已剪辑自: https://zhuanlan.zhihu.com/p/99609634
微信公号:Mat物语科研数据分析
☆阅读本文最好需要提前了解(一点点)的一些知识点(不懂也可以阅读)
(1)插值法:利用函数f (x)在某区间中插入若干点的函数值,作出适当的特定函数,在这些点上取已知值,在区间的其他点上用这特定函数的值作为函数f (x)的近似值。
(2)神经网络:一种万能逼近模型。当代人工智能、深度学习的核心。这个概念没接触过的同学一两句话肯定解释不清楚。
(3)克里金模型:最早于地质统计学领域被提出,一种实用空间估计技术,也属于插值法的一种。
(4)响应面模型:采用多元回归方程来拟合因素与响应值之间的函数关系,通过对回归方程的分析来寻求最优工艺参数。
(5)径向基函数:一种将试验点与未知点之间的欧氏距离作为径向函数的输入。通过借用欧氏距离作为中转机制,将多维问题转换成一维问题,从而降低了模型的复杂度。满足这些条件的函数都可以看为径向基函数,所以径向基函数有很多种。
在试验中试图构建数学模型时,有时会遇到以下情况:
1、存在实际的数学模型,但我们并不知道其具体的、显式的表达式(类别),无法参数化表达式。手上只获得了一些数据,且数据的获得成本很高。这种普遍存在的现象称之为“黑箱”。打个比方,设计汽车并测试碰撞安全,设计参数(车速、框架结构、刹车等)和碰撞程度间存在的准确数学模型未知。如何获得更多数据?只要用这些参数造一辆汽车再往墙上一撞就欧啦。好家伙,获得一组数据需要报废一辆车。这就叫数据获得成本高。
2、已知实际的数学模型类型,但其非常复杂,因此在变量具有较高维度时,计算速度十分缓慢(即使是用计算机来计算)。这也叫数据获得成本高(时间成本)。
代理优化,或者叫代理模型,指在分析和优化设计过程中可替代那些复杂而费时的模型的近似学习模型。最早,代理模型的雏形是多项式响应面模型(用的人很多,其实往往你已经在采用代理模型的思维方式,只是你自己没有意识到)。随着技术的发展,代理模型不再仅仅是简单的替代,而是构成了一种基于历史数据来驱动样本点加入,以逼近全局最优解的优化机制。同时,复杂多维问题的代理模型不必在整个设计空间都具有高近似度,而是只需要在全局最优解附近实现高近似度[1]。
代理模型目前已经发展出多项式响应面、多项式插值、克里金插值、径向基函数插值、神经网络、支持向量机回归等多种方法。
这其中,多项式响应面、多项式插值接近于回归拟合领域,比较简单。支持向量机回归(相对于分类支持向量机)其应用较少,在此不做讨论。
神经网络作为一套独立的体系,应该说其对原模型的近似程度最高,随着节点和隐含层的增多,实现模型的完美逼近。不过其运算速度也不会很快,且可解释性差,很多网络本身就是一个黑箱。最终,你用一个黑箱,逼近了另一个黑箱。
克里金插值和径向基函数插值是目前应用较多的两种方法。克里金模型又称高斯随机过程模型。我在之前的一篇文章中已经做了较详细的描述。(功能强大的回归模型——高斯过程回归)为啥名称有差别?我个人的理解是克里金的叫法强调插值的思路,高斯过程回归强调回归的思路。在强大的“高斯过程核(比如matern核)”的作用下,插值和回归的区别已经不那么显著了。
本文主要介绍径向基函数代理优化算法(以下简称代理优化)。
首先需要注意的是:代理优化算法必须具有边界约束。如果所求问题不具有边界约束,则可以选择以-1000到1000作为默认边界。目标函数不一定非要是平滑的,但当目标函数是连续的时,算法的效果最好。代理优化的目的是尝试仅使用很少次的目标函数计算,来寻找目标函数的全局最小值。为此,算法将试图在“探索”和“速度”两个目标之间平衡本次优化过程。
代理优化算法分为串行算法和并行算法。其中串行算法是基础和核心,本文只介绍串行代理优化。
算法将在两个阶段之间交替进行。以下是简述版步骤:
(1)构造代理阶段:首先在边界范围内,创建数个随机的点(较少),并在这些点上计算目标函数。通过这些点,插值一个径向基函数来构造目标函数的一个“代理函数”。
(2)搜索最小值阶段:在边界范围内,随机抽样较多个点。根据这些点的“代理值”以及它们与目标函数已知的点之间的距离,来估计一个优值函数(merit function)。以优值函数的全局最优点作为“候选点”。在“候选点”计算目标函数。并称之为“适应点”。以此值更新代理,并再次搜索。在一定条件下,进行“代理重置”,返回步骤(1)
以下是算法的详细内容:
一、术语
(1)目标函数:真实的模型。代理优化最终的目的,还是要求目标函数的全局最优值。代理优化和其它模型最大的不同,就是目标函数是未知的,或者虽然可以求解,但计算起来昂贵、费时。
(2)代理函数(Surrogate function,“S”):目标函数的“代理”,化繁为简。此处采用径向基插值函数作为代理函数。
(3)当前值:目标函数最近一次被计算过的点。
(4)在职点(Incumbent point):在最近的一次“代理重置”后,目标函数值最小的点。这个翻译是我暂译的。Incumbent point是理解模型的关键概念。
(5)最优点:算法开始以来所有计算目标函数值中的最小的点。算法结束时的最优点就是我们最终的全局最优解。
(6)初始点:在算法开始之前,你传递给算法的一些已知目标函数值的点,初始点不是必须的。
(7)随机点:构造代理阶段,算法将在这些点计算目标函数。一般来说,算法会从伪随机序列中获取这些点,并进行缩放和位移。以保证在边界的要求范围内。特别的,当变量极多时(往往需要超过500个),算法将从拉丁超立方体序列中获取点。(关于拉丁超立方体,请看实验设计方法(二)——拉丁超立方体简介)
(8)自适应点:即“搜索最小值”阶段的点。在此处,算法对目标函数求值。
(9)优值函数(merit function):后面详细介绍。这个翻译是我暂译的。
(10)已计算点:或者叫已知值点,即目标函数已知的所有点,包括初始点、构造代理点和搜索最小值阶段计算过的点。
(11)采样点:即算法在最小值搜索阶段对“优值函数”求值的点,这些点计算过的是优值函数,而不是目标函数。
(12)比例(scale):搜索最小值阶段的一个量化参数。
二、算法步骤
算法将在两个阶段之间交替进行。
1、构造代理阶段
算法首先会在边界内选择一些准随机点。如果你有一些初始点,那么算法会用上这些点。获得总共N个点(这个数也是由你设置的),随后,算法将在这些点上计算目标函数。因为计算目标函数的代价高昂,因此N并不需要选择太大。
径向基函数代理优化算法采用径向基函数(RBF)插值器,以构造目标函数的插值代理。常用的径向基函数均可以在代理优化模型中选择。比如:
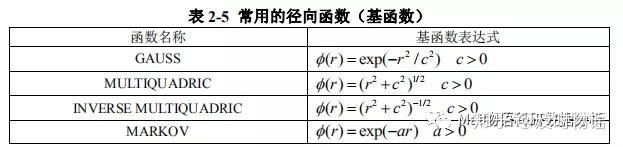
但Matlab选了最适合的一个。其使用的是一个带有线性尾部的立方RBF,此函数使得图像颠簸的程度最小化。读到这里大家已经有一个疑问了。为什么要选RBF函数呢?因为RBF有几个方便的属性,使他是最适合构建代理的函数。
(1)RBF插值器在任意维数、任意点数的情况下,都使用相同的定义公式。
(2)在被计算的点一定可以取到指定的值。意思就是这些点一定可以用RBF进行插值拟合。
(3)计算一个RBF插值器在时间上的花费极少。
(4)当你已经有了一个RBF插值器,那么在已有插值表达式中添加一个点所需要的时间相对较少。
(5)构造一个RBF插值器将涉及到求解一个N*N的线性系统方程组。其中N是代理点的数量。对于RBF,该系统有唯一解。
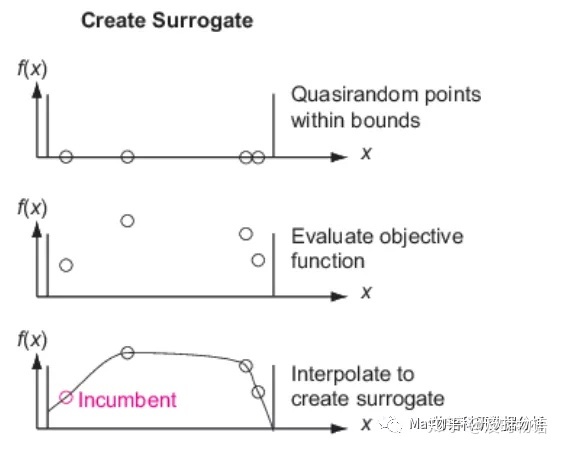
构造代理阶段的示意图(1)在边界内以伪随机方式取点(2)在这些点计算目标函数 (3)使用插值创建“代理”
2、搜索最小值阶段
算法通过一个局部搜索的过程,来搜索目标函数的最小值。“比例(scale)”类似于模式搜索中的“半径”或者“网格”的大小。Matlab里,比例的初始值一般设置为0.2。算法会从“在职点”开始进行。在职点是最近一次代理重置以来,目标函数的最小值所在点。
算法搜索“优值函数”的最小值。优值函数是一个同时关联代理和已搜索值的距离的函数,以平衡“最小化代理”和“搜索空间(广泛度)”两个任务。
算法将成百上千个长度为比例(比如0.2)的伪随机向量。加在在职点上。以得到样本点。这些向量为正态分布的,再在每个维度上依据边界进行移动和缩放。如果的采样点掉到了边界外,算法将会改变采样点。使它们保持在边界内。
然后,算法在这些样本点,计算优值函数。
上一步中,优值函数最低的点被称为自适应点。算法将在自适应点计算目标函数值,并用该值更新“代理”。如果“自适应点”处的目标函数值低于在职点,则算法认为本次搜索“成功”。并将自适应点设为新的在职点。否则,算法认为搜索失败,不会改变在职点。(好吧,在职点这个翻译真的不怎么样,大家将就一下,记住英文Incumbent point)
当满足以下条件时,算法将改变“比例”的值。
(1)自上一次比例变化以来,已经进行了累计三次成功的搜索。此时将比例加倍。直到最大比例,其长度为边界所框定的箱型大小的0.8倍。
(2)在上一次比例变化后,已有max(5,n)次不成功的搜索(n为变量维度)。此时,将比例减半。直到最小比例长度为边界所框定的箱型大小的0.00001倍。
如此反复,随机搜索将最终集中在目标函数值最小的在职点附近。并且最终比例将减小到最小规模。
需要注意的是,算法不会计算任何与已知值点距离在一定范围内的优值函数。而当所有的样本点都在已知值点的这个特定范围内时,算法从搜索最小值阶段重新切换到构造代理阶段。这就叫做“代理重置”。通常这种重置发生在算法的scale缩小以后,因此所有的样本点都紧紧聚集在在职点的周围。
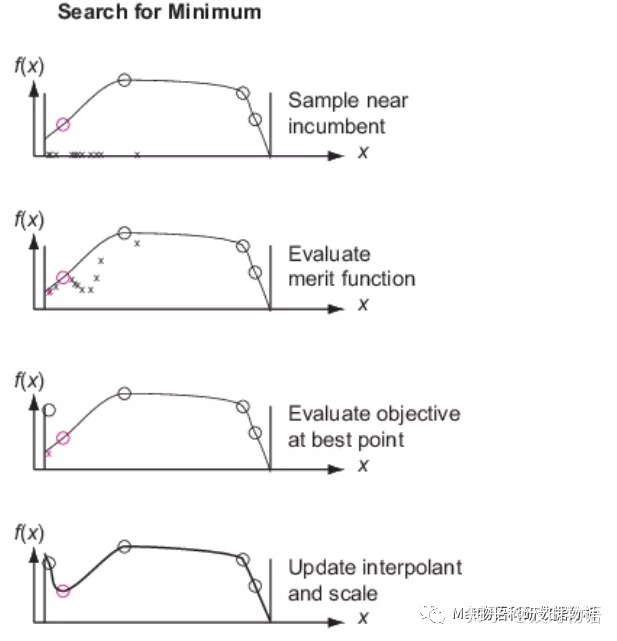
搜索最小值阶段的示意图(1)在在职点周围取样 (2)计算优值函数 (3)在自适应点计算目标函数 (4)更新插值代理和比例
三、优值函数(merit function)简介
优值函数是代理优化的重要概念。优值函数同时关联代理和已搜索值的距离的函数,以平衡“最小化代理”和“搜索空间(广泛度)”两个任务。优值函数fmerit(x)是以下两项的加权组合:
(1)“比例化代理”:定义Smin为采样点之间的“最小代理值”。Smax为采样点之间的“最大代理值”。Sx为x处的代理值。则比例化代理S(x)为:

S(x)非负,且代理值最小的样本点S(x)值为0。(最小化代理的能力)
(2)“比例化距离”:定义xj为k个已知值点,定义dij为点i与已知值点
dmin = min(dij)
dmax = max(dij)
即对于所有ij的极大和极小距离,则规范化距离D(x)为
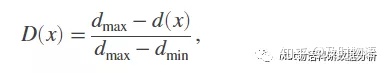
其中d(x)为点x到已知值点的最小距离
D(x)非负,且当点x距离所有已知值点最远时,D(x)为0.
因此,最小化D(x),算法就会去找那些离已知值点最远的点。(搜索空间的能力)
优值函数为以上两项的加权和。对于一个小于1的权重w,优值函数
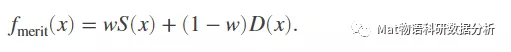
(1)较大的w将使算法重视代理,将导致搜索趋向代理的最小值。
(2)较小的w将使算法重视探索较远的新领域,从而将搜索引向新区域。在Matlab中,默认w将在0.3、0.5、0.7、0.95这四个数上依次循环。这样就做到了兼顾两种目的。
四、总结
代理优化算法是专门用于应对高代价而耗时的目标函数的一种近似算法。一个代理模型是一个近似于目标函数的函数(至少在最小值点附近如此)。代理模型只需要很少的时间来计算。要搜索目标函数最小化的点。只需要在较多个点上对代理函数进行求值。并将最佳值作为目标函数最小化值的近似值。代理优化算法已被证明可以收敛于有界域上连续目标函数的全局最优解。不过其收敛并不快(还是比直接计算目标函数的算法快的多)。
目前来说,代理优化算法应用的范围相对较少,属于十分冷门的一种算法。相对应的,关于代理优化算法的论文也较少。然而,我个人比较看好它在未来的发展,将会越来越多地被应用在各领域的模型试验中。最终,代理优化发展成一门通用优化模型。成为面对任务未知问题时的一种研究策略。是的,这不仅仅是一种模型,也是一种战略上思维的方式。
这应该是我在2019年的最后一篇文章,感谢各位小伙伴不离不弃,一直以来的支持。各位,我们2020再见。
在论文数据库中搜索以“代理优化”为关键词的中文论文只有3篇,若以Surrogate optimization为关键词搜索英文论文,则搜到513篇
http://weixin.qq.com/r/QB21rSLE5H_brWbO90hS (二维码自动识别)
参考文献:
1.韩忠华.Kriging模型及代理优化算法研究进展.航空学报,2016,37(11).
2.[https://ww2.mathworks.cn/help/gads/surrogate-optimization-algorithm.html
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)