机器学习项目流程

1. 把问题变成机器学习的问题
有的问题挺难的:叠衣服、开车
有些看似难得机器学习却容易做:翻译、
在工业界,很多问题多少会有一点自己特有的地方,需要对整个ML算法,能够做什么事 有个比较比较全面的了解
2. 收集数据、处理数据
3. 训练、调参
4. 模型部署到线上
5. 关注模型的性能:持续监控模型的预测的精度、线上延迟、...
例子:预测这个房子的价格、预测数字 是一个叫做回归的问题。
可能一开始不会去试任何什么特别高大上的深度学习的模型,我肯定是来训练一个比较简单的模型,比如说我就训练一个最简单的线性回归,主要是用来测试我的整个数据是怎么样子,用一个简单模型来测试数据的好坏
实务上可能会面临的问题:

数据的分布会发生变化,很有可能你在一些数据上训练一个模型,再去另外一个地方预测的话会有问题
比如说你在一个网站上,用户群体在发生变化的话,比如说你以前是一些比较年龄小一点的用户,整个用户的行为是不一样的
你在之前的数据上训练的模型在新的地方肯定是有问题,
或者是说你之前训练的模型,突然碰到一个节假日,整个用户的行为发生变化了,那么这时候你发现你的模型对于人的预测,是会有不一样的地方

领域专家、数据科学家、机器学习专家(对模型做定制化)、软件开发工程师(SDE)
在真正的工业界的应用来说,需要去开发和维护大量的代码,大量的一些产品 一些组件,比如说包括了我怎么样把数据,实时的从产品那边抽取过来,然后做比较高性能的那些数据处理。
模型训练我也不是说 我在python里面点一个run,实际上来说你可能有很多的模型,可能几十个科学家在集群里面做模型训练,
数据科学家都在干什么:😆19%读数据、26%数据清理、21%数据可视化、11%模型选择、12%训练模型、11%部署模型。

data:
1)收集和处理数据
2)数据会有各种偏移,部署时候整个场景发生变化,导致数据covariance shift。
3)机器学习传统假设数据是独立同分布,就是每个数据每个样本是一个长的差不多,但现实中基本上没有东西是独立同分布的,都是多多少少是有一些结构化的东西在里面
数据获取



数据集基本上2个来源:网上爬; 采集数据(无人驾驶、手写)
常见找数据集的地方:

huggingface:专注于做文本的transformer 模型的一个数据集

学术数据集 不那么适合来做产品啊或做应用,用来测试新算法
数据融合

数据生成、数据增强


在工业界,不要太去看说这个算法在学术界的数据集上表现怎么样,很多时候和真实的自己的原始数据上的表现可能会很不一样。
网页数据抓取
数据标注


半监督学习啊其实当然是说你想有标志数据和没标志数据一起使用的话 ,对没有标志的数据和有标注数据的数据分布 做了一些假设:
1)连续性假设
一个样本和另外一个样本特征相似的话,那么这两个样本很可能有相同的标号
即:两个人的行为相近的话,那么这两个人的爱好可能是一样的
2)聚类的假设
我们通常会假设说数据啊他其实是按类分的,用户的群体,一类群体行为类似
数据你不是随机在整个空间里面均匀分布的,而是说按照一小丛一小丛分布的话,可以假设说一个类里面,数据啊可能会有比较相同的标号
当然,不同的类之间啊也可能是有相同标号的
3)流型假设
我们收集到的数据就是维度比较高,有很多很多不同的特征,但实际上 很有可能 数据在本质上是以在一个低维的一个流型上分布的。也就是说,数据内在的复杂性,远远的比你看到的那个维度要低,这样 可以通过降维,来获取更干净一点的数据
自学习
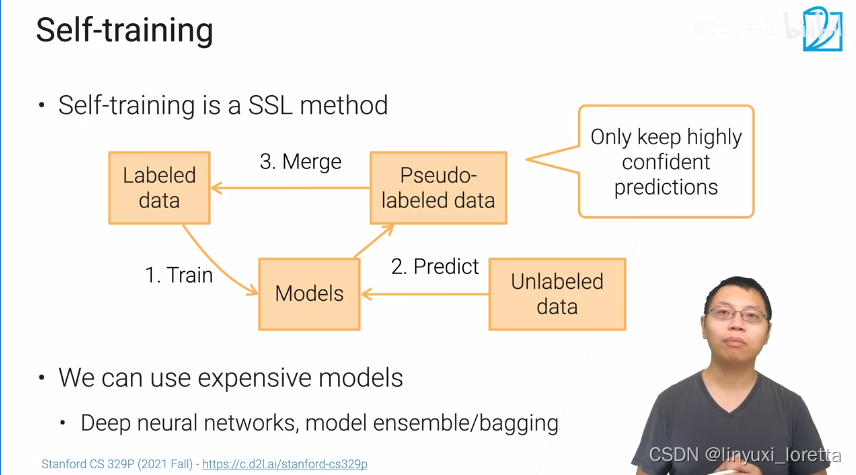
数据众包
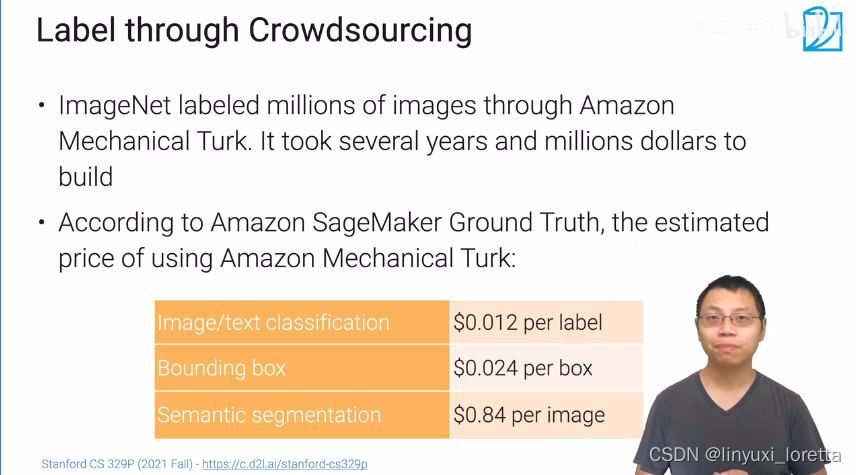
数据工厂、AI村、
Amazon SageMaker Ground Truth 在AWS上的一个服务,帮你标注数据



主动学习: 区别于半监督学习 人会干预
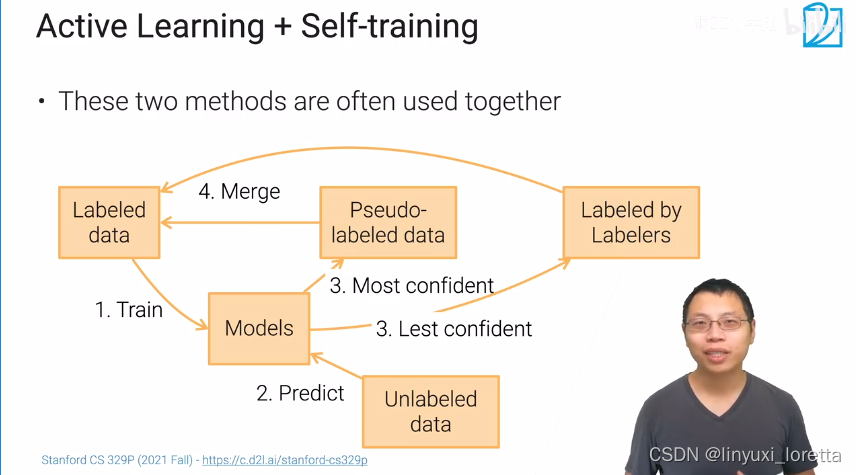

弱监督学习

半自动生产标号,能好到可以训练一个也还不错的模型
启发式的规则

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)