【论文】eney, Damien, Peter Anderson, Xiaodong He, and Anton Van Den Hengel. Tips and tricks for visual question answering: Learnings from the 2017 challenge.(pdf)
主要思想
论文提出一些细节上优化提升 VQA 的方法,主要包括如下:
- sigmoid output:在结果预测时,允许有多个答案,对每个答案采用 sigmoid 方法预测
- use soft scores as ground truth targets:预测时采用回归预测,预测概率,而不是传统的分类
- gated tanh activations:激活函数采用 tanh
- image features from bottom-up attention:图像特征提取采用目标检测的方法
- pretrained representations of candidate answers:初始化输出层的权重
- large mini-batches and samrt shuffling:训练过程中使用 large mini-batch 和混洗的方式
模型架构
模型前面采用了常见的 joint embedding of input question and image,后半部分对候选答案使用了一个多标签分类器
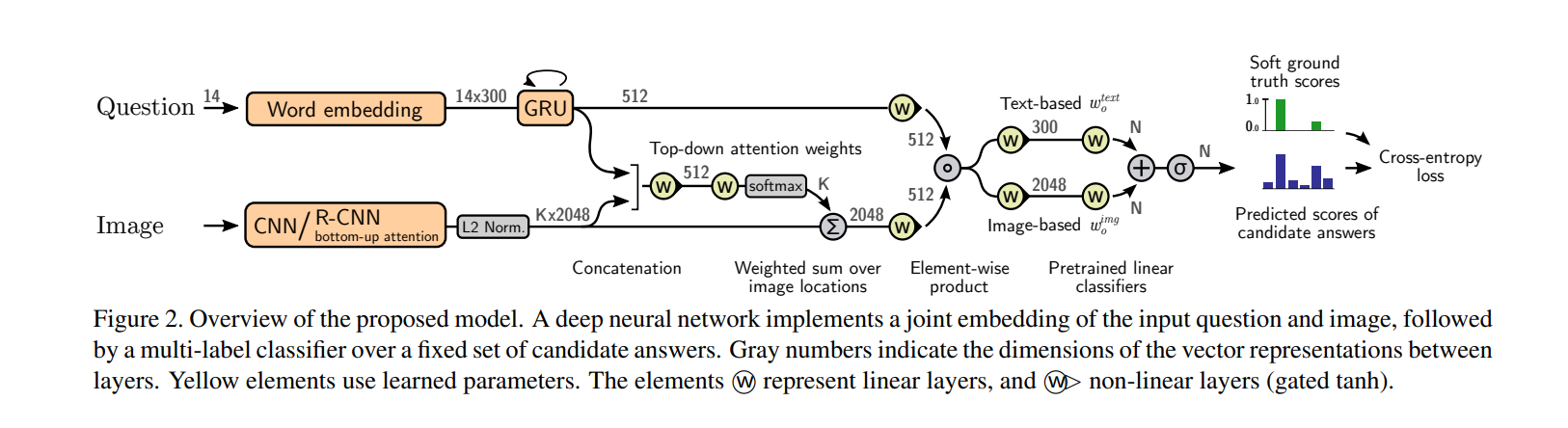
Question embedding
使用 GloVe 提取问题语义特征,整个数据集中只有 0.25% 问题超过了 14 个单词,因此文章考虑一个问题最多包含 14 个单词,超出的全部丢弃。使用 Wikipedia / Gigaword 语料库上预训练好的 GloVe (Global Vectos for Word Representation)来进行词特征的向量化,每个单词背转化为一个 300 维的向量。对于少于 14 个单词的语句,采用 end-padded 补齐。于是,一个问题就可以被表述为 14×300 的矩阵,送入 GRU(Recurrent Gated Unit),GRU 的 hidden_size = 512,我们提取最有一个状态作为我们的问题语义向量
q
q
q
Image features
视觉特征的注意力模型 bottom-up attention 是指通过 faster-rcnn 的检测区域提取不同类别物体的特征,这种方式也可以叫做给予显著性的 attention 机制。图像通过 faster-rcnn 后,获得一个
K
×
2048
K\times2048
K×2048 的矩阵,
K
K
K 代表图片有多少个位置,每个位置由一个
2048
2048
2048 维的向量表示,这个向量是
K
K
K 对应区域的图像特征编码,
K
K
K 是从 faster-rcnn 的 top-K 中确定的
实验中作者既选择了一个固定值
K
=
36
K=36
K=36,也设定
K
K
K 也可以是一个自适应的数值,允许
K
K
K 随图像的复杂度而变化,最大上限是 100,这种情况下 VQA v2 产生的
K
K
K 的均值是每张图片 60 个区域
这种注意力机制不受训练影响,应该属于 hard attention。faster-rcnn 在 visual genome 数据上训练,同时加入更多标签,使 faster-rcnn 能够提取到更精细的区域与特征,最后实验证明,bottom-up attention 能够使模型性能提升 6%
Image attention
文中的模型采用 question-guided attention(作者将这一步成为 top-down attention,区别于 bottom-up attention)机制,该机制通过问题的语义特征指导视觉特征
对图片上的每个位置
i
=
1
,
⋯
,
K
i=1,\cdots,K
i=1,⋯,K,图像特征
v
i
v_i
vi 和问题语义特征
q
q
q 结合在一起,共同经过一层非线性映射
f
a
f_a
fa,然后再经过一个线性层得到一个标量注意力权重
α
i
,
t
\alpha_{i, t}
αi,t
a
i
=
w
a
f
a
(
[
v
i
,
q
]
)
α
=
s
o
f
t
m
a
x
(
a
)
v
^
=
∑
i
=
1
K
α
i
v
i
a_i=w_af_a([v_i, q])\\ \alpha = softmax(a)\\ \hat v=\sum_{i=1}^K\alpha_iv_i
ai=wafa([vi,q])α=softmax(a)v^=i=1∑Kαivi其中,
w
a
w_a
wa 实现学习参数的向量。所有位置的注意力权重经过 softmax 函数进行归一化。然后,所有位置的图像特征以归一化的注意里权重为权值,然后加和得到一个大小为 2048 的向量
v
^
\hat v
v^
注意到这种注意力机制是 one-glimpse attention,区别于其他复杂的注意力机制(stacked、multi-head 以及 bidirectional attention)
Multimodal fusion
多模态特征融合 joint embedding 采用对应位置相乘的方式(hadamard product),问题语义特征
q
q
q 和图像特征
v
^
\hat v
v^ 经过非线性层处理后通过 Hadamard product 结合起来
h
=
f
q
(
q
)
∘
f
v
(
v
^
)
h=f_q(q)\circ f_v(\hat v)
h=fq(q)∘fv(v^)
Output classifier
候选答案集合在文中被称为输出词汇表,从训练集中出现 8 次以上的所有正确答案中预先选出来,最终得到一个
N
=
3129
N=3129
N=3129 的候选答案集。作者将 VQA 是做一个多标签分类问题。VQA v2 中每一个训练的问题都有一或多个回答,每一回答对应
[
0
,
1
]
[0,1]
[0,1] 中的一个 soft accuracy。之所以会出现多种回答和
[
0
,
1
]
[0,1]
[0,1] 准确率,是因为人们在标注时的分歧,尤其是模棱两可的问题或者相同意思不同表述的回答。由于标注的模糊性,训练集有 7% 的问题无法从输出词汇表中给出正确答案。作者没有丢弃这部分问题,而发现了一个有意思的现象——这些模糊问题都会将输出词汇表中所有的候选词的预测得分推向零
输出分类器将
h
h
h 输入到非线性变换层
f
o
f_o
fo(由后面知道这个非线性变换层
f
o
f_o
fo 表示 gated tanh activations),然后在经过一个线性变换得到预测得分
s
^
\hat s
s^,可以描述为如下式子
s
^
=
σ
(
w
o
,
f
o
(
h
)
)
\hat s=\sigma(w_o, f_o(h))
s^=σ(wo,fo(h))其中
w
o
∈
R
N
×
512
w_o\in\mathbb R^{N\times512}
wo∈RN×512 是一个学习矩阵
sigmoid 函数将最终得分归一化到
(
0
,
1
)
(0,1)
(0,1),损失函数设计如下所示,类似于交叉熵损失,只不过作者使用了的是 soft target scores
L
=
−
∑
i
=
1
M
∑
j
=
1
N
s
i
j
l
o
g
(
s
^
i
j
)
−
(
1
−
s
i
j
)
l
o
g
(
1
−
s
^
i
j
)
L=-\sum_{i=1}^M\sum_{j=1}^Ns_{ij}log(\hat s_{ij})-(1-s_{ij})log(1-\hat s_{ij})
L=−i=1∑Mj=1∑Nsijlog(s^ij)−(1−sij)log(1−s^ij)其中
M
M
M 表示训练问题的数量,
N
N
N 表示训练候选答案的数量,
s
s
s 表示 soft accuracy of ground truth answer
这个损失函数有两个优点:
- sigmoid 的输出使每个问题可以预测多个答案
- 使用 soft scores 作为 targets 可以比 binary targets 更利于训练,因为 soft scores 可以捕捉到在 ground truth 标注中出现的一些偶然不确定情况
Pretraining the classifier
训练过程中,学习矩阵
w
o
w_o
wo 的一行对应一个候选答案。为了使预测更准确,从两个方面使用候选答案的先验信息初始化
w
o
w_o
wo 的行:
- 从语言学的角度,作者利用了每个答案的 GloVet word embeddings 作为特征。如果出现答案不能和预先训练好的 embedding 精确匹配时,作者会在检查拼写、删除连字符号或从多单词表达中保留单个表达后使用最近匹配,得到的结果记为
w
o
t
e
x
t
w_o^{text}
wotext,大小为 300
- 从视觉的角度,利用 Google 搜索与候选答案相关的 10 张图片,然后送入预训练好的 ResNet-101 上提取特征,将 mean-pool 处理后的 10 个特征做平均,产生一个大小为 2048,记为
w
o
i
m
g
w^{img}_o
woimg
有了预设计好的
w
o
t
e
x
t
w_o^{text}
wotext 和
w
o
i
m
g
w_o^{img}
woimg,然后在训练集上使用小学习(0.5 和 0.01)率微调。最终,我们有如下的组合方式
s
^
=
σ
(
w
o
t
e
x
t
f
o
t
e
x
t
(
h
)
+
w
o
i
m
g
f
o
i
m
g
(
h
)
)
\hat s=\sigma\left(w_o^{text}f_o^{text}(h)+w_o^{img}f_o^{img}(h)\right)
s^=σ(wotextfotext(h)+woimgfoimg(h))
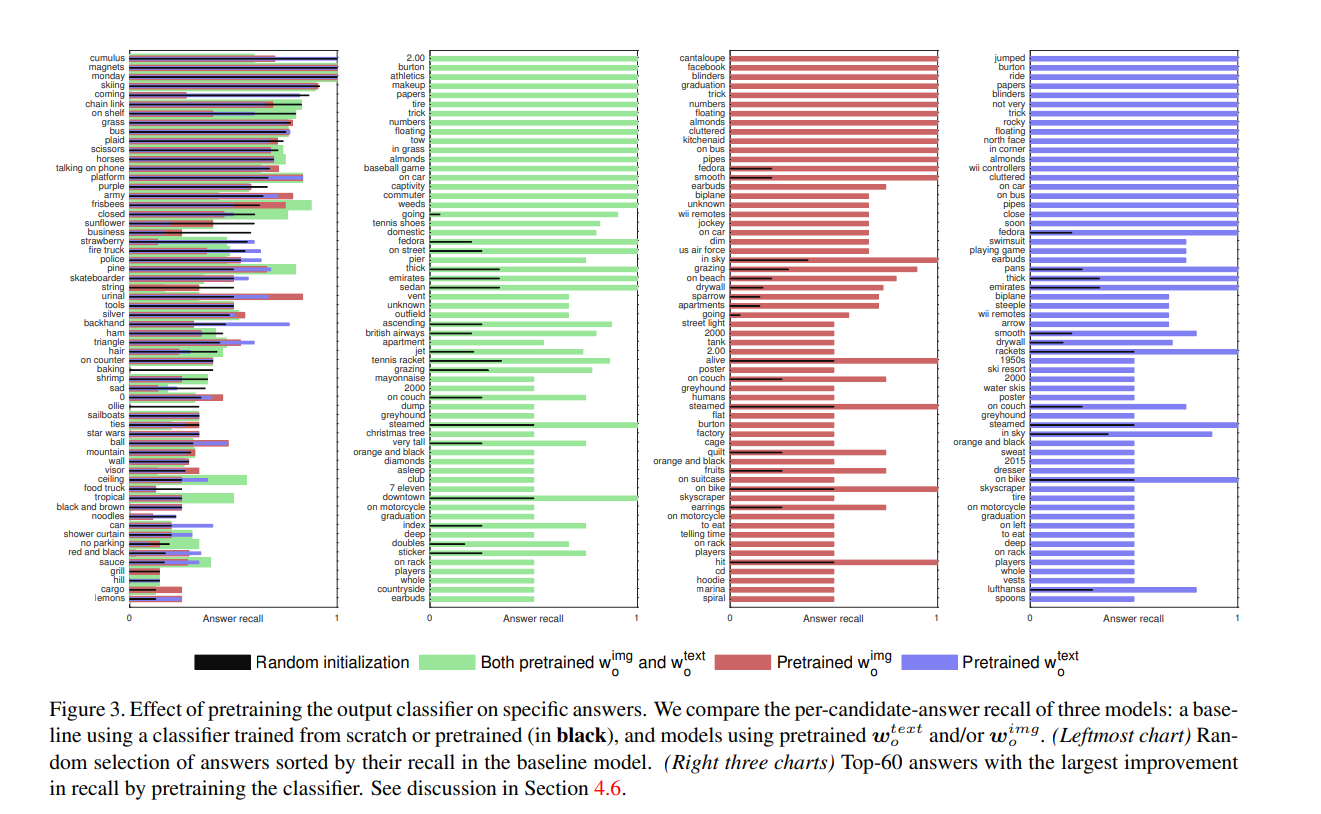
下图展示了引入 pretrained
w
o
t
e
x
t
w_o^{text}
wotext 和
w
o
i
m
g
w_o^{img}
woimg 的结果
Non-linear layers
前面一直提到了一个非线性变换层,通常的做法是使用 FC + ReLU
但是文中作者受 LSTM 和 GRU 中门函数的启发,提出了下面的 gated hyperbolic tangent activatio,每一个非线性变换层
f
a
:
x
∈
R
m
→
y
∈
R
n
f_a:x\in\mathbb R^m\rightarrow y\in\mathbb R^n
fa:x∈Rm→y∈Rn 定义为
y
~
=
t
a
n
h
(
W
x
+
b
)
g
=
σ
(
W
′
x
+
b
′
)
y
=
y
~
∘
g
\tilde y=tanh(Wx+b)\\ g=\sigma(W'x+b')\\ y=\tilde y\circ g
y~=tanh(Wx+b)g=σ(W′x+b′)y=y~∘g 其中
g
g
g 可以被视为作用在中间激活
y
~
\tilde y
y~ 上的一个门函数,用于控制信息的有效传递
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)