并查集——求无向图的所有连通子图
求解无向图的连通子图,有两种方法,一种是DFS或BFS,也就是对图遍历,另一种方法就是使用并查集。对图的遍历非常常见,而并查集的概念就不如遍历那么熟悉。其实如果仅是找连通子图,用DFS对所有节点遍历一遍就可以,而用并查集则需要遍历两遍。我们不考虑算法效率问题,仅仅是通过这个问题让我们对并查集有所认识,并了解其原理,下面主要说一下并查集。
首先说一下,并查集是一种设计非常好的数据结构,也是一种检索算法。说它是数据结构,因为使用并查集的最终结果是生成一个森林,里面包括一个或多个树。说它是一种算法,是因为通过并查集,我们很容易判断图中任意两个节点是否具有连通性,同时也可以求解出所有连通子图,也就是即将说到的内容。
问题分析
现在来看问题:求无向图的所有连通子图,可以分解成两步,首先,将所有连通的节点,都放到一起,最终分成几个连通分量组;然后,找出属于同一连通分量组的节点及边,也就是各个连通子图。
第二步非常容易,假设第一步生成一个字典,里面存放着所有节点所对应的连通分量组号,那么再对原有的图遍历一遍,从字典中查出节点所属的组并且根据组进行区分,就可以得到所有连通子图。查字典的复杂度是O(1),没有什么计算开销。那么问题主要变为第一步中该如何生成那个字典。
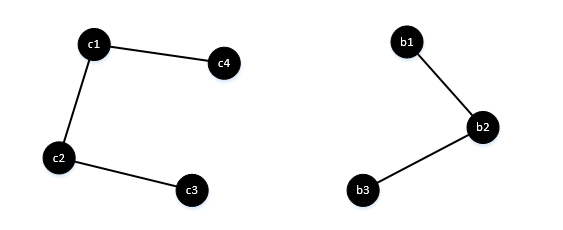
看上面这4个点,c1、c2有连接,我们需要在字典里建立两个值,{c1:Gc},{c2:Gc},Gc代表他们的连通分量组号,这样通过分别查找c1的组号,c2的组号,所得结果一样,我们可以判断出c1、c2属于同一组,具有连通性。同样的,我们在字典中又加入了两个值{c3:Gc},{c4:Gc},我们可以很easy的知道,c3和c4属于同一个连通分量,具有连通性,虽然它们之间没有直接的边相连。对于b开头的3个点,我们在字典中加入它们的组号{b1:Gb},{b2:Gb},{b3:Gb}。根据字典,我们知道,c3和b3不属于同一组,它们之间不连通。
那么问题来了,我们怎么设置字典中的那个组号呢?我认为这就是并查集的精髓所在。
实现过程
1、把节点编号当做组号。
因为要建立字典,我们需要对整个图扫一遍,使字典中的内容覆盖到每一个节点。
上面的那个组号Gc和Gb是人为造的,实际中我们需要按照规则设定组号。
这个规则的基本思想就是,选择节点编号当做组号:
a) 因为一条边有两个节点,选择一条边任意一个节点编号当做这条边上两个节点的组号;
b) 如果字典中已经有了节点的组号,那么选择字典中的,如果没有,则按照上面规则选择节点组号;
对于上述的图,我们按照(c1,c2)–>(c1,c4)–>(c2,c3)–>(b1,b2)–>(b2,b3)的顺序扫这个图。按照上面的规则,假设都选择小编号作为组号,
扫到第1条边(c1,c2)时,建立字典 {c1:c1, c2:c1},
扫到第2条边(c1,c4)时,建立字典 {c1:c1, c2:c1, c4:c1},
扫到第3条边(c2,c3)时,建立字典 {c1:c1, c2:c1, c3:c2, c4:c1},
扫到第4条边(b1,b2)时,建立字典 {c1:c1, c2:c1, c3:c2, c4:c1, b1:b1, b2:b1},
扫到第5条边(b2,b3)时,建立字典 {c1:c1, c2:c1, c3:c2, c4:c1, b1:b1, b2:b1, b3:b2}。
2、找组号的组号,直到找到祖先。
在第一步中我们初步建立了一个字典,里面包括每一个节点。可以看到,节点c3的组号为c2,和节点c1、c2、c4不一致。按照当前的结果,c3被认定为与其它3个c节点都不连通。所以目前还没有完成分组。为了解决这个问题,当我们再次遍历字典时,需要对每个节点得到的组号再次进行寻找组号的操作,直到得到的组号是它自己。对应的代码就是:
def find(key):
while parent[key] != key: //parent就是得到的那个字典
key = parent[key]
return key
代码非常简短,对于c3来说,从字典中得到组号是c2,和c3不等,那就继续找c2的组号,得到c1,和c2还不等,那就找c1的组号,这次得到c1,和自身相等,返回c1,也就是c3的组号。经过不断的查找,终于c3和其它c节点拥有了相同的组号,被划分为了一组。
3、压缩路径
从第2步中看到,为了找c3的组号,有点费劲啊,先找到c2,再找到c1,如果下次还想找c3的组号,还需要这么折腾一次。能不能一下就给出c3的组号是c1呢?没问题,当我们用find方法找c3的时候,得到的组号不是自己的编号,那么我就知道c3的组号一定是它的组号c2的组号,那么我们就把c3的组号直接设定为c2的组号就可以了。只需要在find中改一行就OK了。
def find(key):
while parent[key] != key: //parent就是得到的那个字典
parent[key] = parent[parent[key]] //把c3的组号设定为c2的组号
key = parent[key]
return key
4、合并家族
比如我们的图又扩大了,在原有基础之上有加了几个节点。如图:
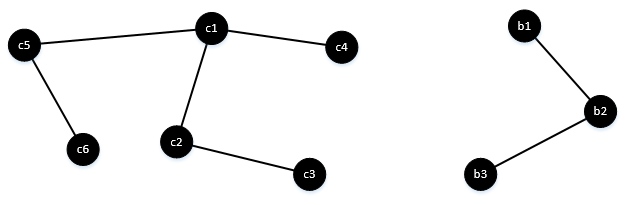
新加了两条边,(c5, c6),(c5, c1),按照这个顺序,当扫完(c5, c6)时,会在字典中加入{c5:c5, c6:c5}两个值。再扫到(c5, c1)时,由于c5有自己的组号,c1也有自己的组号,各自为营,但它俩又有连接。一山不容二虎,那就选一个当老大。在这里就是随便选一个作为另一个的组号。咦,这个怎么又回到的1的问题。。。对的,其实1和4是一个问题,只是1是初始化时的选择方式,4是遍历到中途过程中的选择方式,它俩合并到一起的代码就是:
def init(key):
if key not in parent:
parent[key] = key
def join(key1, key2):
p1 = find(key1)
p2 = find(key2)
if p1 != p2:
parent[p2] = p1
当我们对图的边进行遍历时,就先执行init,看节点是否有组号,没有组号就赋值为自己。再执行join,合并边上的两个节点为同一个组。
假设选c1的组号作为c5的组号,那么目前的字典内容就如下图所示:
{c1:c1, c2:c1, c3:c1, c4:c1, c5:c1, c6:c5, b1:b1, b2:b1, b3:b2}。
对应的数据结构就是:
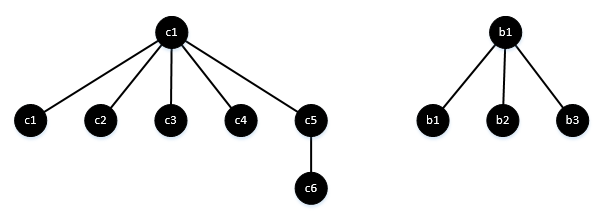
这就是我们最终得到的结果,一个森林,里面包括了两棵树,每棵树代表连通的节点组,树中节点的父节点代表自己的组号。
根据森林中的树,我们就可以找到图中的各个连通子图了,当然,还需要根据这个森林中的内容,也就是我们得到的字典,再遍历一遍图,找到各个连通子图的边,不过已经完美解决了需要的问题。
再回过头来看,其实代码非常的简短,就三个函数,完整代码如下:
代码
class UnionSet(object):
def __init__(self):
self.parent = {}
def init(self, key):
if key not in parent:
self.parent[key] = key
def find(self, key):
self.init(key)
while self.parent[key] != key:
self.parent[key] = self.parent[self.parent[key]]
key = self.parent[key]
return key
def join(self, key1, key2):
p1 = self.find(key1)
p2 = self.find(key2)
if p1 != p2:
self.parent[p2] = p1
应用
除了求图的连通子图(连通分量)可以用到并查集外,在用Kruskal方法求图的最小生成树,也用到了并查集,掌握了并查集,那么再去看Kruskal的方法,就会轻而易举了。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)