引言
ELasticsearch作为一个分布式搜索引擎,能够出色地支持集群模式、动态水平扩容、故障转移等分布式系统特性,这是其作为全文搜索引擎首选的重要原因。
本文从零开始描述集群的配置和扩容过程,让你对Elasticsearch集群的工作原理有初步的理解。
首先,一个Elasticsearch集群时由多个节点组成,同个网络内的节点通过指定cluster.name加入同一个集群,所有的节点共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
Elasticsearch节点分为主节点和数据节点,主节点负责管理协调Elasticsearch集群,包括索引的增加、删除,节点的加入、移除等,但主节点不负责数据存储和搜索,这使得主节点不会有太大的压力,而是保持轻量的状态。数据节点主要负责数据存储和搜索。
节点是否可以作为主节点通过node.master配置设置,true表示可以作为主节点,false表示不可以作为主节点。
节点是否可以作为数据节点通过node.data配置设置,true表示可以作为数据节点,false表示不可以作为数据节点。
默认情况下node.master和node.data都为true,特别注意node.master设置为true只是表示此节点有作为主节点的资格,但是不代表一定成为主节点,主节点是通过集群选举产生,具体选举的策略后续文章再进行讲解。
一、集群配置
1.1 空集群
当我们启动了一个Elasticsearch节点,默认就是创建了一个Elasticsearch集群,只是这个集群只有一个节点。此时如果没有创建索引,则集群处于一种"空"的状态。

此时通过_cluster API查看集群状态
$ curl -X GET "localhost:9200/_cluster/health?pretty"
结果如下,可以看到status为green,节点数量number_of_nodes为1,数据节点数量number_of_data_nodes也为1,因为没有创建索引,所以分片数目为0。
status字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
- green 所有的主分片和副本分片都正常运行
- yellow 所有的主分片都正常运行,但不是所有的副本分片都正常运行。
- red 有主分片没能正常运行。
由于当前不存在主分片也不存在副本分片没正常运行的,所以状态为green。
{
"cluster_name" : "elasticsearch",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
1.2 单节点集群
为当前集群添加索引,指定主分片数量为3,副本分片数量为1。
$ curl -X PUT "localhost:9200/cumstomer?pretty" -H 'Content-Type: application/json' -d'
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
'
此时再次查看集群的状态
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 3,
"active_shards" : 3,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 3,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 50.0
}
可以看到此时活动的主分片数量为3,未分片的分片数量也为3,未分配的分片主要是三个主分片对应的副本分片,由于主分片与副本分片不能存在于同个节点,所以副本分片无法分配,此时集群的状态为yellow。

1.2 两节点集群
如上所述,因为副本分片不能跟主分片分配于同一个节点,那么要实现所谓的副本分片都能够被正常分配,则需要多一个节点。为集群加入一个新的节点,只需要新节点指定集群名字cluster.name与第一个节点相同就能够加入到集群中,加入以后集群会自动进行分片的重新分片,由于存在三个副本分片未被分配,所以三个副本分片会被分配到新的节点,如下图所示。
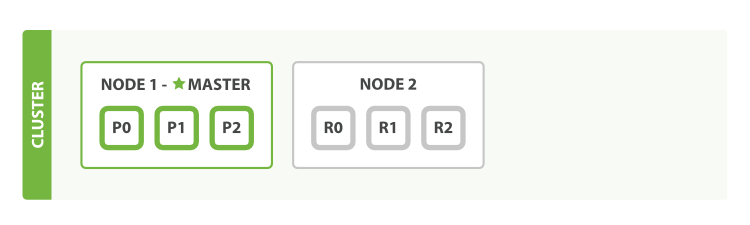
此时查看集群的状态可以发现,所有的分片都被正常分配,此群的状态变为green。
{
"cluster_name": "elasticsearch",
"status": "green",
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 3,
"active_shards": 6,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
二、水平扩容
2.1 主分片的扩容
经过上述增加了两个节点以后我们可以看到三个主分片都处于同一个节点上,共享这个节点的CPU、IO和内存资源,这样子当系统访问量增大时容易出现性能瓶颈,可以考虑增加节点,分担一部分主分片提高性能。例如增加一个节点,组成3个节点的集群,集群中分片的分配如下图所示
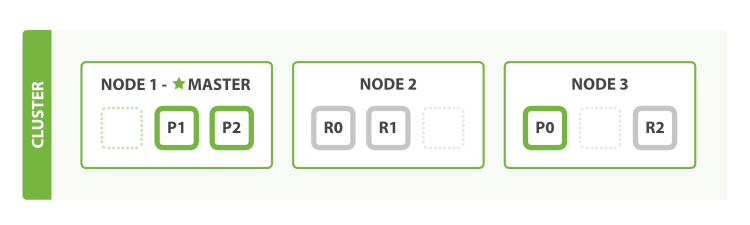
节点最多可以增加到6个节点,平均每个节点分配一个分片,可以最大化提高每个分片的性能。这里注意到,继续增加节点已经无法扩展主分片了,所以主分片的数量决定了整个集群的容量,在进行索引设计的时候需要特别注意,仔细规划。
2.2 副本分片的扩容
虽然主分片无法继续扩容,但是副本分片却是可以动态进行扩容的,动态分片的增加一方面使得高可用性更强,另外一方面副本分片可以提供查询搜索功能,多个副本分片可以扩展搜索的性能,例如修改副本分片的数量为2。
$ curl -X PUT "localhost:9200/customer/_settings?pretty" -H 'Content-Type: application/json' -d'
{
"number_of_replicas" : 2
}
'
修改后分片的分配如下图所示,总共9个分片,副本分片为两个,分别在两个节点之上,搜索时两个节点均能提供搜索服务,性能有了巨大提升。当然还可以继续增加节点和副本分片不断扩大搜索性能。
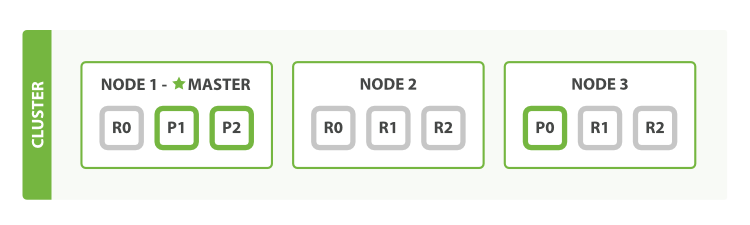
三、故障转移
上面我们反复提到,多个副本分片时为了保证Elasticsearch的高可用性。现在我们在模拟以下Elastic search出现故障时会如何保证这种可用性。
首席停掉Node 1节点,Node1节点是master节点,包含了P1、P2、R0三个分片,由于Elasticsearch集群的运行必要要有一个master节点,所以会在剩下两个节点中重新选举一个master节点,并且由于P1、P2主分片丢失,所以会从其两个副本分片R1和R2中选择两个升级为主分片继续提供服务,最终的集群状态如下,由于此时P1、P2都只有一个副本分片,而我们指定的是两个副本分片,所以存在未正常运行的副本分片,故集群的状态为yellow。
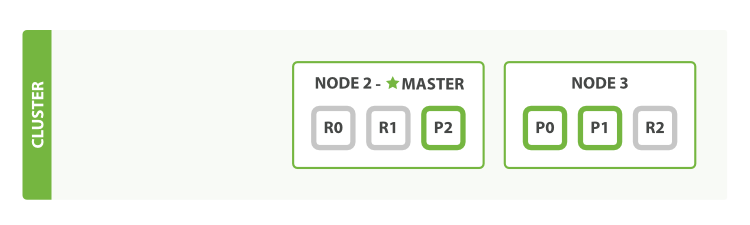
四、分布式索引和搜索
集群包含了多个节点,一个索引包含了多个分片,那么数据是如何被索引的呢?又是如何搜索的呢?
实际上我们可以访问集群中的任意一个节点获取完整的数据集,就是取决于Elasticsearch分布式的索引和搜索方式。
当我们索引一篇文档时,Elasticsearch首先会根据文档的ID进行散列计算,通过散列值选择一个主分片,然后将文档发送到该分片上,此分片不一定在所访问的节点上,也能在任意其他的节点上,但是当然所访问的节点会自动地将请求进行转发,完成文档在主分片地存储以后,该文档还会被发送到该主分片的所有副本分片中去,达到主副分片数据一致。
当我们搜索一篇文档时,同样将请求发送到任意一个节点,不管是数据节点还是主节点,甚至既不是数据节点也不是主节点,但是都处于本集群中,具备搜索功能。收到请求的节点会使用round-robin的轮询机制选择可用的主分片或者副本分片,将请求转发过去,然后将所有的的各个节点返回的响应数据进行聚合之后返回给客户端。
由此我们可以看出,水平扩展增加节点数量是提高Elasticsearch搜索性能的一个很好的方案,即便是不进行数据存储的普通节点,也能够进行请求的转发和响应结果的计算和聚合,减少主节点和数据节点的压力,提高系统的整体性能。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)