本文使用的编译器是Pycharm,具体的安装教程可参考:Pycharm安装参考链接
一、新建项目
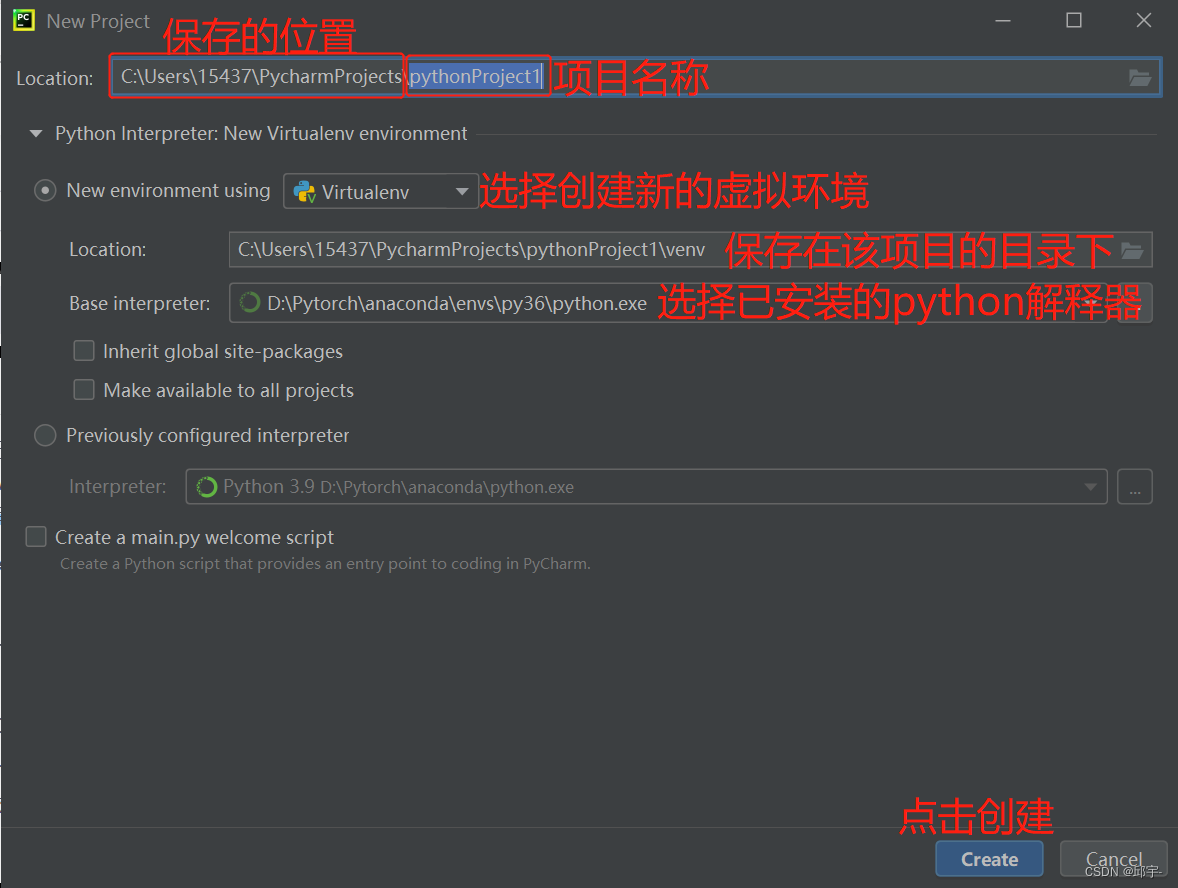
首先打开Pycharm,点击【new project】进行新建,选择项目的保存位置,将项目名称改为【test】,并选择已安装的python版本作为解释器,点击【create】,等待项目生成。
然后在左边目录栏,【test】处右键选择【new】->【Directory】,创建一个名为【facenet_test】的文件夹,并在该文件夹下右键【new】->【python file】,创建一个名为【fp】的py文件。

二、安装Pytorch
打开PyTorch官网Start Locally | PyTorch,在主页中根据自己的电脑选择Linux、Mac或Windows,其余如下图所示,系统将给出对应的安装语句,如我这里为“pip3 install torch torchvision torchaudio”。

复制红色框中的语句,到Pycharm中,点击底部的【Terminal】打开终端,粘贴上述语句后回车,就会开始下载Pytorch。(如果这个过程中下载速度太慢的话可以尝试在后面加上清华镜像,即将上述语句改为:
pip install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
稍等片刻后,系统显示“successfully installed……”,表明成功。可以继续在Terminal终端中输入以下命令,来测试是否安装成功。
Python
import torch
torch.__version__ #注意此处是两个“_”符号连在一起
效果如下所示,说明安装成功了。

测试完成后可以ctrl+z并回车退出python环境。
三、安装facenet_pytorch
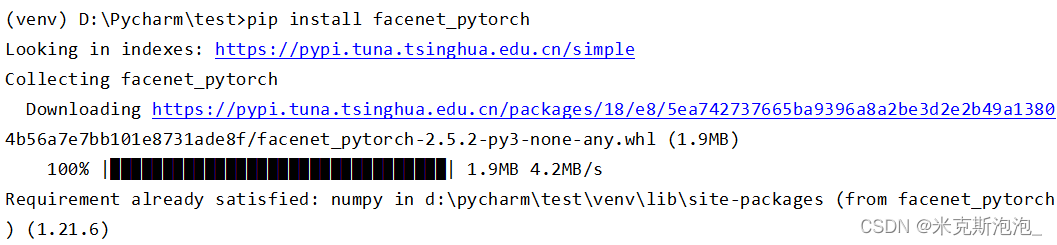
继续在Pycharm的Terminal终端中键入如下命令,就会开始下载。
pip install facenet_pytorch
安装好之后到“C:\Users\用户名\”路径下查看是否有“.cache”文件夹。如果没有,则在Terminal终端中进入python环境,运行以下命令:
python
import torchvision.models as models
alexnet=models.alexnet(pretrained=True)
成功之后重新查看“C:\Users\用户名\”路径,发现已经有了“.cache”文件夹。
四、下载预训练模型
到如下网盘链接中下载预训练模型,并将压缩包解压放置在“C:\Users\用户名\.cache\torch\hub\checkpoints”或“C:\Users\用户名\.cache\torch\checkpoints”路径下。如图所示。
链接:https://pan.baidu.com/s/1UrnggoOLL8lv2Nj4odBfWw?pwd=w6x8
提取码:w6x8

五、代码实现
首先选择两张图片作为待识别的图片,并将它们与fp.py放置在同一目录中,即保存到facenet_test文件夹中。在这里我选择以下两张图片,分别命名为“zj.jpg”和“zj2.jpg”。


然后将如下代码输入到fp.py文件中。
import cv2
import torch
from facenet_pytorch import MTCNN, InceptionResnetV1
# 获得人脸特征向量
def load_known_faces(dstImgPath, mtcnn, resnet):
aligned = []
knownImg = cv2.imread(dstImgPath) # 读取图片
face = mtcnn(knownImg) # 使用mtcnn检测人脸,返回【人脸数组】
if face is not None:
aligned.append(face[0])
aligned = torch.stack(aligned).to(device)
with torch.no_grad():
known_faces_emb = resnet(aligned).detach().cpu() # 使用resnet模型获取人脸对应的特征向量
print("\n人脸对应的特征向量为:\n", known_faces_emb)
return known_faces_emb, knownImg
# 计算人脸特征向量间的欧氏距离,设置阈值,判断是否为同一个人脸
def match_faces(faces_emb, known_faces_emb, threshold):
isExistDst = False
distance = (known_faces_emb[0] - faces_emb[0]).norm().item()
print("\n两张人脸的欧式距离为:%.2f" % distance)
if(distance < threshold):
isExistDst = True
return isExistDst
if __name__ == '__main__':
# help(MTCNN)
# help(InceptionResnetV1)
# 获取设备
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
# mtcnn模型加载【设置网络参数,进行人脸检测】
mtcnn = MTCNN(min_face_size=12, thresholds=[0.2, 0.2, 0.3], keep_all=True, device=device)
# InceptionResnetV1模型加载【用于获取人脸特征向量】
resnet = InceptionResnetV1(pretrained='vggface2').eval().to(device)
MatchThreshold = 0.8 # 人脸特征向量匹配阈值设置
known_faces_emb, _ = load_known_faces('zj.jpg', mtcnn, resnet) # 已知人物图
# bFaceThin.png lyf2.jpg
faces_emb, img = load_known_faces('zj2.jpg', mtcnn, resnet) # 待检测人物图
isExistDst = match_faces(faces_emb, known_faces_emb, MatchThreshold) # 人脸匹配
print("设置的人脸特征向量匹配阈值为:", MatchThreshold)
if isExistDst:
boxes, prob, landmarks = mtcnn.detect(img, landmarks=True) # 返回人脸框,概率,5个人脸关键点
print('由于欧氏距离小于匹配阈值,故匹配')
else:
print('由于欧氏距离大于匹配阈值,故不匹配')
注意:如果你的待识别图片是别的图片,保存的名字和我的不一样,那就需要将上述代码的第43行和45行的对应的图片名称改为你的图片名称。
还有一个问题,如果输入代码后,第1行import cv2处显示No model named cv2,则需要手动添加opencv的包,如下图所示:

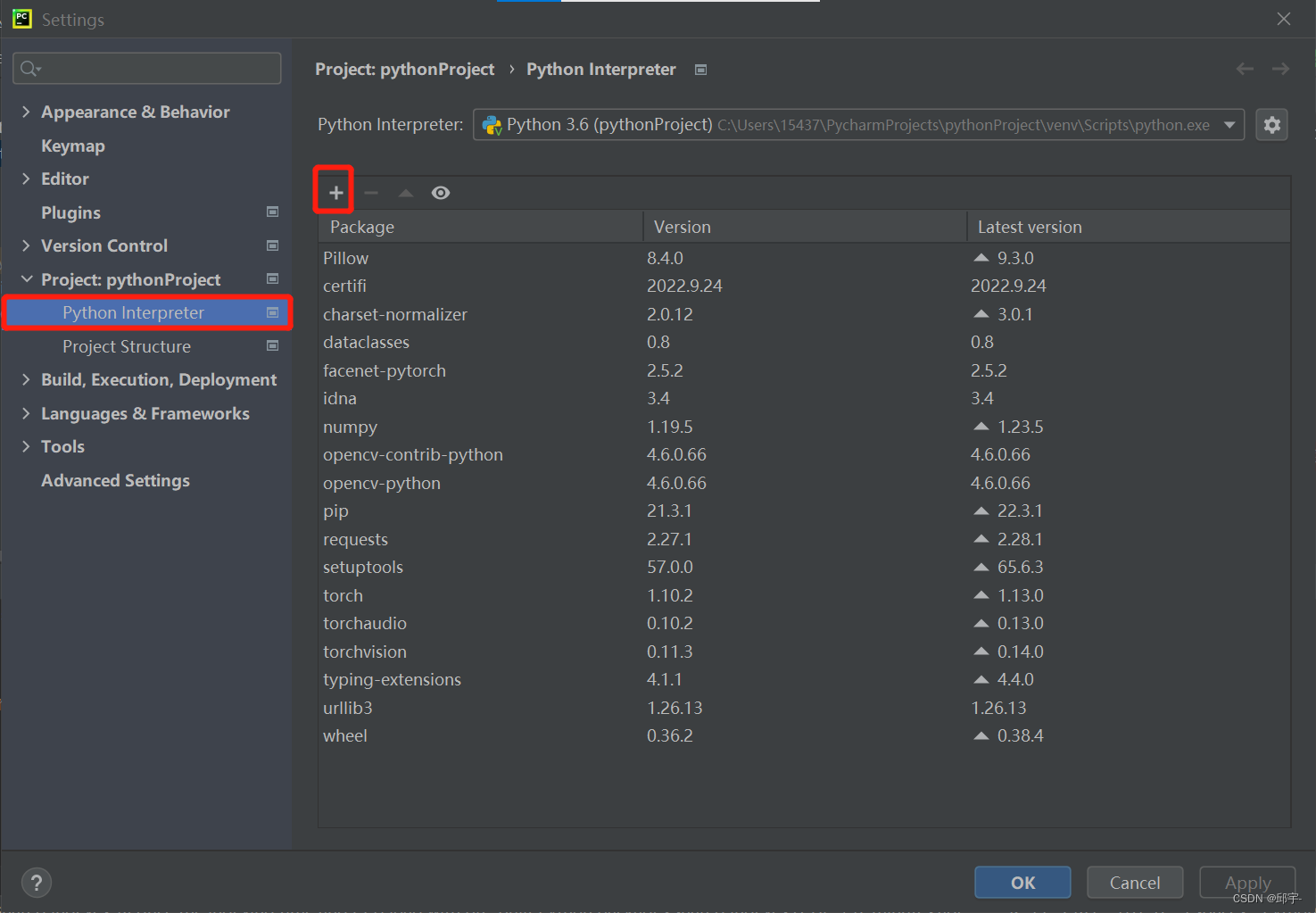
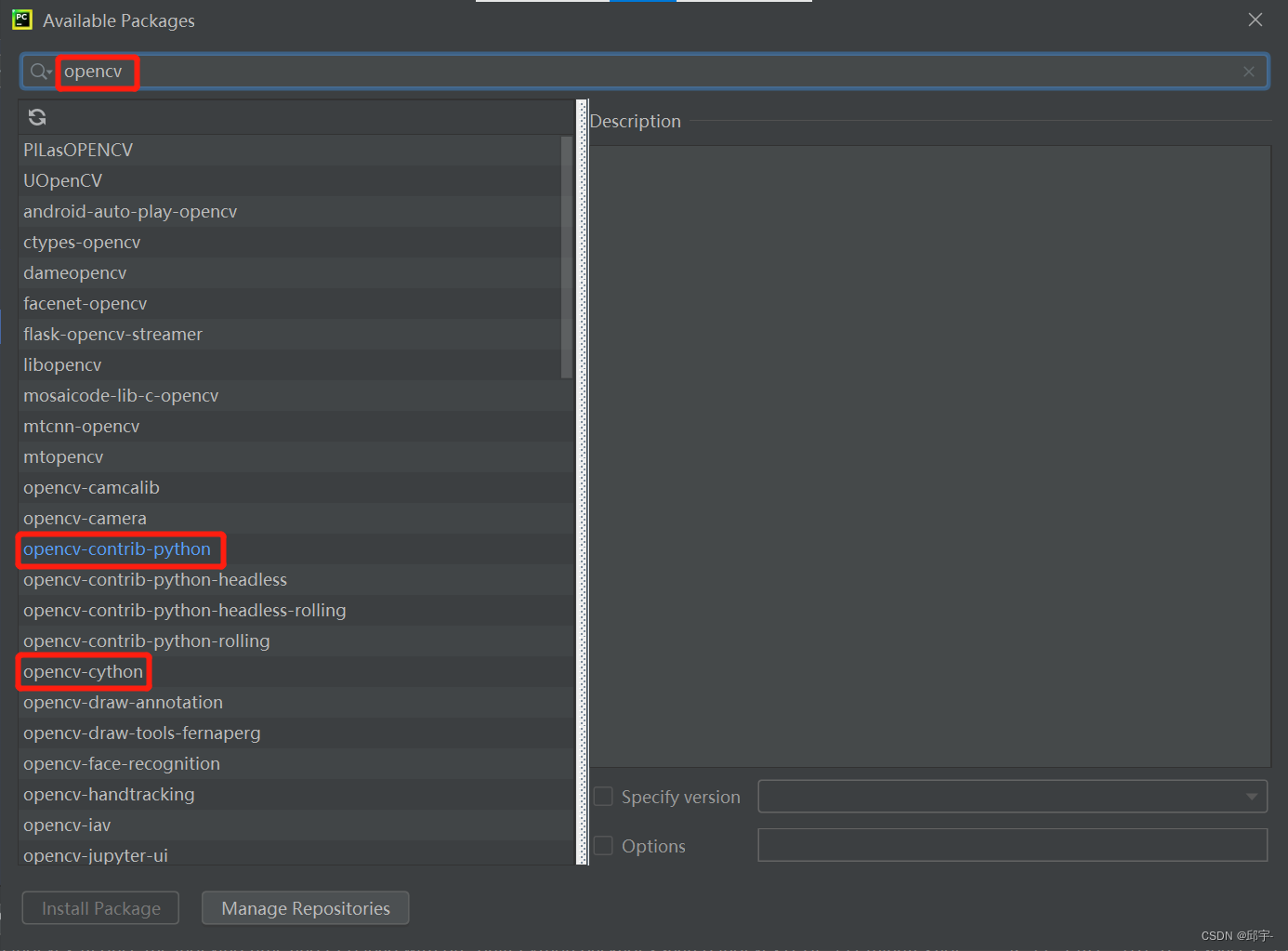
点击【File】->【Settings】->【Python Interpreter】,点击加号,搜索【opencv】,依次选中红框中的两个包,点击【Install Package】,等待下载完成,然后就可以运行fp.py了。
第一次运行时系统需要下载预训练的vggface模型,时间会比较久,耐心等待下载好之后程序便可以运行。
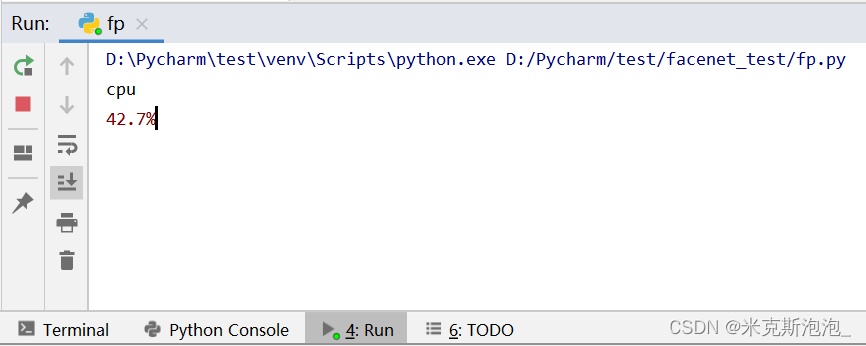
程序的输出结果包括运行设备、两张图片中人脸对应的特征向量、两张人脸的欧式距离、设置的人脸特征向量匹配阈值和两张人脸是否匹配。
部分运行结果如下所示:


根据运行结果,两张图片中人脸的欧氏距离小于设定的匹配阈值,故匹配,也就是说两张人脸是同一个人。下面,我们尝试将zj2.jpg替换为周杰伦的照片zjl.jpg,来看看会有什么结果。(注意:同样的要修改45行处的文件名)


结果显示,两张图片中人脸的欧氏距离大于设定的匹配阈值,故不匹配,也就是说两张人脸不是同一个人。
这样的话,我们的代码就能实现简单的人脸识别啦。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)