##使用HDFS的Java接口进行文件的读写。
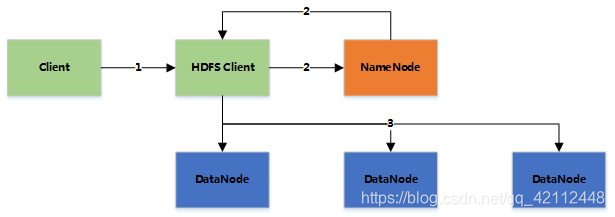
FileSystem对象
要从Hadoop文件系统中读取文件,最简单的办法是使用java.net.URL对象打开数据流,从中获取数据。不过这种方法一般要使用FsUrlStreamHandlerFactory实例调用setURLStreamHandlerFactory()方法。不过每个Java虚拟机只能调用一次这个方法,所以如果其他第三方程序声明了这个对象,那我们将无法使用了。因为有时候我们不能在程序中设置URLStreamHandlerFactory实例,这个时候咱们就可以使用FileSystem API来打开一个输入流,进而对HDFS进行操作。
使用FileSystem,查看上传的文件。
public sattic void main(String[] args){
URI uri = URI.create("hdfs://localhost:9000/user/tmp/test.txt");
Configuration config = new Configuration();
FileSystem fs = FileSystem.get(uri, config);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 2048, false);
} catch (Exception e) {
IOUtils.closeStream(in);
}
}
FileSystem是一个通用的文件系统API,FileSystem实例有下列几个静态工厂方法用来构造对象。
public static FileSystem get(Configuration conf)throws IOException
public static FileSystem get(URI uri,Configuration conf)throws IOException
public static FileSystem get(URI uri,Configuration conf,String user)throws IOException
Configuration对象封装了客户端或服务器的配置,通过设置配置文件读取类路径来实现(如:/etc/hadoop/core-site.xml)。
第一个方法返回的默认文件系统是在core-site.xml中指定的,如果没有指定,就使用默认的文件系统。
第二个方法使用给定的URI方案和权限来确定要使用的文件系统,如果给定URI中没有指定方案,则返回默认文件系统,
第三个方法作为给定用户来返回文件系统,这个在安全方面来说非常重要。
FSDataInputStream对象
实际上,FileSystem对象中的open()方法返回的就是FSDataInputStream对象,而不是标准的java.io类对象。这个类是继承了java.io.DataInputStream的一个特殊类,并支持随机访问,由此可以从流的任意位置读取数据。
在有了FileSystem实例之后,我们调用open()函数来获取文件的输入流。
public FSDataInputStream open(Path p)throws IOException
public abst\fract FSDataInputStream open(Path f,int bufferSize)throws IOException
第一个方法使用默认的缓冲区大小为4KB。
示例代码
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class FileSystemCat {
public static void main(String[] args) throws Exception{
URI uri = URI.create("hdfs://localhost:9000/user/tmp/test.txt");
Configuration config = new Configuration();
FileSystem fs = FileSystem.get(uri, config);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 2048, false);
} catch (Exception e) {
IOUtils.closeStream(in);
}
}
}
##使用HDFSAPI上传文件至集群
FSDataOutputStream对象
Java中要将数据输出到终端,需要文件输出流,HDFS的JavaAPI中也有类似的对象。
FileSystem类有一系列新建文件的方法,最简单的方法是给准备新建的文件制定一个path对象,然后返回一个用于写入数据的输出流:
public FSDataOutputStream create(Path p)throws IOException
该方法有很多重载方法,允许我们指定是否需要强制覆盖现有文件,文件备份数量,写入文件时所用缓冲区大小,文件块大小以及文件权限。
注意:create()方法能够为需要写入且当前不存在的目录创建父目录,即就算传入的路径是不存在的,该方法也会为你创建一个目录,而不会报错。如果有时候我们并不希望它这么做,可以先用exists()方法先判断目录是否存在。
在写入数据的时候经常想要知道当前的进度,API也提供了一个Progressable用于传递回调接口,这样我们就可以很方便的将写入datanode的进度通知给应用了。
package org.apache.hadoop.util;
public interface Progressable{
public void progress();
}
IOUtils.copyBytes(in, out, 4096, false)方法实现了文件合并及上传至hdfs上
IOUtils.copyBytes(in, out, 4096, false)
–in:是FSDataInputStream类的对象,是有关读取文件的类,也就是所谓“输入流”
–out:是FSDataOutputStream类的对象,是有关文件写入的类,也就是“输出流”
–4096表示用来拷贝的buffer大小(buffer是缓冲区)–缓冲区大小
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import java.io.File;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Progressable;
public class FileSystemUpload {
public static void main(String[] args) throws IOException {
//请在 Begin-End 之间添加代码,完成任务要求。
/********* Begin *********/
File localPath=new File("/develop/test.txt");
String hdfsPath ="hdfs://localhost:9000/user/hadoop/test.txt";
InputStream in=new BufferedInputStream(new FileInputStream(localPath));
//获取输入流对象
Configuration config=new Configuration();
FileSystem fs=FileSystem.get(URI.create(hdfsPath),config);
long fileSize=localPath.length() > 65536 ? localPath.length()/65536 :1;
//待上传文件大小
FSDataOutputStream out =fs.create(new Path(hdfsPath),new Progressable(){
//方法在每次上传了64KB字节大小的文件之后会自动调用一次
long fileCount=0;
public void progress(){
System.out.println("总进度"+(fileCount/fileSize)*100+"%");
fileCount++;
}
});
IOUtils.copyBytes(in,out,2048,true);//最后一个参数的意思是使用完之后是否关闭流
}
}
##删除HDFS中的文件和文件夹
列出文件
我们在开发或者维护系统时,经常会需要列出目录的内容,在HDFS的API中就提供了listStatus()方法来实现该功能。
public FileStatus[] listStatus(Path f)throws IOException
public FileStatus[] listStatus(Path f,PathFilter filter)throws IOException
public FileStatus listStatus(Path[] files)throws IOException
public FileStatus() listStatus(Path[] files,PathFilter filter)throws IOException
当传入参数是一个文件时,他会简单的转变成以数组方式返回长度为1的FileStatus对象,当传入参数是一个目录时,则返回0或多个FileStatus对象,表示此目录中包含的文件和目录。
listStatus()方法的使用:
public static void main(String]args)throws IOException {
string uri ="hdfs://localhost:9000/";//HDFS根目录
string path1 ="hdfs://localhost:9000/user";
Configuration config = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri),config);
Path[]paths ={new Path(uri),new Path(path1)};//构建要显示目录的数组
Filestatus[1 status = fs.liststatus(paths);
Path[]listPaths = Fileutil.stat2Paths(status);
for(Path path:listPaths){
system.out.println(path):
删除文件
使用FileSystem的delete()方法可以永久性删除文件或目录。
public boolean delete(Path f,boolean recursive)throws IOException
如果f是一个文件或者空目录,那么recursive的值可以忽略,当recursize的值为true,并且p是一个非空目录时,非空目录及其内容才会被删除(否则将会抛出IOException异常)。
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
public class FileSystemDelete {
public static void main(String[] args) throws IOException {
String uri="hdfs://localhost:9000/";
String path3="hdfs://localhost:9000/user";
String path2="hdfs://localhost:9000/user/hadoop";
String path1="hdfs://localhost:9000/user/tmp";
Configuration config=new Configuration();
FileSystem fs=FileSystem.get(URI.create(uri),config);
fs.delete(new Path(path2),true);//删除
fs.delete(new Path(path3),true);//删除
Path[] paths={new Path(uri),new Path(path1)};
FileStatus[] status=fs.listStatus(paths);
Path[] listPaths=FileUtil.stat2Paths(status);
for (Path path:listPaths){
System.out.println(path);
}
}
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)