培训目标的灵活领域专用语言(DSL)具有任意规格的具体损失。我们的训练方法是在DiffAI系统中实现的。
2、Explaining And Harnessing Adversarial Examples_2015ICLR_GoodFellow
包括神经网络在内的几种机器学习模型始终对误解性示例进行错误分类,这些示例性示例是通过对数据集中的示例应用较小但有意的最坏情况的扰动而形成的输入,因此,受扰动的输入会导致模型输出具有高度置信度的错误答案。早期解释这种现象的尝试集中于非线性和过度拟合。相反,我们认为神经网络容易受到对抗性扰动的主要原因是它们的线性特性。这种解释得到了新的定量结果的支持,同时给出了关于它们的最有趣的事实的第一个解释:它们在体系结构和训练集之间的概括。而且,这种观点产生了一种简单快速的生成对抗性例子的方法。使用这种方法为对抗训练提供示例,我们减少了MNIST数据集上maxout网络的测试集错误。
Szegedy等。 (2014b)取得了一个有趣的发现:几种机器学习模型(包括最新的神经网络)容易受到对抗性例子的攻击。也就是说,这些机器学习模型对示例进行了错误分类,这些示例与从数据分布中正确分类的示例仅略有不同。在许多情况下,在训练数据的不同子集上训练过的具有不同体系结构的各种模型会误将同一对抗性示例分类。这表明对抗性示例暴露了我们训练算法中的基本盲点。
这些对抗性例子的原因是一个谜,而推测性的解释表明,这是由于深度神经网络的极端非线性所致,也许与纯监督学习问题的模型平均不足和正则化不足相结合。我们证明这些推测性假设是不必要的。高维空间中的线性行为足以引起对抗性例子。这种观点使我们能够设计一种快速生成对抗性示例的方法,从而使对抗性训练切实可行。我们表明,对抗性训练可以提供单独使用辍学者(Srivastava等人,2014)所提供的正则化好处。通用的正则化策略(例如,辍学,预训练和模型平均)并不能显着降低模型对付对抗性示例的脆弱性,但改用非线性模型族(例如RBF网络)可以做到。
我们的解释表明,由于线性而易于训练的设计模型与使用非线性效应来抵抗对抗性扰动的设计模型之间存在根本的张力。从长远来看,通过设计可以成功训练更多非线性模型的更强大的优化方法,可以避免这种折衷。
3、Feature Denoising For Improving Adversarial Robustness
对图像分类系统的对抗攻击给卷积网络带来了挑战,并为理解它们提供了机会。这项研究表明,图像上的对抗性扰动会导致这些网络构建的特征产生噪声。受此观察的启发,我们开发了新的网络体系结构,可通过执行特征去噪来提高对抗性。具体来说,我们的网络包含使用非本地方法或其他过滤器对要素进行去噪的块;整个网络都是端到端的培训。当与对抗训练相结合时,我们的特征降噪网络可以在白盒和黑盒攻击设置中极大地提高最新的对抗鲁棒性。在ImageNet上,在10次重复PGD白盒攻击下,现有技术的准确度为27.9%,我们的方法达到了55.7%;即使在具有2000次迭代的PGD白盒极端攻击下,我们的方法也可以确保42.6%的准确性。我们的方法在2018年对抗攻击和防御竞赛(CAAD)中排名第一-在针对48个未知攻击者的类似于ImageNet的秘密测试数据集上,它的分类精度达到了50.6%,比第二名的方法高出约10%. Code is available at https://github.com/facebookresearch/ImageNet-Adversarial-Training
4、Countering Adversarial Images Using Input Transformations
本文研究了在输入图像到系统之前通过转换输入来防御对图像分类系统的对抗示例攻击的策略。具体来说,我们研究在将图像馈送到卷积网络分类器之前应用图像变换,例如位深度缩减,JPEG压缩,总方差最小化和图像缝。我们在ImageNet上进行的实验表明,总方差最小化和图像ting缝在实践中是非常有效的防御措施,尤其是在对网络进行变换图像训练时。这些防御的优势在于其不可区分的性质和固有的随机性,这使得对手很难绕过防御。我们的最佳防御能力通过多种主要攻击方法消除了60%的强灰盒攻击和90%的强黑盒攻击
code: facebookresearch/adversarial_image_defenses
5、AdverTorch V0.1: An Adversarial Robustness Toolbox Based on PyTorch
advertorch是用于进行对抗性鲁棒性研究的工具箱。它包含攻击,防御和强大的训练方法的各种实现。 advertorch基于PyTorch(Paszke et al。,2017)构建,并利用动态计算图的优势提供简洁高效的参考实现。 The code is licensed under the LGPL license and is open sourced at https://github.com/BorealisAI/advertorch
攻击代码:https://github.com/BorealisAI/advertorch
help:https://advertorch.readthedocs.io/en/latest/
6、ComDefend: An Efficient Image Compression Model to Defend Adversarial Examples
论文地址:https://arxiv.org/abs/1811.1267
实现地址:https://github.com/jiaxiaojunQAQ/Comdefend 深度神经网络(DNN)在对抗样本中容易受到影响。即在清晰图像中添加难以察觉的扰动可能会欺骗训练好的深度神经网络。在本论文中,我们提出了一种端到端的图像压缩模型 ComDefend 来抵御对抗样本。该模型由压缩卷积神经网络(ComCNN)和重建卷积神经网络(ResCNN)组成。 ComCNN 用于维护原始图像的结构信息并去除对抗扰动,ResCNN 用于重建高质量的原始图像。换句话说,ComDefend 可以将对抗样本转换为「干净」的图像,然后将其输入训练好的分类器。我们的方法是一个预处理模块,并不会在整个过程中修改分类器的结构。因此,它可以与其他特定模型的抵御方法相结合,共同提高分类器的鲁棒性。在 MNIST、CIFAR10 和 ImageNet 上进行的一系列实验表明,我们所提出的方法优于目前最先进的抵御方法,并且一致有效地保护分类器免受对抗攻击。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)