DataX和Oracle使用案例
文章目录
- DataX和Oracle使用案例
- 0. 写在前面
- 1. 从 Oracle 中读取数据存到 MySQL
- 1.1 MySQL 中创建表
- 1.2 编写 Datax 配置文件
- 1.3 执行命令
- 2. 读取 Oracle 的数据存入 HDFS 中
- 2.1 编写配置文件
- 2.2 执行命令
- 2.3 查看HDFS 结果
- 3. 总结
0. 写在前面
Oracle、MySQL数据库和DataX安装在一台机器node01上
DataX版本:DataX3.0(开源版)
Oracle版本:Oracle19c
说到数据库,我们都能想到类型分为关系型和非关系型数据库;Oracle和MySQL都是属于关系型数据库管理系统,在正文开始之前,有必要了解一下Oracle和MySQL在SQL方面的一些区别,以便参考
- 数据库Oracle 与 MySQL 的SQL 区别
| 类型 | Oracle | MySQL |
|---|
| 整型 | number(N)/integer | int/integer |
| 浮点型 | float | float/double |
| 字符串类型 | varchar2(N) | varchar(N) |
| NULL | ‘’ | null 和’'不一样 |
| 分页 | rownum | limit |
| "" | 限制很多,一般不让用 | 与单引号一样 |
| 价格 | 闭源,收费 | 开源,免费 |
| 主键自动增长 | × | √ |
| if not exists | × | √ |
| auto_increment | × | √ |
| create database | × | √ |
| select * from table as t | × | √ |
1. 从 Oracle 中读取数据存到 MySQL
1.1 MySQL 中创建表
进入MySQL交互界面,在oracle这个库下创建表student,字段为id和name,具体sql语句如下所示:
[oracle@node01 ~]$ mysql -uroot -p000000
mysql> create database oracle;
mysql> use oracle;
mysql> create table student(id int,name varchar(20));
1.2 编写 Datax 配置文件
编写配置文件 oracle2mysql.json
[oracle@node01 ~]$ vim /opt/module/datax/job/oracle2mysql.json
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": ["jdbc:oracle:thin:@node01:1521:orcl"],
"table": ["student"]
}
],
"password": "123456",
"username": "whybigdata"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://node01:3306/oracle",
"table": ["student"]
}
],
"password": "123456",
"username": "root",
"writeMode": "insert"
}
}
}
}
注意: jdbc:oracle:thin:@node01:1521:orcl 中的 orcl 指的是数据库名(安装Oracle数据库时设置的SID),同时要注意Oracle的数据库连接方式url的书写。
Linux安装Oracle数据库教程见下方链接:
https://juejin.cn/post/7197066611453804581
1.3 执行命令
执行命令如下 :
[oracle@node01 ~]$ /opt/module/datax/bin/datax.py /opt/module/datax/job/oracle2mysql.json
查看datax执行后MySQL中student表的数据结果:可以看到数据导入成功了
mysql> select * from student;
+ + +
| id | name |
+ + +
| 1 | zhangsan |
+ + +
数据从DataX导入MySQL数据库前后的对比
-
Oracle导入MySQL前后:
-
Oracle表student的数据:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DC83cDRA-1675910623327)(./1.jpg)]](https://img-blog.csdnimg.cn/d75579725b9744408c9bea414f406d7b.jpeg)
-
导入MySQL前表student的数据:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dFA53KI8-1675910623328)(./2.jpg)]](https://img-blog.csdnimg.cn/ffa90200ab72486ebfddb940708fa3ba.jpeg)
-
导入MySQL后表student的数据:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gbBWuYv6-1675910623329)(./3.jpg)]](https://img-blog.csdnimg.cn/391592ed35d34864ab22c69b8a1db674.jpeg)
2. 读取 Oracle 的数据存入 HDFS 中
2.1 编写配置文件
编写配置文件 oracle2hdfs.json
[oracle@node01 datax]$ vim job/oracle2hdfs.json
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": [
"*"
],
"connection": [
{
"jdbcUrl": [
"jdbc:oracle:thin:@node01:1521:orcl"
],
"table": [
"student"
]
}
],
"password": "000000",
"username": "atguigu"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"defaultFS": "hdfs://node01:8020",
"fieldDelimiter": "\t",
"fileName": "oracle.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
2.2 执行命令
执行命令如下:
[oracle@node01 datax]$ bin/datax.py job/oracle2hdfs.json
2.3 查看HDFS 结果
HDFS成功导入Oracle数据库表student的数据进入 oracle.txt_xxxxxxxxxxxxxxx文件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-55sP74PR-1675910623330)(./4.jpg)]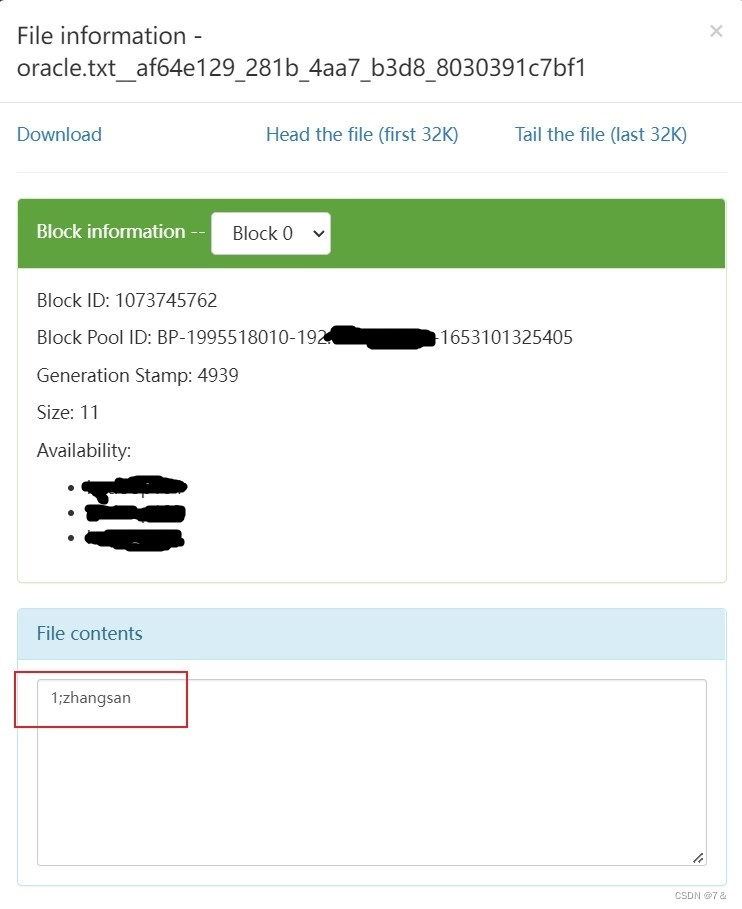
3. 总结
全文其实最主要的是Oracle数据库是否成功安装,这是最关键的一点,完成了这一步骤,DataX和其他数据库之间的数据导入导出本质上是一样的,都是通过模板配置文件来实现操作,大同小异。
全文结束!
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)