前言
对比学习是一种比较学习,其主要目的为让模型学习到不同类别之间的特征,其被广泛应用于人脸识别,文本检索,图像分类等领域。对比学习的主要思想是增大不同类别间的距离,缩小相同类别间的距离,以此来学习到比较特征。
普通的对比学习损失
L
C
L
=
−
l
o
g
e
x
p
(
s
i
,
p
/
τ
)
e
x
p
(
s
i
,
p
/
τ
)
+
∑
n
=
1
N
e
x
p
(
s
i
,
n
/
τ
)
\mathcal{L_{CL}=-log\frac{exp(s_{i,p}/\tau)}{exp(s_{i,p}/\tau)+\sum_{n=1}^{N}exp(s_{i,n}/\tau)}}
LCL=−logexp(si,p/τ)+∑n=1Nexp(si,n/τ)exp(si,p/τ)
说先看一下最普通的对比损失学习,当正样本对只有一对,负样本对有n对的时候,这就是最常见的交叉熵损失,普通的对比损失可以良好的区分开不同类别,但是,对于相同类别之间与不同类别之间的距离却无法很好的分开。通常我们在进行检索的时候,我们是通过计算新输入的样本的特征,然后与数据库中所有的样本进行比较,计算相似度或者欧式距离,按照阈值来进行排序,最终给出高于阈值的相似样本。而上述普通对比学习损失通常作为分类模型进行学习,因此对于类内距离并不敏感,下图是个例子(图取自https://kexue.fm/archives/5743):
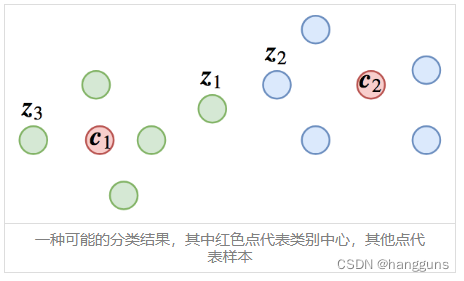
可以看到z1,z2,z3在分类模型中都很好的被区分了,但是以相似度或者距离来衡量的时候,不同类别间的点z1和z2的距离是最近的,导致输出的相似样本是错误的。针对这种情况,我们希望模型在能够区分类别间的样本的同时,进一步缩短类内的距离。接下来首先介绍一下L-softmax与AM-softmax,这两种损失通过引入margin的方式,窄化了决策边界,虽然使得模型学习更难,但是优化完全后,可以进一步将类内距离缩小,将类间距离放大
L-softmax
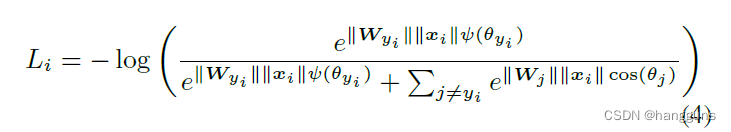
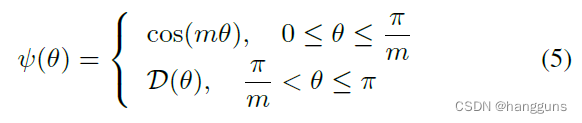
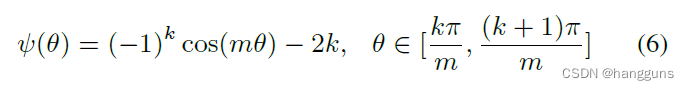
L-softmax添加了乘性边界m到余弦公式中,以此来增大决策边界。假设在面对2分类的任务时,我们想要区分类别1和类别2,那么原始的softmax会学习
W
1
T
x
>
W
2
T
x
W_1^Tx>W_2^Tx
W1Tx>W2Tx,也就是
∣
∣
W
1
∣
∣
∣
∣
x
∣
∣
c
o
s
(
θ
1
)
>
∣
∣
W
2
∣
∣
∣
∣
x
∣
∣
c
o
s
(
θ
2
)
||W_1||||x||cos(\theta_1)>||W_2||||x||cos(\theta_2)
∣∣W1∣∣∣∣x∣∣cos(θ1)>∣∣W2∣∣∣∣x∣∣cos(θ2)。在这种情况下,模型只会学习一条决策边界,来区分类别1和类别2。如果我们想要更加严格区分类别1和类别2呢?我们可以将上面的公式更改为
∣
∣
W
1
∣
∣
∣
∣
x
∣
∣
c
o
s
(
m
θ
1
)
>
∣
∣
W
2
∣
∣
∣
∣
x
∣
∣
c
o
s
(
θ
2
)
||W_1||||x||cos(m\theta_1)>||W_2||||x||cos(\theta_2)
∣∣W1∣∣∣∣x∣∣cos(mθ1)>∣∣W2∣∣∣∣x∣∣cos(θ2),m为整数,通过这种方式,我们可以得到一个新的决策边界:
∣
∣
W
1
∣
∣
∣
∣
x
∣
∣
c
o
s
(
θ
1
)
≥
∣
∣
W
1
∣
∣
∣
∣
x
∣
∣
c
o
s
(
m
θ
1
)
>
∣
∣
W
2
∣
∣
∣
∣
x
∣
∣
c
o
s
(
θ
2
)
||W_1||||x||cos(\theta_1)\ge||W_1||||x||cos(m\theta_1)>||W_2||||x||cos(\theta_2)
∣∣W1∣∣∣∣x∣∣cos(θ1)≥∣∣W1∣∣∣∣x∣∣cos(mθ1)>∣∣W2∣∣∣∣x∣∣cos(θ2)
我们知道
θ
∈
[
0
,
π
]
\theta\in[0,\pi]
θ∈[0,π],
c
o
s
θ
∈
[
−
1
,
1
]
cos\theta\in[-1,1]
cosθ∈[−1,1],在区间
0
,
π
0,\pi
0,π内,余弦函数为递减函数,因此增加乘性边界m算子使得决策边界更加窄,也使得模型的训练难度增大。
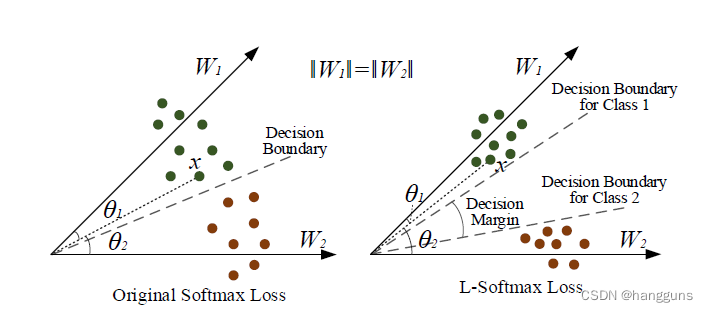
假设原始softmax和L-softmax都可以被完全优化,那么我们可以产生如下决策边界
由于
W
1
T
x
W_1^Tx
W1Tx的角度从原来的
θ
1
\theta1
θ1缩减为了
θ
1
m
\frac{\theta1}{m}
mθ1,因此所有类别1样本距离类别1向量的角度都减小了,对于类别2来说也一样,因为类别1与类别2之间的类内距离减小了,所以类间的距离就增大了,模型学习了2个决策边界,决策边界之间的角度则为decision margin。
AM-softmax
L
A
M
−
s
o
f
t
m
a
x
=
−
l
o
g
e
x
p
(
(
s
i
,
p
−
m
)
/
τ
)
e
x
p
(
(
s
i
,
p
−
m
)
/
τ
)
+
∑
n
=
1
N
e
x
p
(
s
i
,
n
/
τ
)
\mathcal{L_{AM-softmax}=-log\frac{exp((s_{i,p}-m)/\tau)}{exp((s_{i,p}-m)/\tau)+\sum_{n=1}^{N}exp(s_{i,n}/\tau)}}
LAM−softmax=−logexp((si,p−m)/τ)+∑n=1Nexp(si,n/τ)exp((si,p−m)/τ)
AM-softmax提出了一种更加简单实现的加性算子,与作用于角度的乘性算子不同,加性算子直接作用于cosine similarity,在相同类别的相似度中,减去一个margin参数m,并通过较大的温度系数
τ
\tau
τ进行放大,与L-softmax类似,我们希望
s
1
≥
s
1
−
m
>
s
2
s_1\ge s_1-m> s_2
s1≥s1−m>s2
我们知道,余弦值越小,代表角度越大,因此
s
2
s_2
s2即类间角度被限制为更大的一个角度。假设AM-softmax能够完全优化,那么参考L-softmax中的图,取原始softmax中余弦为
c
o
s
θ
1
cos\theta_1
cosθ1,AM-softmax中为
c
o
s
θ
1
′
=
c
o
s
θ
1
−
m
cos\theta_1'=cos\theta_1-m
cosθ1′=cosθ1−m即
c
o
s
θ
1
=
c
o
s
θ
1
′
+
m
cos\theta_1=cos\theta_1'+m
cosθ1=cosθ1′+m,我们知道余弦值越大,角度越小,因此AM-softmax与L-softmax一样,将类内的距离缩小了。
Circle-loss
虽然上述2个损失能够将类内距离进一步缩小,类间距离进一步增大,但是实际情况中,模型对于难样本与简单样本的关注度是一样的,也就是梯度是一样的。因此很容易想到,我们希望让模型将注意力更多地放到难样本中,采用不同的梯度对不同的样本进行训练,于是circle-loss便被提了出来。
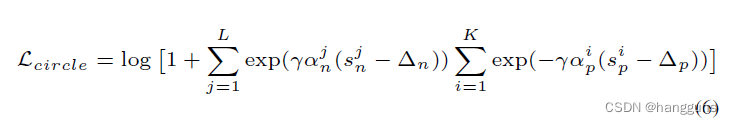
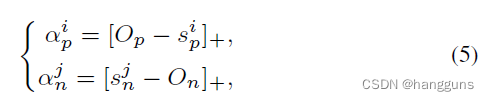
上述circle loss的形式与AM-softmax分式的形式不同,其可以由分式推导出来,以AM-softmax为例
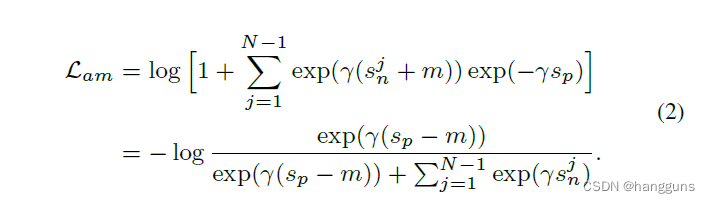
在circle loss中,引入了2个松弛因子
α
p
i
,
α
n
i
\alpha_p^i, \alpha_n^i
αpi,αni,其中p代表类内,n代表类间,
O
p
O_p
Op代表类内相似度的上界,
O
n
O_n
On代表类间相似度的下界,
△
p
\bigtriangleup_p
△p代表类内margin,
△
n
\bigtriangleup_n
△n代表类间margin,松弛因子均大于0。
α
p
i
\alpha_p^i
αpi会随着
s
p
i
s_p^i
spi的增大而减小,意味着给类内距离大的难样本更大的权重,给类内距离小的简单样本更小的权重。
α
n
j
\alpha_n^j
αnj会随着
s
n
j
s_n^j
snj的减小而减小,意味着给类间距离大的简单样本更小的权重,给类间距离小的难样本更大的权重。上下界的意义为我们对满足要求的样本赋予最低要求权重进行更新。
circle loss 希望
s
n
j
<
△
n
s_n^j<\bigtriangleup_n
snj<△n而
s
p
j
>
△
p
s_p^j>\bigtriangleup_p
spj>△p,按这个方向更新使损失变小。在2分类问题中,决策边界为
α
n
(
s
n
−
△
n
)
−
α
p
(
s
p
−
△
p
)
=
0
\alpha_n(s_n-\bigtriangleup_n)-\alpha_p(s_p-\bigtriangleup_p)=0
αn(sn−△n)−αp(sp−△p)=0时,决策边界为
(
s
n
−
O
n
+
△
n
2
)
2
+
(
s
p
−
O
p
+
△
p
2
)
2
=
C
(s_n-\frac{O_n+\bigtriangleup_n}{2})^2+(s_p-\frac{O_p+\bigtriangleup_p}{2})^2=C
(sn−2On+△n)2+(sp−2Op+△p)2=C
C
=
(
(
O
n
−
△
n
)
2
+
(
O
p
−
△
p
)
2
)
/
4
C=((O_n-\bigtriangleup_n)^2+(O_p-\bigtriangleup_p)^2)/4
C=((On−△n)2+(Op−△p)2)/4
设定
O
p
=
1
+
m
,
O
n
=
−
m
,
△
p
=
1
−
m
,
△
n
=
m
O_p=1+m,O_n=-m,\bigtriangleup_p=1-m,\bigtriangleup_n=m
Op=1+m,On=−m,△p=1−m,△n=m,可以得到决策边界为
(
s
n
−
0
)
2
+
(
s
p
−
1
)
2
=
2
m
2
(s_n-0)^2+(s_p-1)^2=2m^2
(sn−0)2+(sp−1)2=2m2
其目的为优化
s
n
→
0
,
s
p
→
1
s_n\rightarrow 0,s_p\rightarrow 1
sn→0,sp→1,m决定了决策边界的半径,换句话说,circle loss期望
s
p
i
>
1
−
m
,
s
n
j
<
m
s_p^i>1-m,s_n^j<m
spi>1−m,snj<m,同时采用sample-specific的方式进行训练
PCCL
PCCL在circle loss的基础上,删除了margin,其公式如下
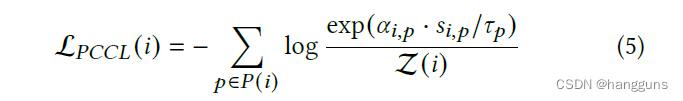
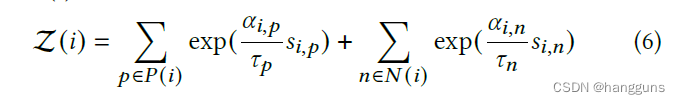
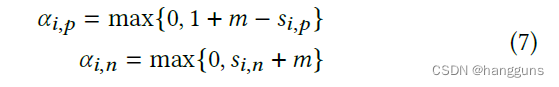
在原论文中,作者单纯通过
α
i
,
p
\alpha_{i,p}
αi,p与
α
i
,
n
\alpha_{i,n}
αi,n去期望
s
i
,
p
>
1
−
m
,
s
i
,
n
<
m
s_{i,p}>1-m,s_{i,n}<m
si,p>1−m,si,n<m,我认为是不合理的,按上述所示,应该为
s
i
,
p
→
1
,
s
i
,
n
→
−
m
s_{i,p}\rightarrow 1,s_{i,n}\rightarrow -m
si,p→1,si,n→−m,由于论文是应用于小样本finetune,因此设定了
τ
p
=
ξ
τ
n
\tau_p=\xi\tau_n
τp=ξτn,
ξ
\xi
ξ为正整数,目的在于让类内相似度不要过大,防止过拟合
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)