文章目录
- 1. unordered_map的介绍和使用
- 🍑 unordered_map的构造
- 🍑 unordered_map的使用
- 🍅 insert
- 🍅 operator[ ]
- 🍅 find
- 🍅 erase
- 🍅 size
- 🍅 empty
- 🍅 clear
- 🍅 swap
- 🍅 count
- 2. unordered_multimap的介绍和使用
-
1. unordered_map的介绍和使用
unordered_map 的介绍:
- unordered_map 是存储
<key, value> 键值对的关联式容器,其允许通过keys快速的索引到与其对应的 value。 - 在 unordered_map 中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此键关联。键和映射值的类型可能不同。
- 在内部,unordered_map 没有对
<kye, value> 按照任何特定的顺序排序,为了能在常数范围内找到 key 所对应的 value,unordered_map 将相同哈希值的键值对放在相同的桶中。 - unordered_map 容器通过 key 访问单个元素要比 map 快,但它通常在遍历元素子集的范围迭代方面效率较低。
- unordered_map 实现了直接访问操作符(
operator[]),它允许使用 key 作为参数直接访问 value。 - 它的迭代器至少是前向迭代器。
🍑 unordered_map的构造
构造一个 unordered_map 容器对象,根据使用的构造函数版本初始化其内容,我们主要掌握 3 种方式即可:
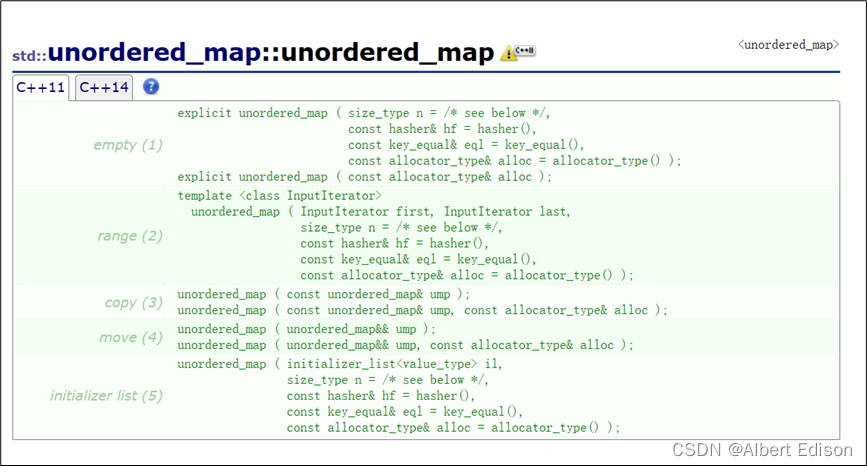
(1)构造一个某个类型的空容器
unordered_map<string, int> um1;
(2)拷贝构造某类型容器
unordered_map<string, int> um1({ {"apple", 1}, {"lemon", 2}});
unordered_map<string, int> um2(um1);
(3)使用迭代器区间进行初始化构造
构造一个 unordered_map 对象,其中包含范围 [first,last) 中每个元素的副本。
unordered_map<string, int> um1({ {"apple", 1}, {"lemon", 2}});
unordered_map<string, int> um3(um1.begin(), um1.end());
🍑 unordered_map的使用
unordered_map 的成员函数主要分为:迭代器,容量操作,修改操作。
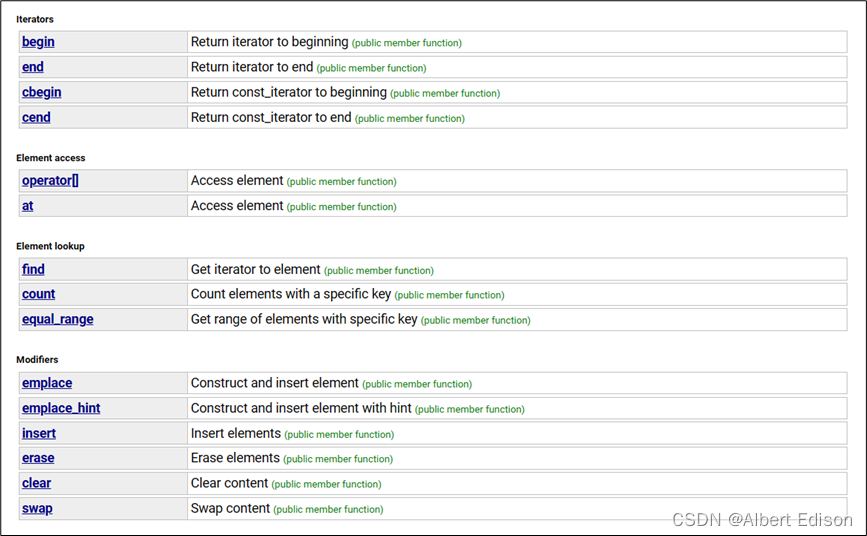
我这里只列举几个常用的,其它的可以看 文档 学习。
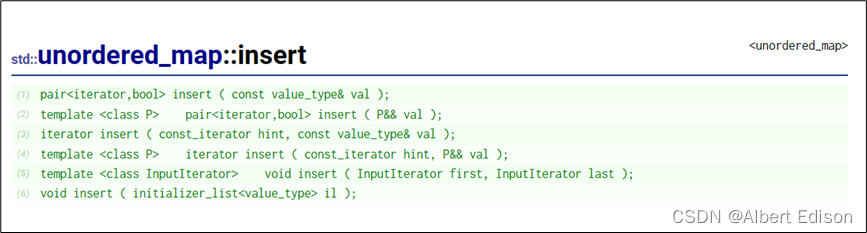
🍅 insert
在 unordered_map 中插入新元素。
只有当每个元素的键不等同于容器中已经存在的任何其他元素的键时,才会插入它,也就是说 unordered_map 中的键是唯一的。
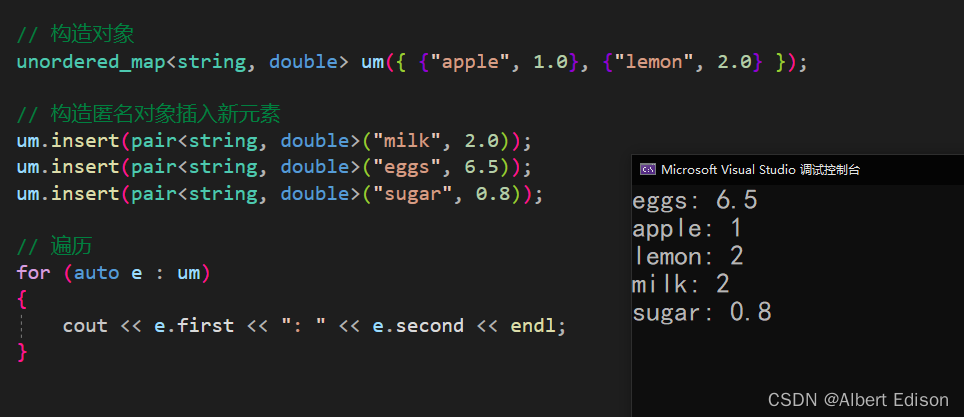
(1)构造匿名对象插入
void test_unordered()
{
unordered_map<string, double> um({ {"apple", 1.0}, {"lemon", 2.0} });
um.insert(pair<string, double>("milk", 2.0));
um.insert(pair<string, double>("eggs", 6.5));
um.insert(pair<string, double>("sugar", 0.8));
for (auto e : um)
{
cout << e.first << ": " << e.second << endl;
}
}
运行结果
(2)调用 make_pair 函数模板插入
void test_unordered()
{
unordered_map<string, double> um({ {"apple", 1.0}, {"lemon", 2.0} });
um.insert(make_pair("milk", 2.0));
um.insert(make_pair("eggs", 6.5));
um.insert(make_pair("sugar", 0.8));
for (auto e : um)
{
cout << e.first << ": " << e.second << endl;
}
}
运行结果

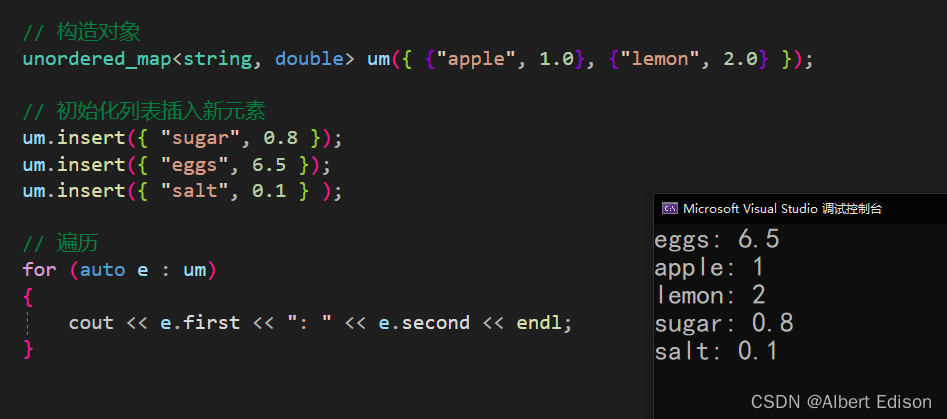
(3)初始化列表插入
void test_unordered()
{
unordered_map<string, double> um({ {"apple", 1.0}, {"lemon", 2.0} });
um.insert({ "sugar", 0.8 });
um.insert({ "eggs", 6.5 });
um.insert({ "salt", 0.1 } );
for (auto e : um)
{
cout << e.first << ": " << e.second << endl;
}
}
运行结果
🍅 operator[ ]
如果 k 与容器中元素的键匹配,则函数返回对其映射值的引用。
如果 k 与容器中任何元素的键不匹配,该函数将插入一个具有该键的新元素,并返回对其映射值的引用。
注意:这总是将容器大小增加 1,即使没有为元素分配映射值(使用默认构造函数构造元素)。

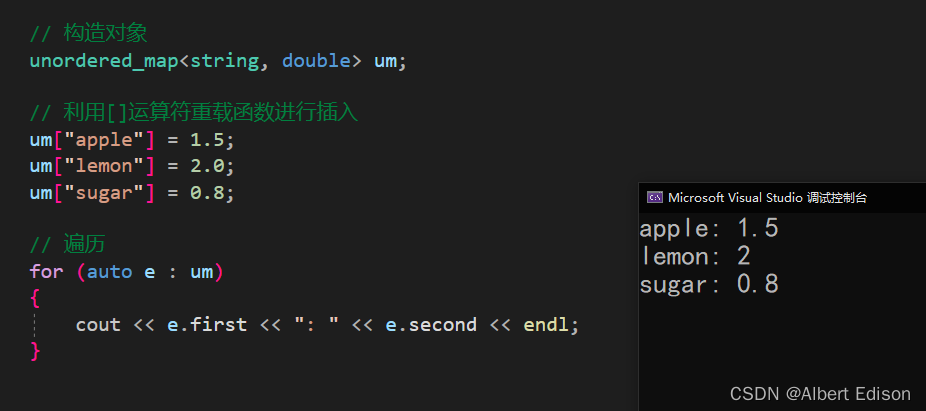
(1)利用 [] 运算符重载函数进行插入
void test_unordered()
{
unordered_map<string, double> um;
um["apple"] = 1.5;
um["lemon"] = 2.0;
um["sugar"] = 0.8;
for (auto e : um)
{
cout << e.first << ": " << e.second << endl;
}
}
运行结果
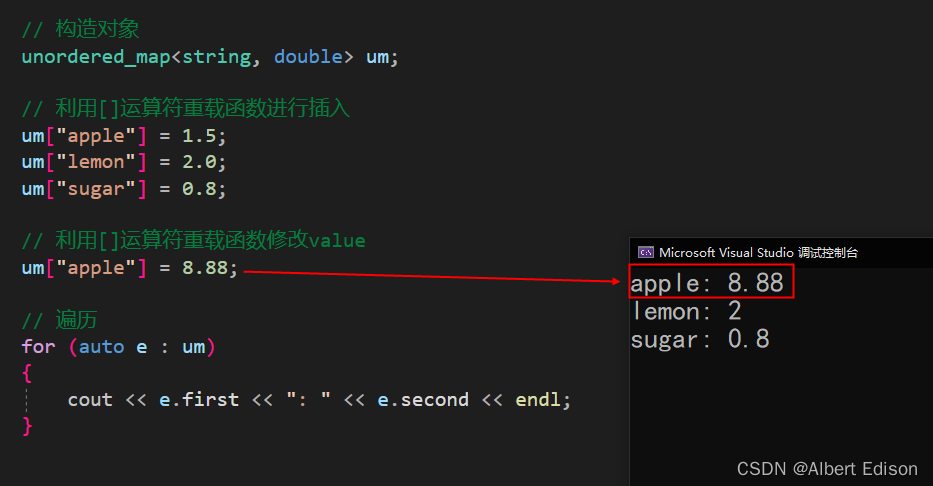
(2)利用 [] 运算符重载函数进行修改
void test_unordered()
{
unordered_map<string, double> um;
um["apple"] = 1.5;
um["lemon"] = 2.0;
um["sugar"] = 0.8;
um["apple"] = 8.88;
for (auto e : um)
{
cout << e.first << ": " << e.second << endl;
}
}
运行结果
总结:
- 若当前容器中已有键值为 key 的键值对,则返回该键值对 value 的引用。
- 若当前容器中没有键值为 key 的键值对,则先插入键值对
<key, value()>,然后再返回该键值对中 value 的引用。
🍅 find
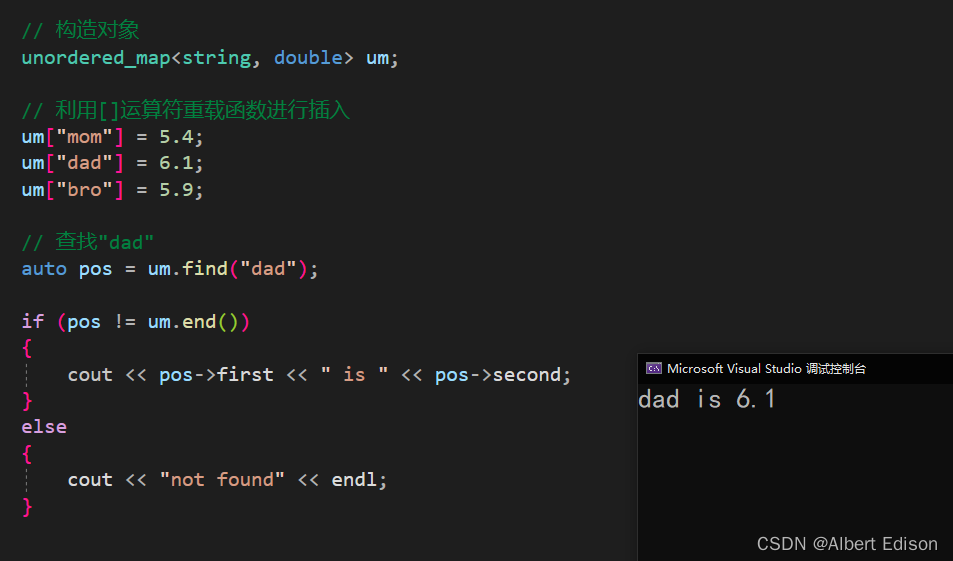
在容器中搜索以 k 为键的元素,如果找到它,就返回一个迭代器,否则就返回 unordered_map::end(容器末端之前的元素)的迭代器。

代码示例
void test_unordered()
{
unordered_map<string, double> um;
um["mom"] = 5.4;
um["dad"] = 6.1;
um["bro"] = 5.9;
auto pos = um.find("dad");
if (pos != um.end())
{
cout << pos->first << " is " << pos->second;
}
else
{
cout << "not found" << endl;
}
}
运行结果
🍅 erase
从 unordered_map 容器中移除单个元素或一组元素([first,last))。
通过调用每个元素的析构函数,这有效地减少了容器的大小。
(1)从容器中删除单个元素(直接传要删除的元素)
void test_unordered()
{
unordered_map<string, string> um;
um["U.S."] = "Washington";
um["U.K."] = "London";
um["France"] = "Paris";
um["Russia"] = "Moscow";
um["China"] = "Beijing";
um["Germany"] = "Berlin";
um["Japan"] = "Tokyo";
um.erase("Japan");
for (auto e : um)
{
cout << e.first << ": " << e.second << endl;
}
}
运行结果
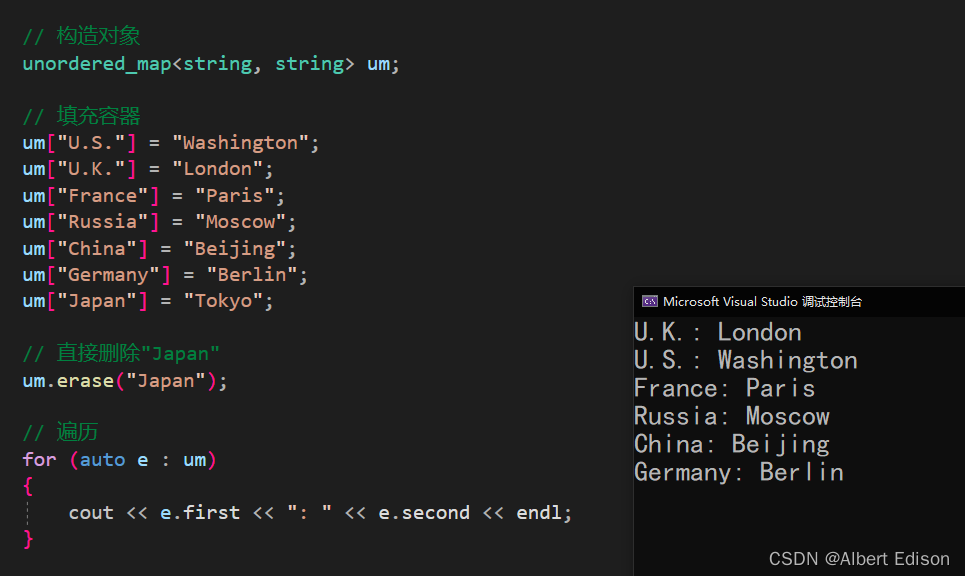
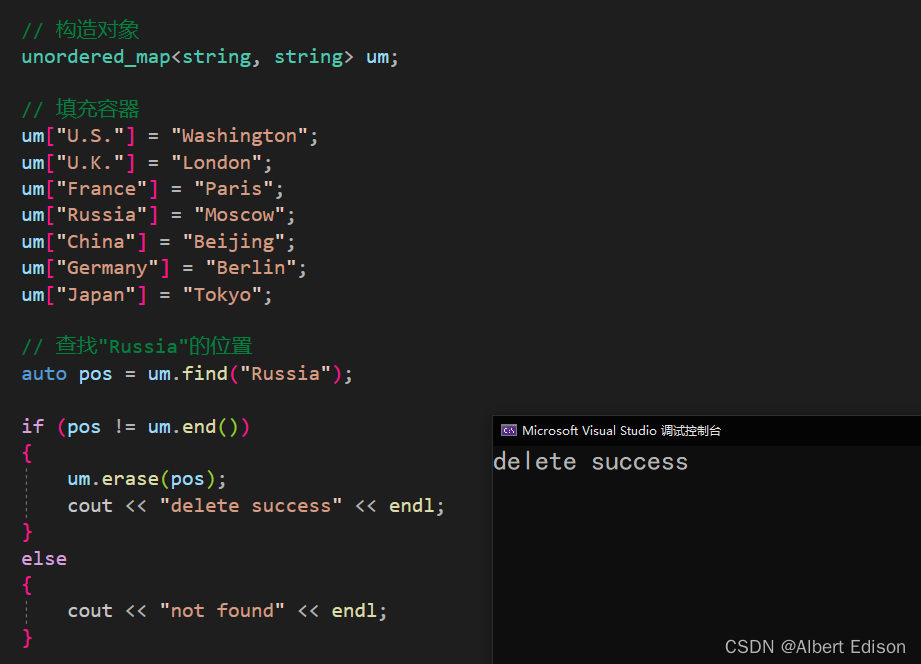
(2)从容器中删除单个元素(搭配 find 使用)
void test_unordered()
{
unordered_map<string, string> um;
um["U.S."] = "Washington";
um["U.K."] = "London";
um["France"] = "Paris";
um["Russia"] = "Moscow";
um["China"] = "Beijing";
um["Germany"] = "Berlin";
um["Japan"] = "Tokyo";
auto pos = um.find("Russia");
if (pos != um.end())
{
um.erase(pos);
cout << "delete success" << endl;
}
else
{
cout << "not found" << endl;
}
}
运行结果
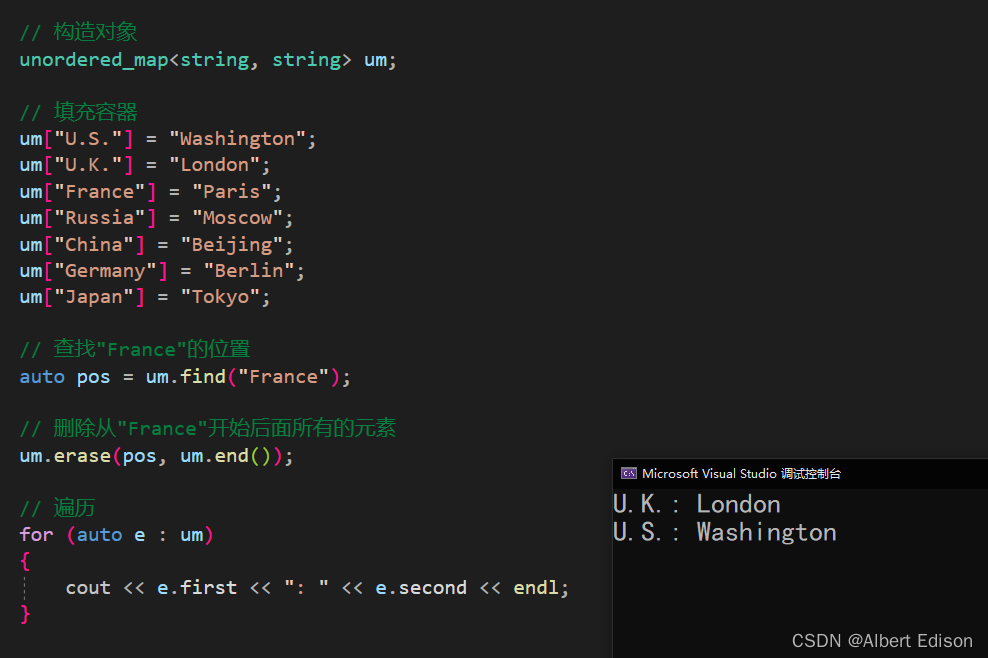
(3)从容器中删除一组元素(搭配 find 使用)
void test_unordered()
{
unordered_map<string, string> um;
um["U.S."] = "Washington";
um["U.K."] = "London";
um["France"] = "Paris";
um["Russia"] = "Moscow";
um["China"] = "Beijing";
um["Germany"] = "Berlin";
um["Japan"] = "Tokyo";
auto pos = um.find("France");
um.erase(pos, um.end());
for (auto e : um)
{
cout << e.first << ": " << e.second << endl;
}
}
运行结果
🍅 size
返回 unordered_map 容器中的元素数量。

代码示例
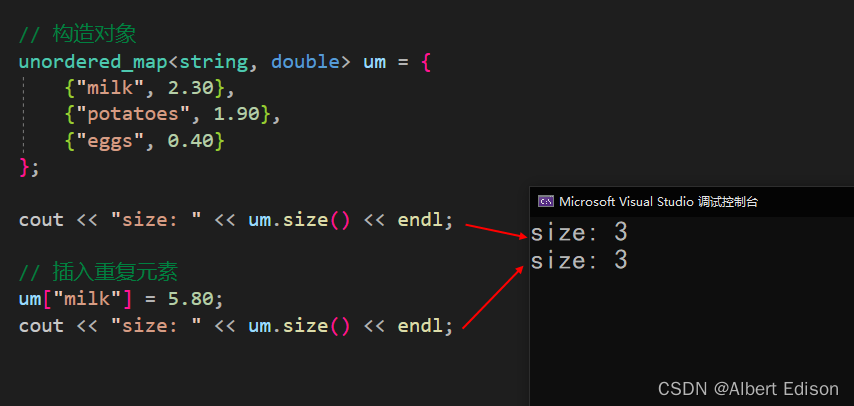
void test_unordered()
{
unordered_map<string, double> um = {
{"milk", 2.30},
{"potatoes", 1.90},
{"eggs", 0.40}
};
cout << "size: " << um.size() << endl;
um["milk"] = 5.80;
cout << "size: " << um.size() << endl;
}
运行结果
🍅 empty
返回一个 bool 值,指示 unordered_map 容器是否为空,即其大小是否为 0。
这个函数不会以任何方式修改容器的内容。

代码示例
void test_unordered()
{
unordered_map<int, int> um1;
unordered_map<int, int> um2 = { {1,10},{2,20},{3,30} };
cout << "um1 " << (um1.empty() ? "is empty" : "is not empty") << endl;
cout << "um2 " << (um2.empty() ? "is empty" : "is not empty") << endl;
}
运行结果

🍅 clear
unordered_map 容器中的所有元素都将被删除,会去调用它们的析构函数,并将它们从容器中移除,使容器的大小为 0。

代码示例
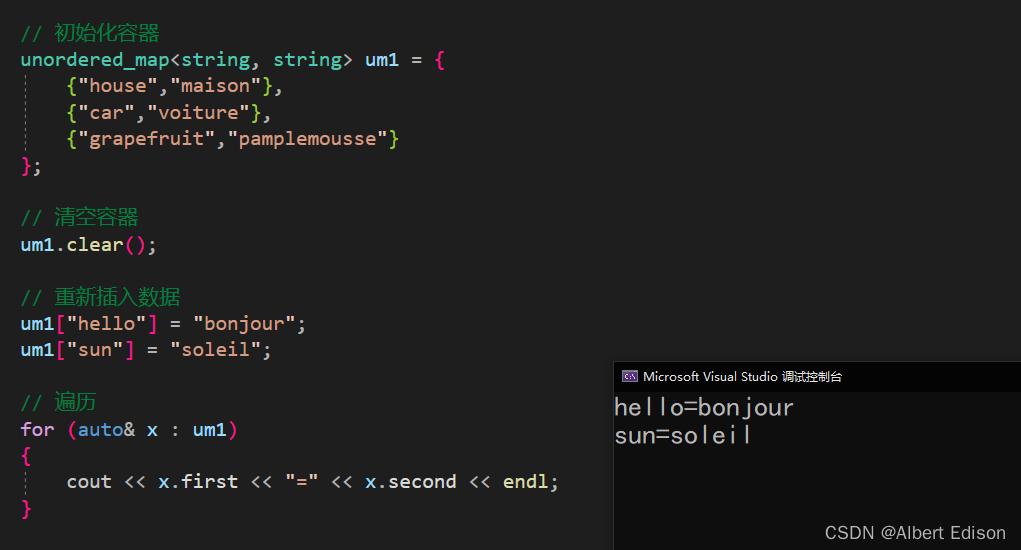
void test_unordered()
{
unordered_map<string, string> um1 = {
{"house","maison"},
{"car","voiture"},
{"grapefruit","pamplemousse"}
};
um1.clear();
um1["hello"] = "bonjour";
um1["sun"] = "soleil";
for (auto& x : um1)
{
cout << x.first << "=" << x.second << endl;
}
}
运行结果
🍅 swap
通过 ump 的内容交换容器的内容,ump 是另一个包含相同类型元素的 unordered_map 对象,大小可能不同。
这个函数在容器之间交换指向数据的内部指针,而不实际对单个元素执行任何复制或移动,允许常量时间执行,无论大小如何。

代码示例
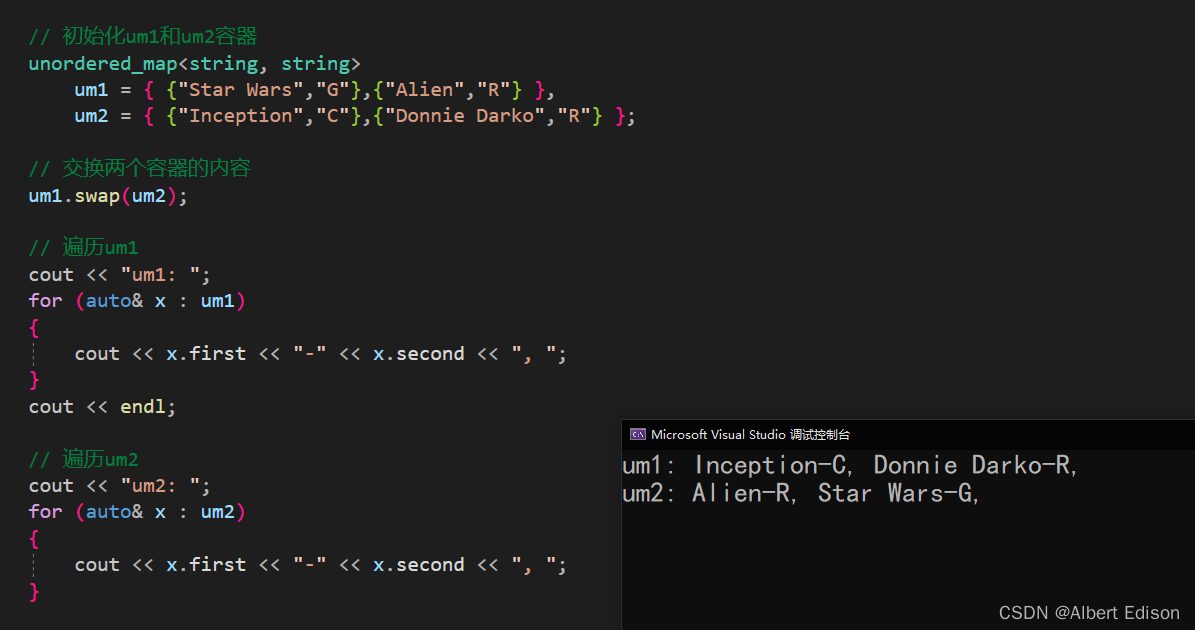
void test_unordered()
{
unordered_map<string, string>
um1 = { {"Star Wars","G"},{"Alien","R"} },
um2 = { {"Inception","C"},{"Donnie Darko","R"} };
um1.swap(um2);
cout << "um1: ";
for (auto& x : um1)
{
cout << x.first << "-" << x.second << ", ";
}
cout << endl;
cout << "um2: ";
for (auto& x : um2)
{
cout << x.first << "-" << x.second << ", ";
}
}
运行结果
🍅 count
在容器中搜索键为 k 的元素,并返回找到的元素数。
因为 unordered_map 容器不允许重复键,这意味着如果容器中存在具有该键的元素,则函数实际返回 1,否则返回 0。

代码示例
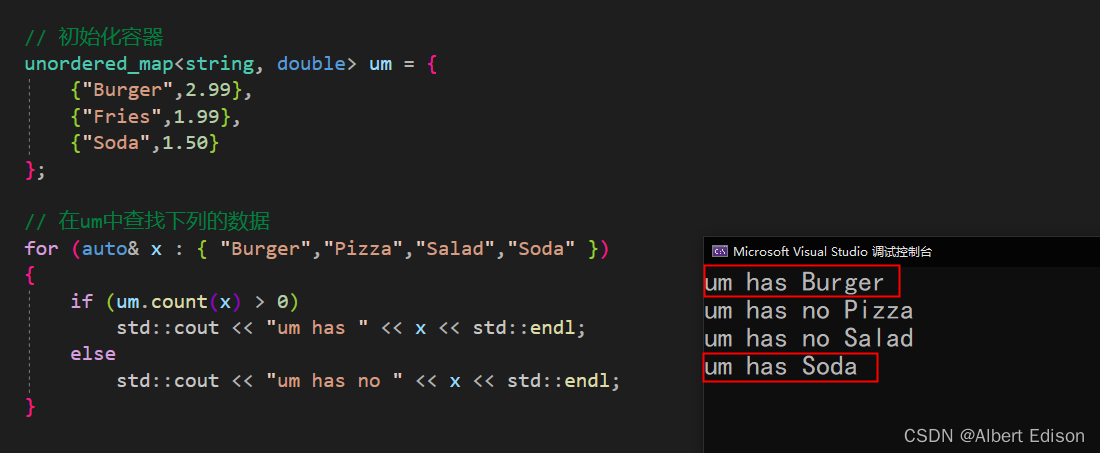
void test_unordered()
{
unordered_map<string, double> um = {
{"Burger",2.99},
{"Fries",1.99},
{"Soda",1.50}
};
for (auto& x : { "Burger","Pizza","Salad","Soda" })
{
if (um.count(x) > 0)
std::cout << "um has " << x << std::endl;
else
std::cout << "um has no " << x << std::endl;
}
}
运行结果
2. unordered_multimap的介绍和使用
unordered_multimap 的介绍:
- multimap 是一种关联容器,它存储由键值和映射值组合而成的元素,很像 unordered_map 容器,但是允许不同的元素具有等价的键。
- 在 unordered_multimap 中,键值通常用于唯一标识元素,而映射值是一个对象,其内容与该键相关联。键和映射值的类型可能不同。
- 在内部,unordered_multimap 中的元素不会根据它们的键值或映射值以任何特定的顺序进行排序,而是根据它们的散列值将它们组织到 bucket中,以允许直接通过键值快速访问单个元素(平均时间复杂度恒定)。
- 具有等效键的元素被分组在同一个 bucket 中,并且迭代器可以遍历所有这些元素。
- 容器中的迭代器至少是前向迭代器。
注意,这个容器不是在它自己的头文件中定义的,而是与 unordered_map 共享头文件 <unordered_map>。
🍑 unordered_multimap的使用
unordered_multimap 容器与 unordered_map 容器的底层数据结构是一样的,都是哈希表。
其次,它们所提供的成员函数的接口都是基本一致的,这两种容器唯一的区别就是,unordered_multimap 容器允许键值冗余,即 unordered_multimap 容器当中存储的键值对的 key 值是可以重复的。
其次,由于 unordered_multimap 容器允许键值对的键值冗余,调用 [] 运算符重载函数时,应该返回键值为 key 的哪一个键值对的 value 的引用存在歧义,因此在 unordered_multimap 容器当中没有实现 [] 运算符重载函数。
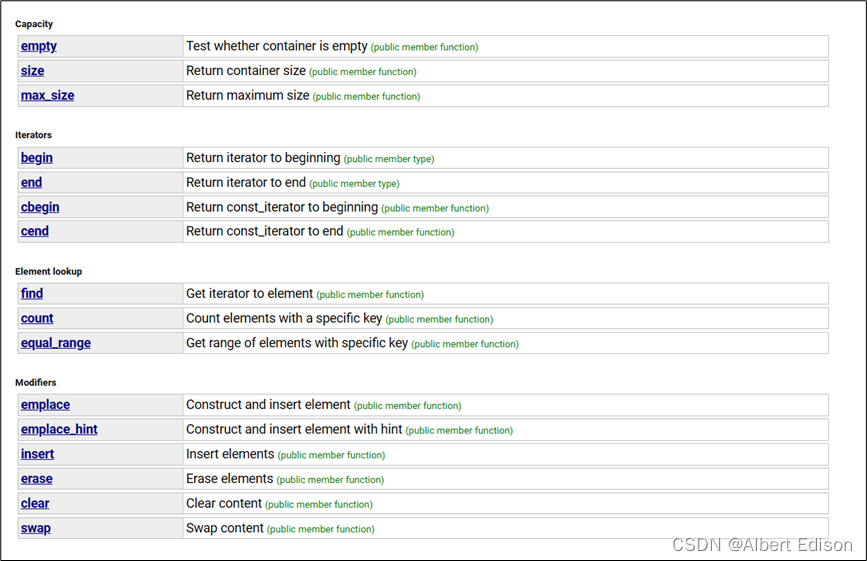
代码示例
void test_unordered()
{
unordered_multimap<int, string> umm;
umm.insert(make_pair(2023, "跑步"));
umm.insert({ 2023, "打球" });
umm.insert({ 2023,"玩游戏" });
for (auto x : umm)
{
cout << x.first << ": " << x.second << endl;
}
}
可以看到,key 是可以重复的。
另外,它和 unordered_map 容器所提供的成员函数的接口都是基本一致的,所以就不全部列举了,只列举几个稍微有点小差别的函数接口。
🍅 find
在容器中搜索以 key 为键的元素,如果找到,则返回该元素的迭代器,否则返回 unordered_multimap::end(超出容器末端的元素)的迭代器。
也就是返回底层哈希表中第一个找到的键值为 key 的键值对的迭代器。

代码示例
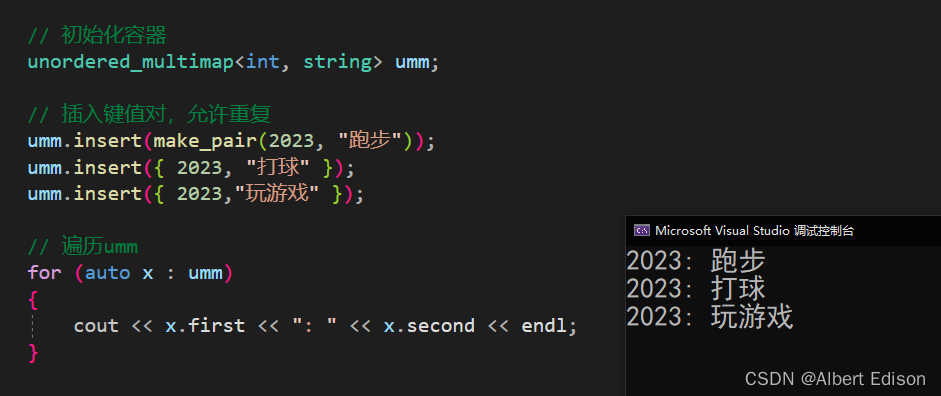
void test_unordered()
{
unordered_multimap<string, string> umm;
umm.insert({ "mom", "妈妈" });
umm.insert({ "mom", "母亲" });
umm.insert({ "dad", "父亲" });
umm.insert({ "bro", "兄弟" });
cout << "one of the values for 'mom' is: ";
cout << umm.find("mom")->second;
}
运行结果
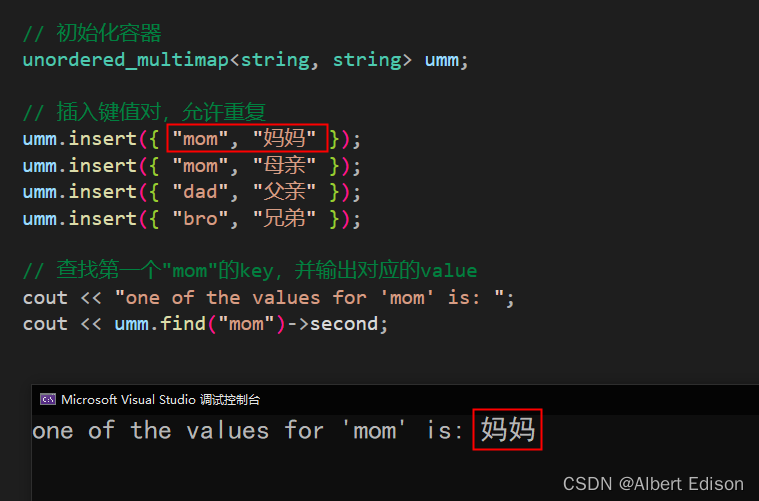
🍅 count
在容器中搜索键为 k 的元素,并返回找到的元素个数。

代码示例
void test_unordered()
{
unordered_multimap<string, string> umm = {
{"orange","FL"},
{"strawberry","LA"},
{"strawberry","OK"},
{"pumpkin","NH"}
};
for (auto& x : { "orange","lemon","strawberry" })
{
cout << x << ": " << umm.count(x) << " 次" << endl;
}
}
运行结果
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)