用Nastran的时候,想把bdf文件里的节点坐标导出来,但是坐标的格式很奇怪,见下图:
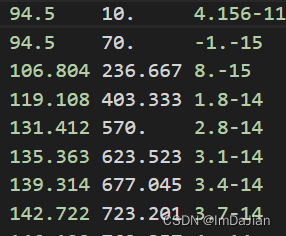
会发现这种科学计数法中间没有字母E或e,直接用Matlab中的load函数读取的话,会出现N/A。
于是写了个函数解决这个问题,代码如下:
function [xx,yy,zz] = Node(filename)
fid = fopen(filename,'r');
text = textscan(fid,'%s %d %8s %8s %8s');
fclose(fid);
nodeId = text{1,2}; %节点编号
numNode = length(nodeId); %节点数量
index = 1;
while index <= numNode
x = strsplit(text{1,3}{index,1},'-');
y = strsplit(text{1,4}{index,1},'-');
z = strsplit(text{1,5}{index,1},'-');
[~,cx] = size(x);
[~,cy] = size(y);
[~,cz] = size(z);
switch cx
case 1
%
case 2
if ~isempty(x{1,1})
text{1,3}{index,1} = [x{1,1},'e-',x{1,2}];
end
case 3
text{1,3}{index,1} = [x{1,2},'e-',x{1,3}];
end
%
switch cy
case 1
%
case 2
if ~isempty(y{1,1})
text{1,4}{index,1} = [y{1,1},'e-',y{1,2}];
end
case 3
text{1,4}{index,1} = ['-',y{1,2},'e-',y{1,3}];
end
%
switch cz
case 1
%
case 2
if ~isempty(z{1,1})
text{1,5}{index,1} = [z{1,1},'e-',z{1,2}];
end
case 3
text{1,5}{index,1} = ['-',z{1,2},'e-',z{1,3}];
end
index = index +1;
end
xx = str2double(string(text{1,3}));
yy = str2double(string(text{1,4}));
zz = str2double(string(text{1,5}));
end
思路是,先用textscan()将文本一次性读入,注意bdf中每个数都占8位,然后再用swich函数,分三种情况对这种奇怪的科学计数进行分割,加上“e”,变成正常的科学计数,最后转换成数字,很小的数就直接指定为0。结果如下图:

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)