求关注
求转发


经常跟数据打交道的同学,一定会非常熟悉Excel,它无疑是轻量级数据的分析神器,而当你需要处理的数据越来越大时,Excel是不是显得越来越力不从心、单个Sheet最大支持1048576行,V个大表各种等,还动不动未响应甚至直接奔溃;此时你一定需要一个更强大的工具来搞定大数据的处理,他就是今天的主角:Pandas
Pandas是专注于大数据分析和处理的Python包,在数据分析领域,可以说是大名鼎鼎,无人不知,无人不晓,它甚至是使Python成为强大而高效的数据分析工具的重要因素,今天我们先简单介绍它的一些基础的用法,你会发现它既简单,又好用。
1.Pandas的安装
Pandas属于Python的扩展包,默认是并没有集成的,所以我们需要先安装它,如果你使用的是Pycharm(我的入门系列2有安装配置教程),可以直接利用代码提示安装,
在联网状态下编辑器界面输入import pandas,此时pandas下方出现红色波浪线(代表有错误或模块未安装),此时将鼠标点击pandas切换编辑光标,点击红色提示,选择Install package pandas即开始安装
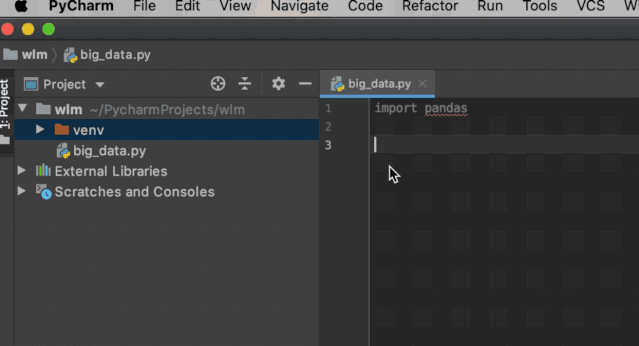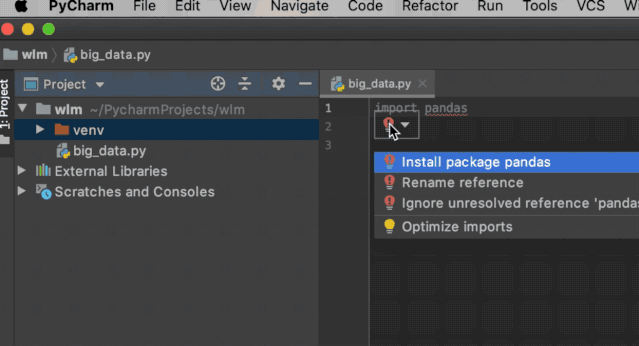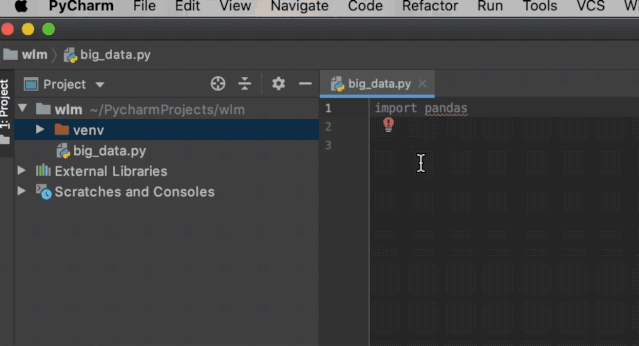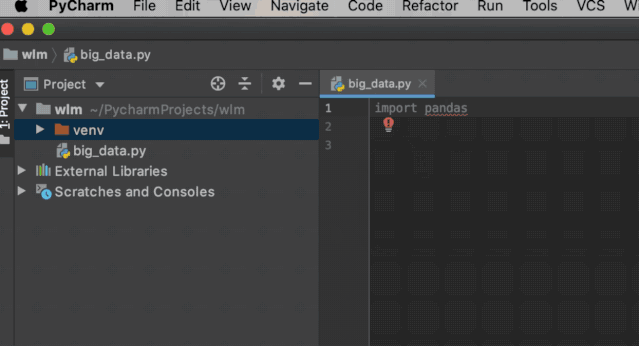
安装过程是没有提示的,可以点击右下角查看进度,安装完成后红色波浪线线及就会消失,同时运行时也不会出现ImportError: No module named pandas报错
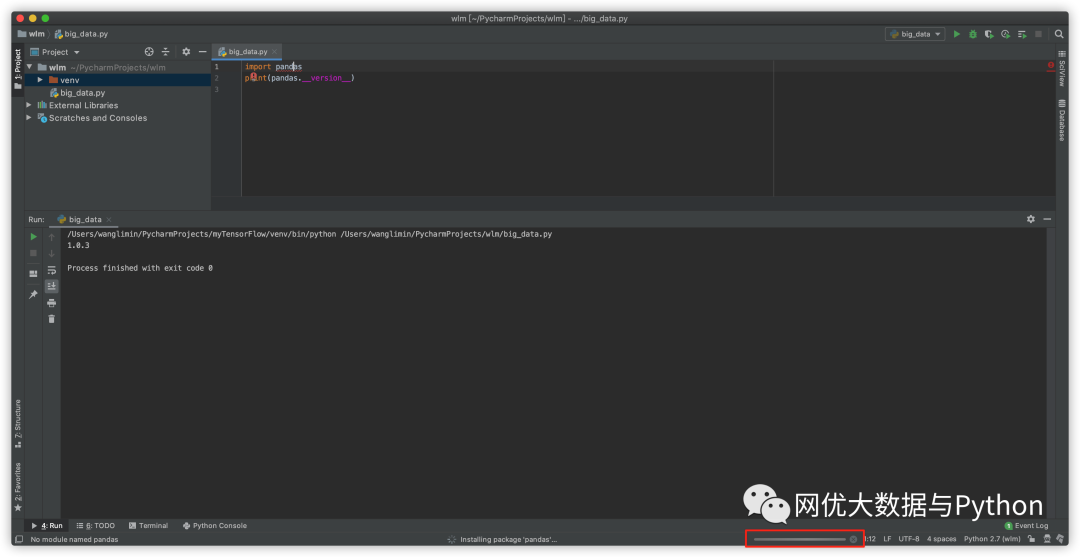
也可通过包管理器下载,点击左上角File→Setings→Preferences | Project: wlm | Project Interpreter→左下角+号→输入pandas选择后点击Install Package
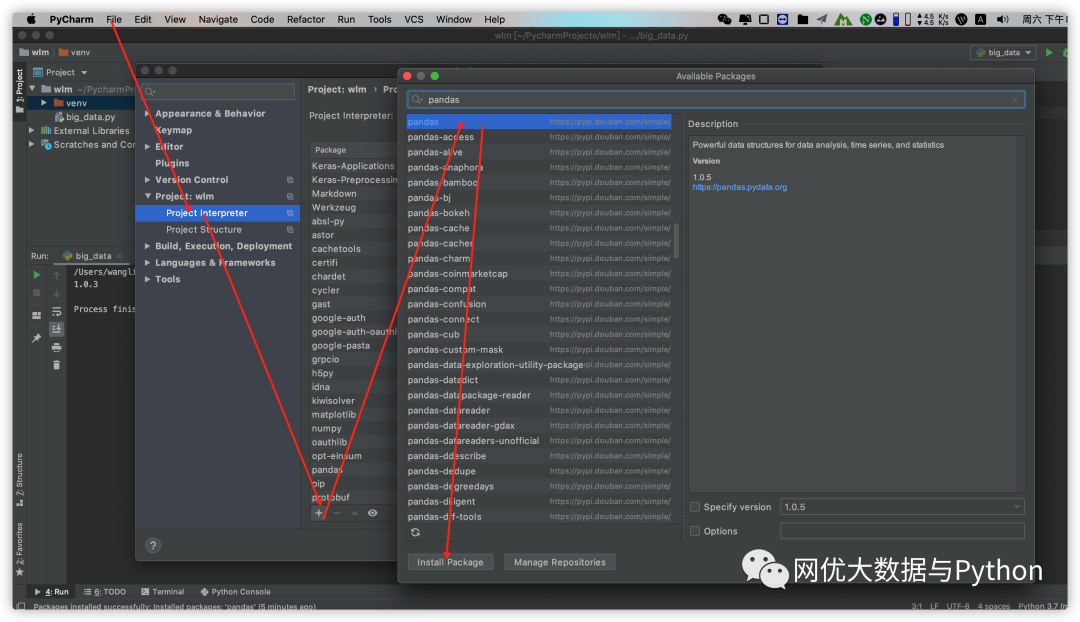
安装完毕后可以通过print(pandas.__version__)检查,如打印版本且未报错则为安装完成。
如果未使用任何IDE,可以直接在CMD输入pip3 Install pandas安装,这里不再赘述
2.数据源的读取
Pandas的Datefram(数据框,常存储二维数据)支持从多种数据源读取数据(Excel,CSV,数据库,网页等等),并且仅需要一行代码,本次先以Excel为例;
首先我们在Python导入Pandas,并命名为pd,同时安装并导入Excel的支持包xlrd(安装方式与Pandas方式相同)
import pandas as pdimport xlrd
我们以读取Excel文件为例(读取其他数据源也基本相同,只是参数稍有不同),我们先看读取Excel的参数,它多达24个之多,但通常我们需要的只有前面几个,其他的我们可以不写,让pandas使用默认值即可(所有带默认值的参数如果不写,pandas就用默认值)。
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None,usecols=None, squeeze=False, dtype=None,engine=None, converters=None, true_values=None,false_values=None, skiprows=None, nrows=None,na_values=None, keep_default_na=True, verbose=False,parse_dates=False, date_parser=None, thousands=None,comment=None, skipfooter=0, convert_float=True,
mangle_dupe_cols=True, **kwds, )
首先是参数IO,它在这里我们可以理解为需要读取的Excel文件的绝对路径,(文件路径是以r开头,紧跟用单引号或双引号包裹的文件路径,这里的r为禁止转义的写法,认为固定写法即可,将来会详细介绍),例如
data = pd.read_excel(r'c:\demo.xlsx')
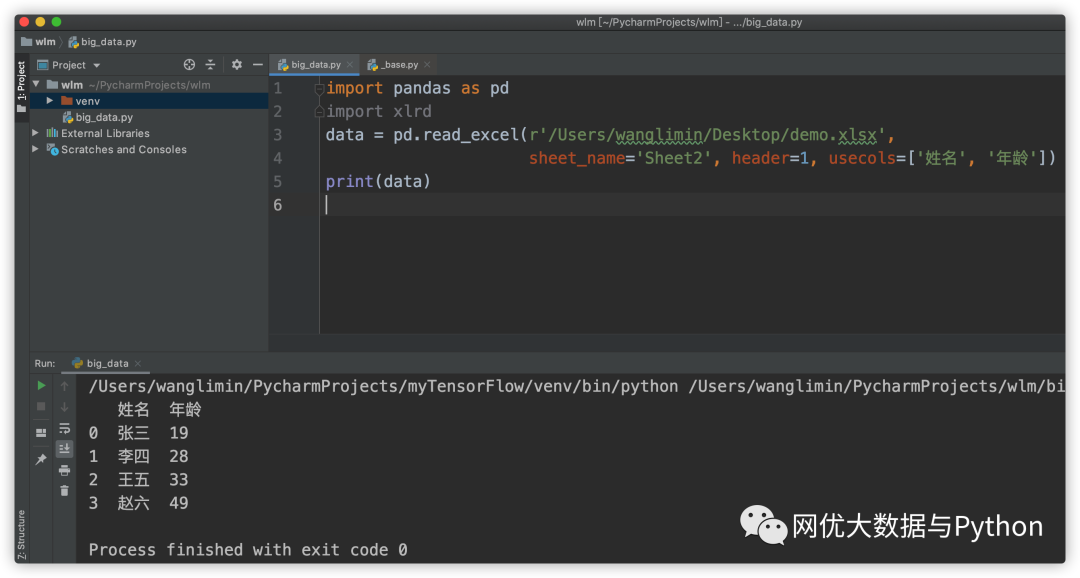
第二个参数,sheet_name,顾名思义,就是Excel的Sheet名称,如果忽略这个参数,Python默认读取第一个Sheet;第三个个参数header,就是使用Excel的第几行的参数作为列名(从0开始),默认为0,也就是第一行;第六个参数usecols代表读取Excel的哪些列,用列表传入,默认全部读取;以下面这个文件为例
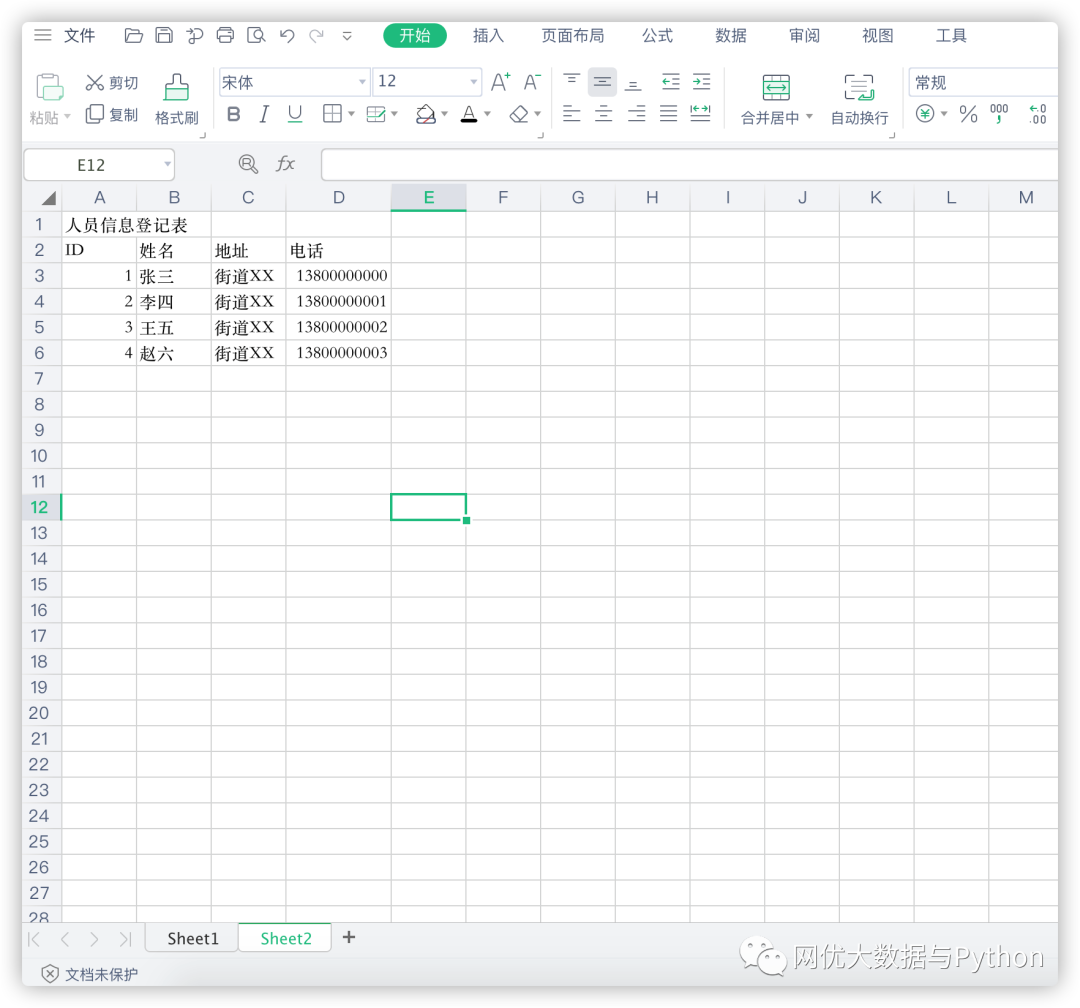
例如我们想读取上面这个桌面的"demo.xlsx"文件的Sheet2中的内容,使用第二列作为列名,只读取'姓名','年龄’这两列,则为
import pandas as pdimport xlrd
data = pd.read_excel(r'/Users/wanglimin/Desktop/demo.xlsx',
sheet_name='Sheet2', header=1,
usecols=['地址', '电话'])
打印查看,这里的第一列的0、1、2、3为pandas自动生成的index(行号),是不是很简单。
3.数据分析
pandas支持非常非常多的函数(这里用了两个非常,因为Pandas支持的函数是真的多),这里列出部分数字统计相关的函数。
| 函数 | 描述 |
|---|
count | 统计非空值数量 |
sum | 汇总值 |
mean | 平均值 |
mad | 平均绝对偏差 |
median | 算数中位数 |
min | 最小值 |
max | 最大值 |
mode | 众数 |
abs | 绝对值 |
prod | 乘积 |
std | 贝塞尔校正的样本标准偏差 |
var | 无偏方差 |
sem | 平均值的标准误差 |
skew | 样本偏度 (第三阶) |
kurt | 样本峰度 (第四阶) |
quantile | 样本分位数 (不同 % 的值) |
cumsum | 累加 |
cumprod | 累乘 |
cummax | 累积最大值 |
cummin | 累积最小值 |
例如我们想获取上文中"demo.xlsx"年龄的和,则
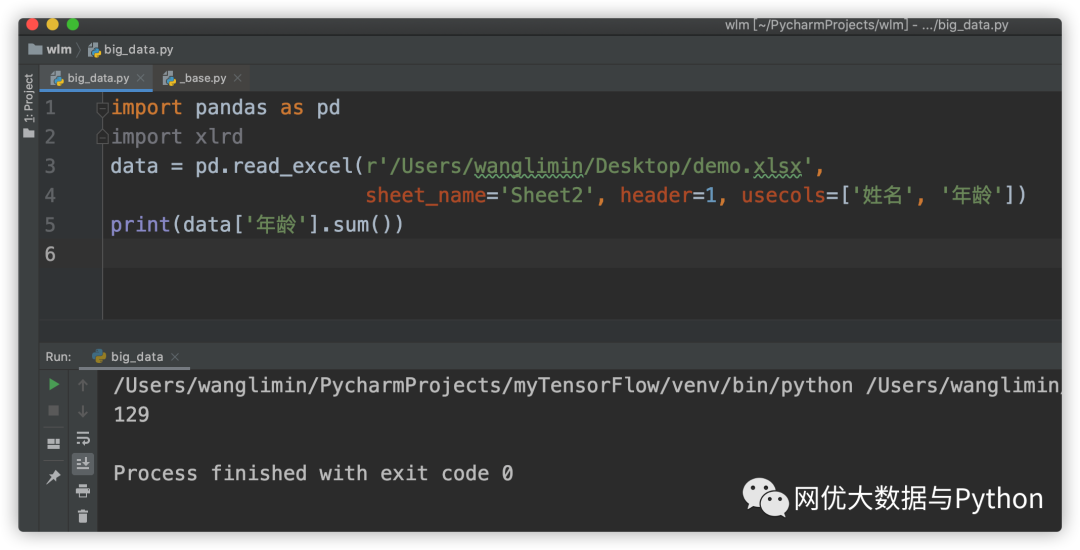
限于篇幅原因,对于类似于Excel的Vlookup等函数,后续再详细介绍
4.总结
对比Excel,把Pandas作为数据分析工具,不但可以增强数据处理的"量"与"效率",还能额外支持更多的花式操作与各种统计与运算,同时还可将数据融入Python,创造无限可能;受限于篇幅限制,本文仅简单介绍下Pandas,九牛一毛;后续会有更多关于Pandas的相关文章,有兴趣的同学也可以查看pandas中文网(http://www.pypandas.cn/docs/)的教程

今天,你转发锦鲤了吗?
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓