- ??作者简介:大家好,我是,独角兽企业的Java开发工程师,Java领域新星创作者。
- ??个人公众号:(回复 “技术书籍” 可获千本电子书籍)
- ??系列专栏:Java设计模式、数据结构和算法、Kafka从入门到成神、Kafka从成神到升仙、操作系统从入门到成神
- ??如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步??
- ??如果感觉博主的文章还不错的话,请??三连支持??一下博主哦
- ??博主正在努力完成2022计划中:以梦为马,扬帆起航,2022追梦人
文章目录
-
- CPU 是如何执行任务的
-
- 一、引言
- 二、CPU 如何读写数据的?
-
- 三、CPU 是如何选择线程的
-
- 1. 调度类
- 2. 完全公平调度
- 3. CPU 运行队列
- 4. 调整优先级
- 四、总结
CPU 是如何执行任务的
首先,我们先提出几个问题:
- 有了内存,为什么还需要 CPU Cache?
- CPU 是怎么读写数据的?
- 如何让 CPU 读写数据更快一点?
- CPU 伪共享是如何发生的?又该如何避免?
- CPU 的调度任务是如何进行的?
一、引言
本文参考 小林coding 的《图解操作系统》,也是我十分喜欢的一个公众号博主,为他打 call
老读者知道我之前再写 Kafka 的博文,为什么突然开始写操作系统的呢?
原因在于:
当我看到 Kafka 服务端的一些 IO 操作时,我发现我看不懂了,了解之后发现这里 Netty 的概念。
当我尝试了解 IO 时,我发现一些内存、磁盘的交换,搞的我焦头烂额,于是,想静下心来从头开始。
当我把 小林coding 的 《图解操作系统》看完之后,我发现对操作系统的理解更上一层楼。
用一段话,作为今天的开场白:
读书的根本目的,未必是解决现实问题,它更像一场心灵的抚慰。
一个喜欢读书的人,可能不会记得自己读过哪些书。
但是那些看过的故事、收获的感悟、浸染过的气质,就像一颗种子,会在你的身体里慢慢发芽长大,不断提升你的认知,打开你的视野。
二、CPU 如何读写数据的?
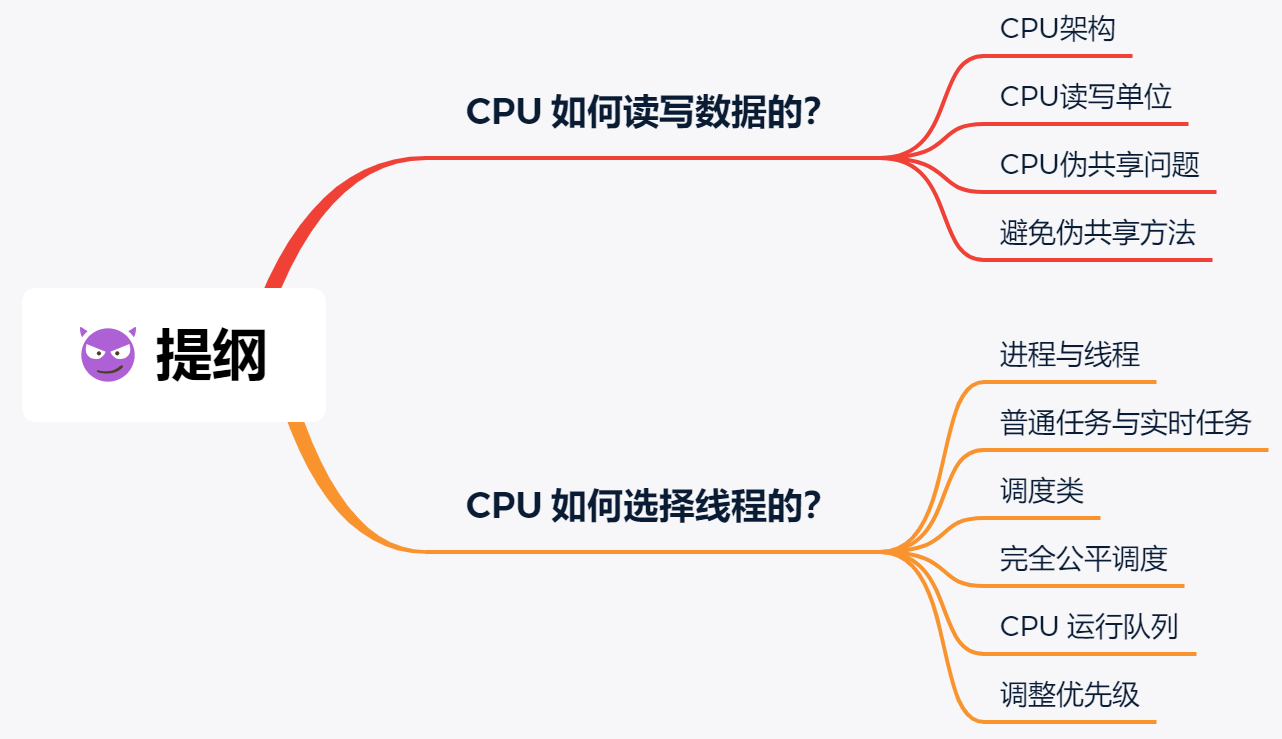
我们先来看下 CPU 的架构图:
我们可以看到,一个 CPU 通常有多个 CPU 核心,对于 L1 Cache(dCache、iCache)、L2 Cache 每个 CPU 核心都是独立的,而 L3 Cache 是多个核心共享的。
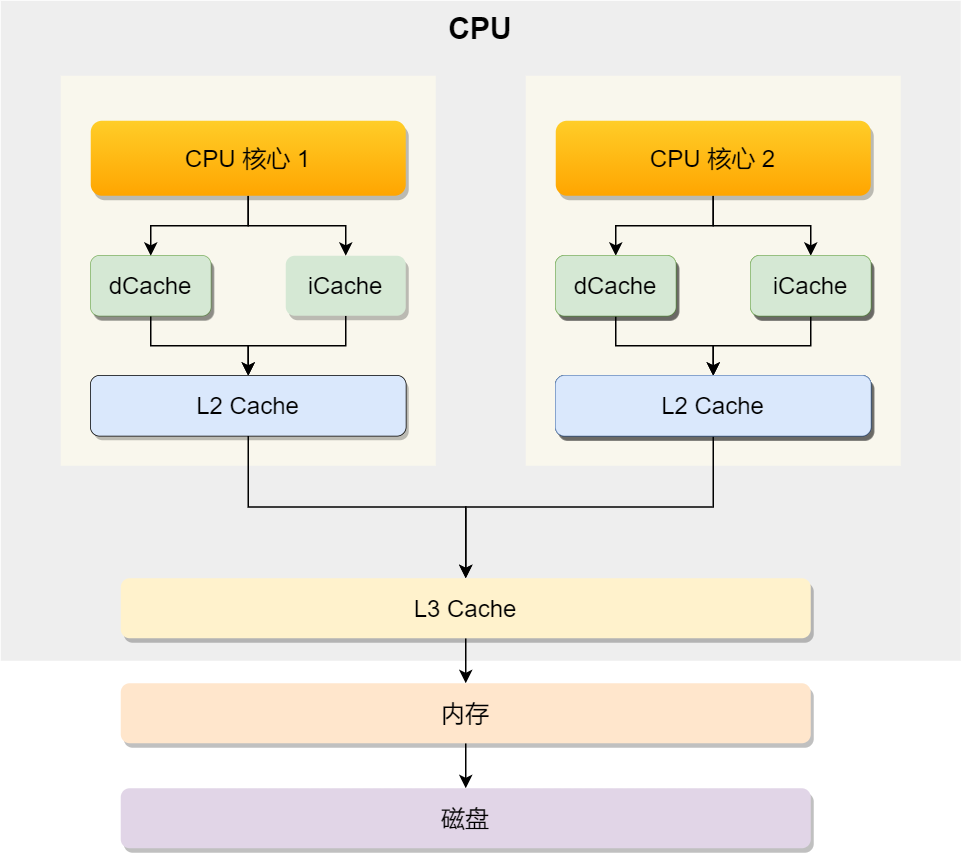
上面的都是 CPU 内部的 Cache,放眼外部的话,还会有内存和硬盘,这些共同组成了 CPU 的存储结构:
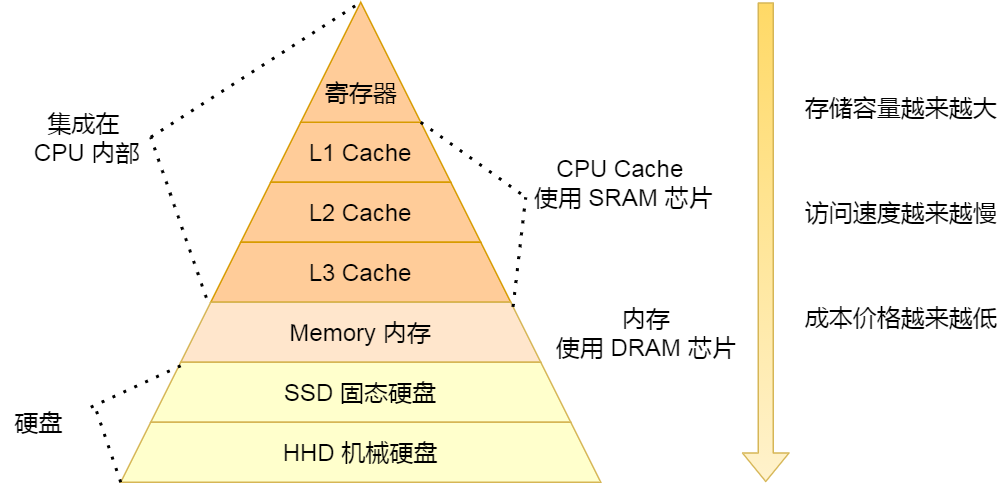
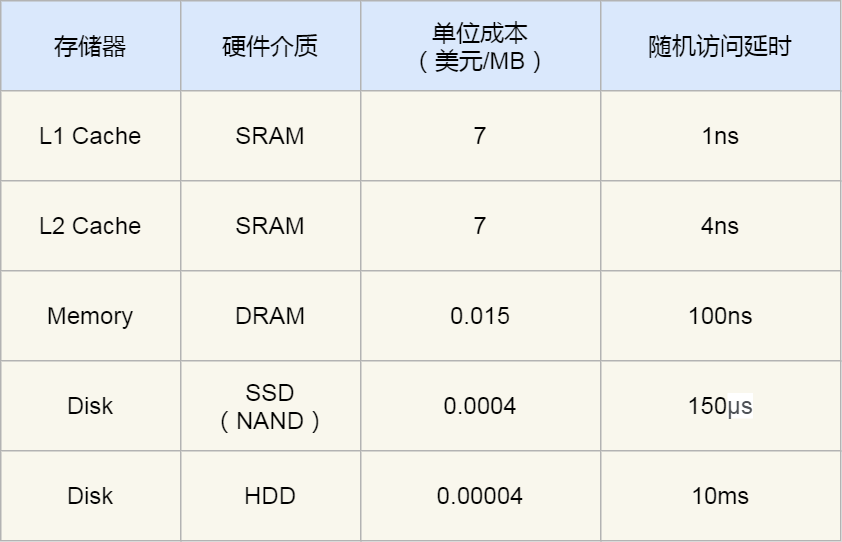
各存储设备的访问状态:
通过这张图,可以解决我们的第一个疑问:有了内存,为什么还需要 CPU Cache?
内存和CPU的交互十分的缓慢,又由于摩尔定律,我们不得不在 CPU 和内存之间添加一层缓存层(CPU Cache)
而我们的 CPU Cache 层级结构如下:
CPU Cache - L1 Cache - Cache Line(缓存块) - Tag(组) + Cache Block(缓存数据)
Cache Line 的大小为:64字节
所以,我们CPU Cache 和内存交互时,一次从内存 Load 的大小为 64 字节。
如果当前加载的是数组 int[] array 的话,我们读取 array[0] 实际会将 array[0] - array[15] 全部加载到 CPU Cache 中,方便下一次 CPU 进行读取
但如果当前加载的是变量的话,会产生伪共享问题,伪共享是性能杀手,我们应该去避免该问题的产生。
我们一起来看一下 伪共享是什么?怎么去避免伪共享?
假设我们当前有一个双核的 CPU,这两个 CPU 核心并行运行着两个不同的线程,它们同时从内存中读取两个不同的数据,分别是类型为 long 的变量 A 和 B,这个两个数据的地址在物理内存上是连续的,如果 Cahce Line 的大小是 64 字节,并且变量 A 在 Cahce Line 的开头位置,那么这两个数据是位于同一个 Cache Line 中,又因为 CPU Line 是 CPU 从内存读取数据到 Cache 的单位,所以这两个数据会被同时读入到了两个 CPU 核心中各自 Cache 中。
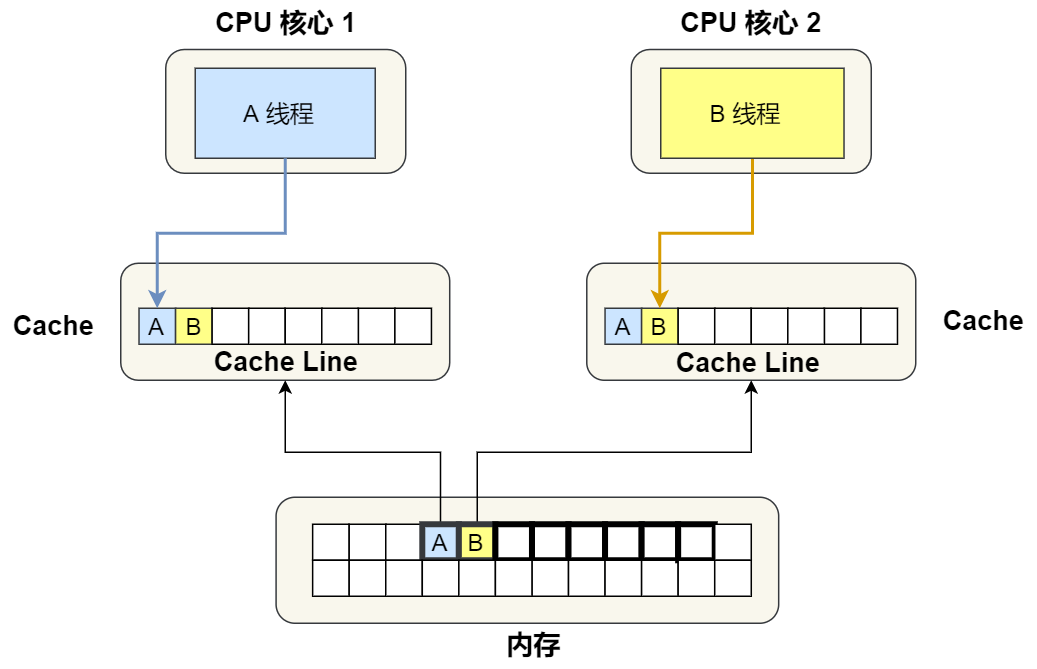
我们来思考一个问题,当我们A线程修改A的值,B线程修改B的值,会出现什么问题呢?
1. 分析伪共享问题
我们上一章讲述了CPU的缓存一致性协议:MESI,我们来分析下上述情况,会产生什么问题?
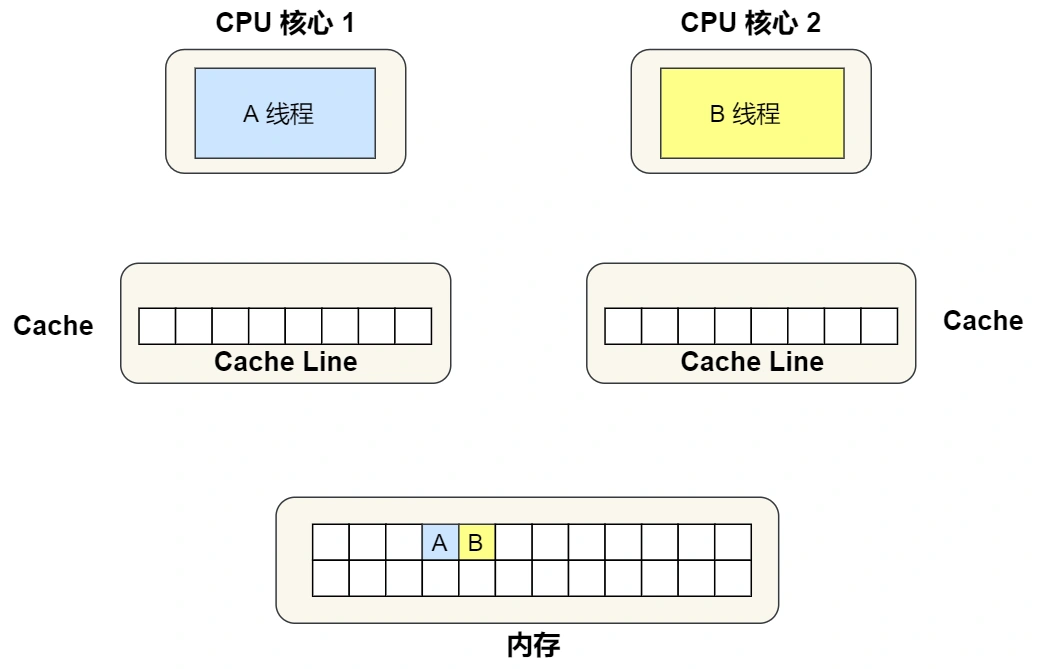
- 最开始变量 A 和 B 都还不在 Cache 里面,假设 1 号核心绑定了线程 A,2 号核心绑定了线程 B,线程 A 只会读写变量 A,线程 B 只会读写变量 B。
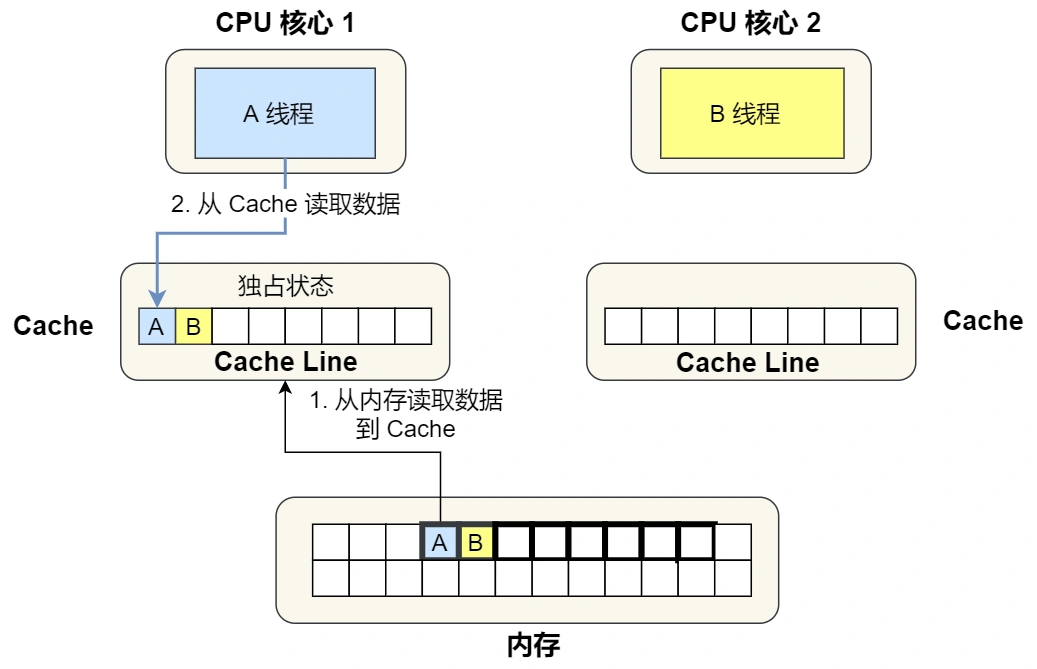
- 1 号核心读取变量 A,由于 CPU 从内存读取数据到 Cache 的单位是 Cache Line,也正好变量 A 和 变量 B 的数据归属于同一个 Cache Line,所以 A 和 B 的数据都会被加载到 Cache,并将此 Cache Line 标记为「独占」状态。
-
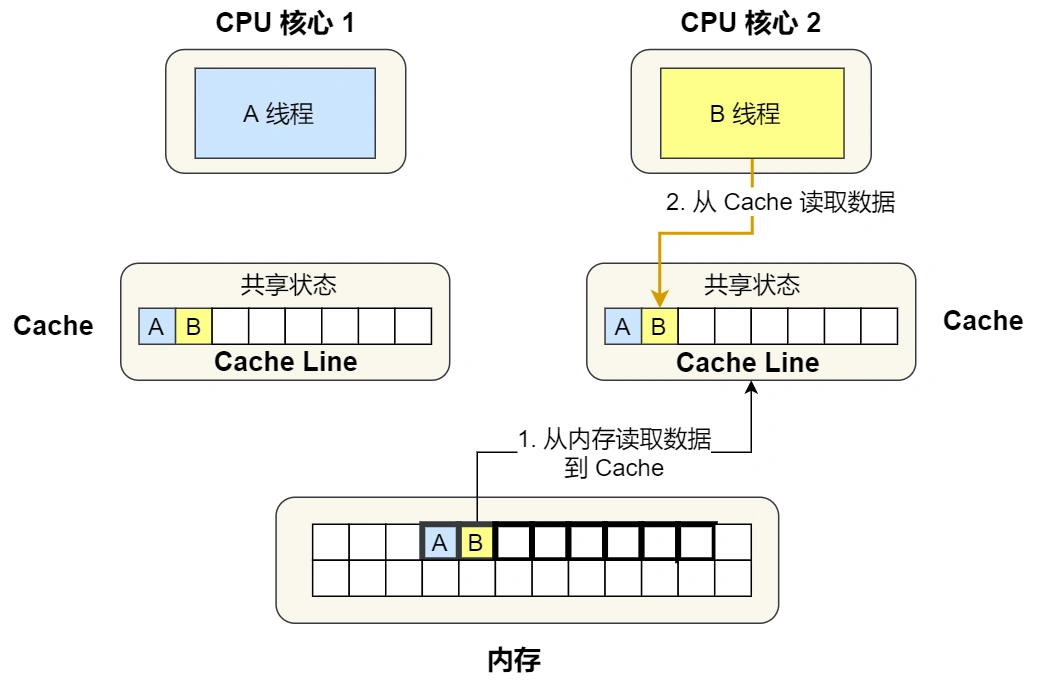
接着,2 号核心开始从内存里读取变量 B,同样的也是读取 Cache Line 大小的数据到 Cache 中,此 Cache Line 中的数据也包含了变量 A 和 变量 B,此时 1 号和 2 号核心的 Cache Line 状态变为「共享」状态。
-
1 号核心需要修改变量 A,发现此 Cache Line 的状态是「共享」状态,所以先需要通过总线发送消息给 2 号核心,通知 2 号核心把 Cache 中对应的 Cache Line 标记为「已失效」状态,然后 1 号核心对应的 Cache Line 状态变成「已修改」状态,并且修改变量 A。
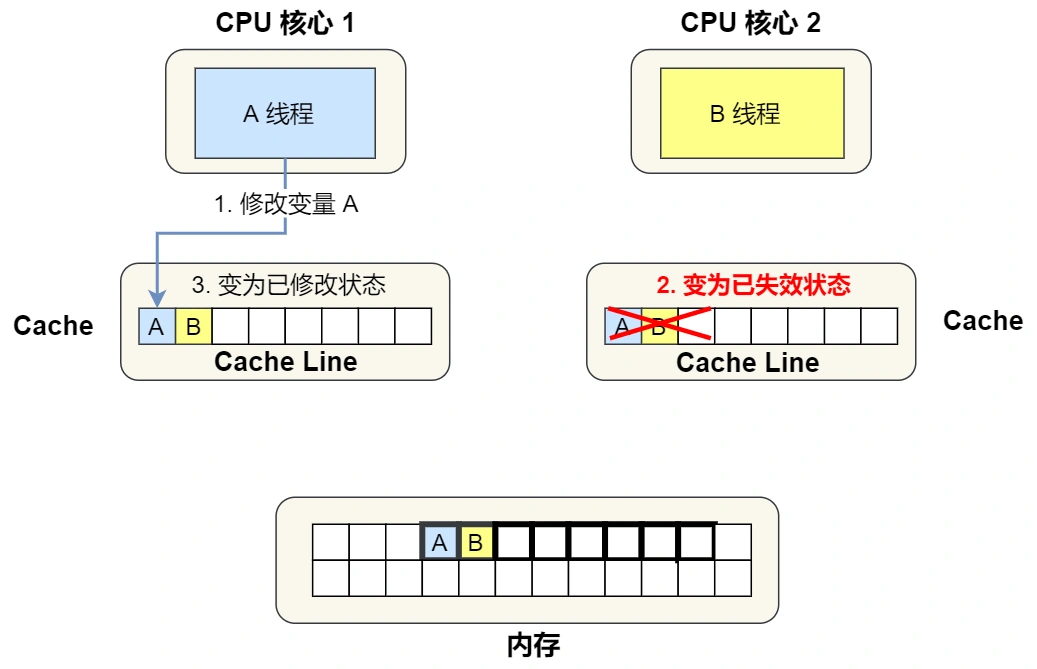
- 之后,2 号核心需要修改变量 B,此时 2 号核心的 Cache 中对应的 Cache Line 是已失效状态,另外由于 1 号核心的 Cache 也有此相同的数据,且状态为「已修改」状态,所以要先把 1 号核心的 Cache 对应的 Cache Line 写回到内存,然后 2 号核心再从内存读取 Cache Line 大小的数据到 Cache 中,最后把变量 B 修改到 2 号核心的 Cache 中,并将状态标记为「已修改」状态。
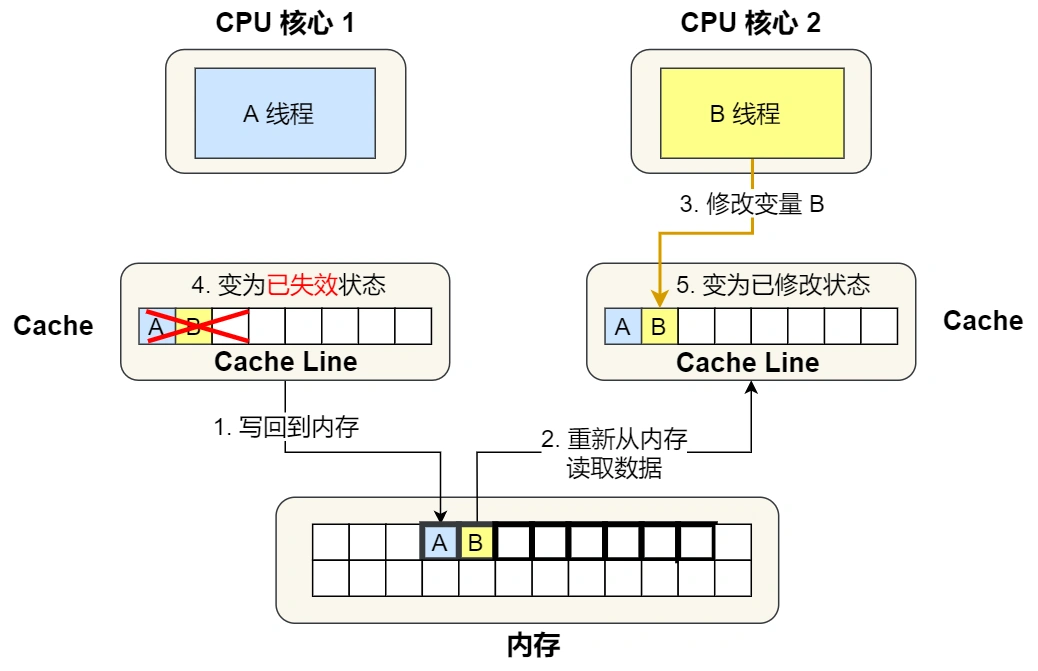
所以,可以发现如果 1 号和 2 号 CPU 核心这样持续交替的分别修改变量 A 和 B,就会重复 ④ 和 ⑤ 这两个步骤,Cache 并没有起到缓存的效果,虽然变量 A 和 B 之间其实并没有任何的关系,但是因为同时归属于一个 Cache Line ,这个 Cache Line 中的任意数据被修改后,都会相互影响,从而出现 ④ 和 ⑤ 这两个步骤。
因此,这种因为多个线程读写同一个 CPU Line 的不同变量时,而导致 CPU Cache 失效的现象称为:伪共享
2. 避免伪共享的方法
对于多个线程共享的热点数据(经常修改的),应该避免这些数据在同一个 CPU Line 中,否则就会出现伪共享的问题。
我们先看看内核中的避免方法:
在 Linux 内核中存在 __cacheline_aligned_in_smp 宏定义,是用于解决伪共享的问题。
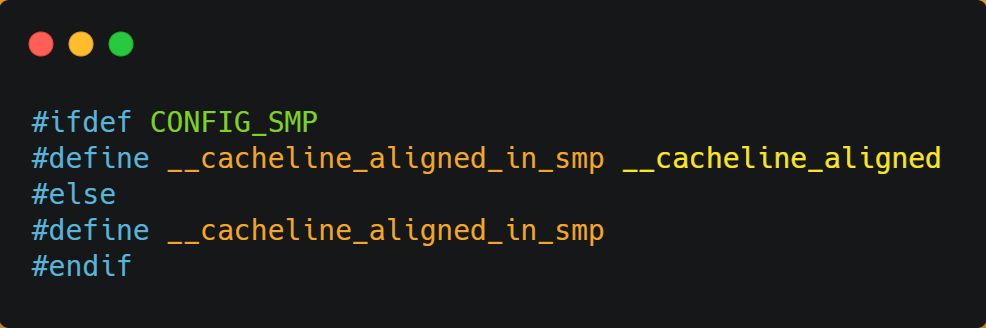
打个比方。如果你定义一个结构体:
struct test {
int a;
int b;
}
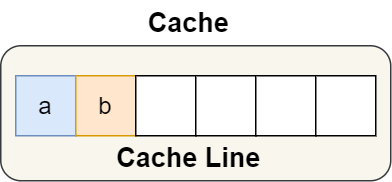
a 和 b 肯定位于同一缓存行,如下:
当我们添加上内核的宏定义后
struct test {
int a;
int b __cacheline_aligned_in_smp;
}
a 和 b 的缓存信息如下:
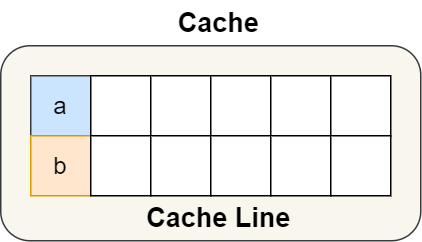
所以,避免伪共享最好的方式就是用空间换时间的思想,浪费一部分的 CPU Cache,从而换来性能的提升。
我们看一下应用层面的规避方案,有一个 Java 的并发框架 Disruptor 使用 字节填充 + 继承 的方法,来避免伪共享的问题。
Disruptor 中有一个 RingBuffer 类会经常被多个线程使用,代码如下:
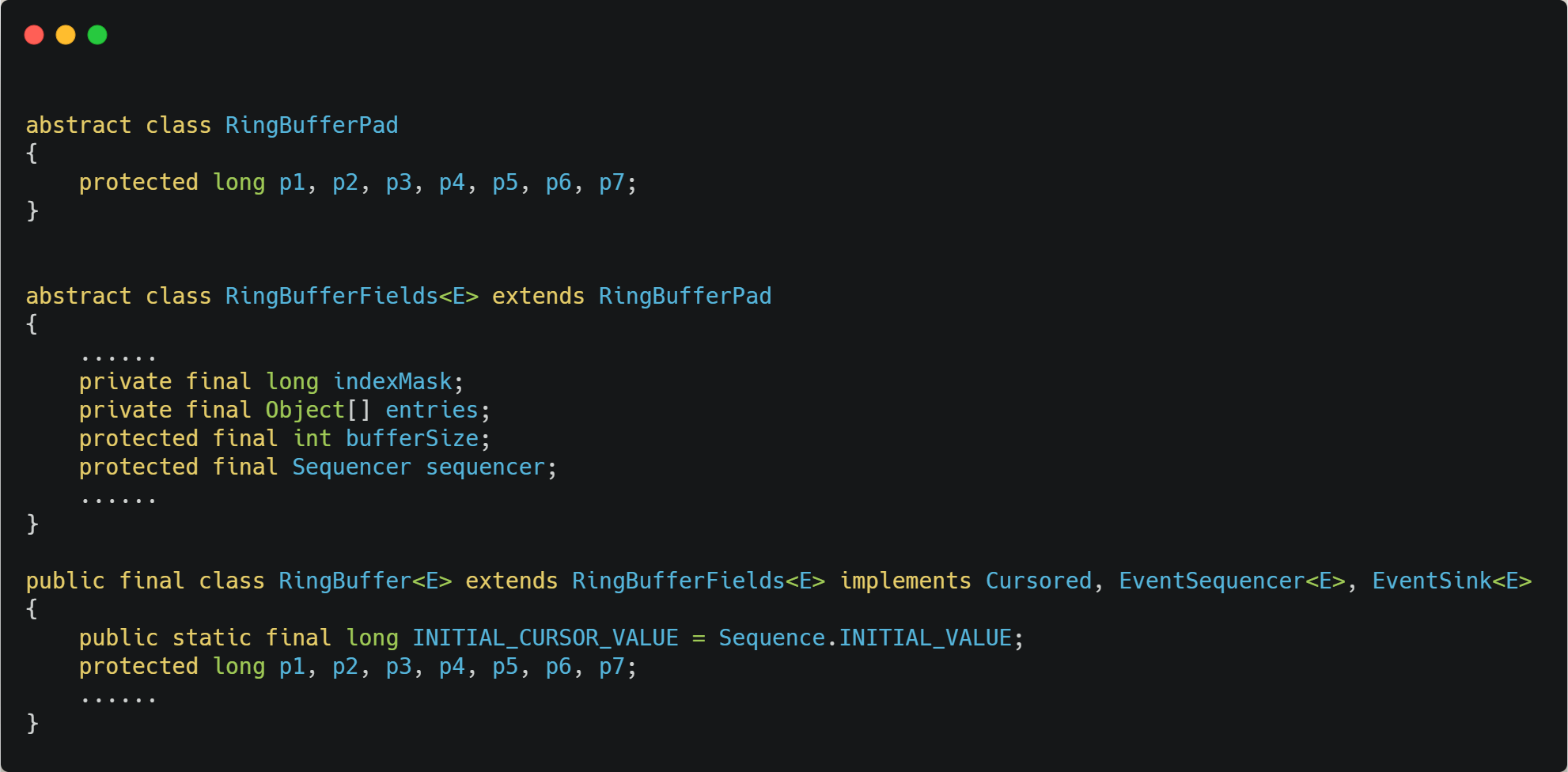
我们都知道,CPU Cache 从内存读取数据的单位是 CPU Line,一般 64 位 CPU 的 CPU Line 的大小是 64 个字节,一个 long 类型的数据是 8 个字节,所以 CPU 一下会加载 8 个 long 类型的数据。
根据 JVM 对象继承关系中父类成员和子类成员,内存地址是连续排列布局的,因此 RingBufferPad 中的 7 个 long 类型数据作为 Cache Line 前置填充,而 RingBuffer 中的 7 个 long 类型数据则作为 Cache Line 后置填充,这 14 个 long 变量没有任何实际用途,更不会对它们进行读写操作。
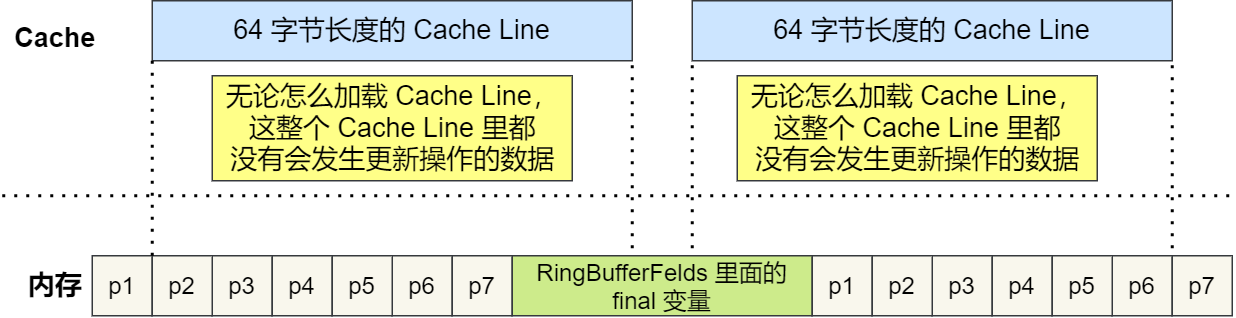
由于「前后」各填充了 7 个不会被读写的 long 类型变量,所以无论怎么加载 Cache Line,这整个 Cache Line 里都没有会发生更新操作的数据,于是只要数据被频繁地读取访问,就自然没有数据被换出 Cache 的可能,也因此不会产生伪共享的问题。
三、CPU 是如何选择线程的
我们上面讲述了 CPU 如何读取数据并且产生伪共享问题,后续我们来看一看,CPU 是如何选择当前要执行的线程
这里需要注意一点:在 Linux 内核中,进程和线程都是用 task_struct 进行表示的,区别在于线程的 task_struct 结构体中的部分资源共享了进程已创建的资源。比如:内存地址、代码段、文件描述符等等,所以 Linux 中的线程也被称为轻量级进程。
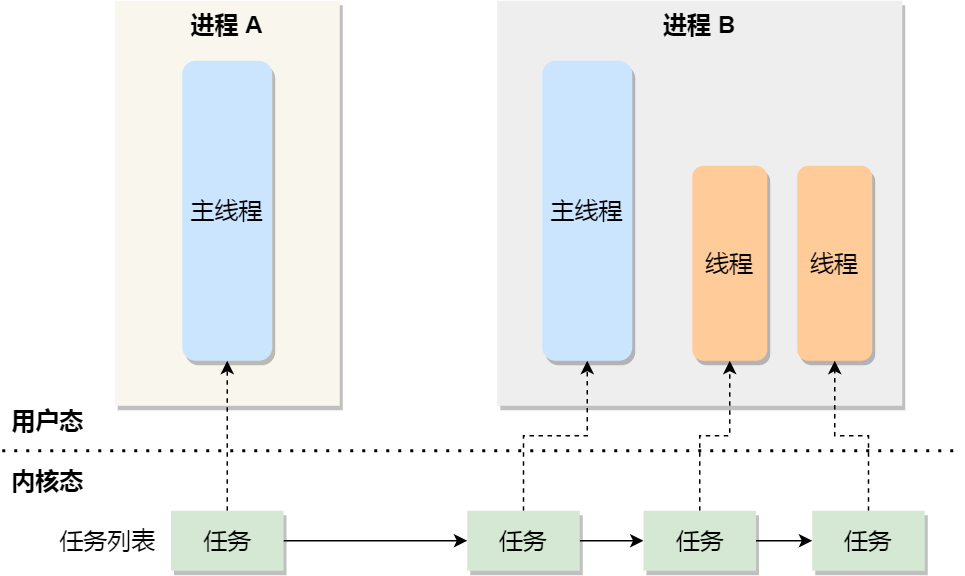
所以,在 Linux 系统中,调度对象就是 task_struct,具体实现我们后面单独出一章进行讲解。
1. 调度类
由于我们的任务存在优先级,Linux 系统为了保障高优先级的任务能够尽可能早的被执行,于是分以下几种:
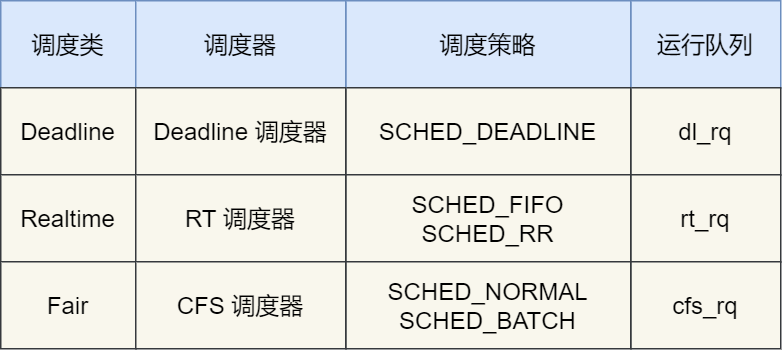
Deadline 和 Realtime 这两个调度类,都是应用于实时任务的
- SCHED_DEADLINE:距离当前时间点最近的 deadline 的任务会被优先调用
- SCHED_FIFO:优先级一致的情况下,实施先来先服务的原则
- SCHED_RR:对于优先级相同的任务,轮询执行(时间片)
而 Fair 调度类是应用于普通任务
- SCHED_NORMAL:普通任务使用的调度策略
- SCHED_BATCH:后台任务的调度策略
2. 完全公平调度
我们平常一般遇到的都是普通任务,对于普通任务来说,公平性最重要。
Linux 基于 CFS 的调度算法, 实现了一种 完全公平调度
虽说是完全公平,也与其优先级有关,具体公式如下图:

3. CPU 运行队列
一个系统肯定存在很多个任务,我们任务的数量会远超于我们的核心,这个时候需要排队。
每个 CPU 拥有自己的运行队列,用于描述此 CPU 上所运行的所有进程,一般我们只需要用到普通任务的,也就是 cfs_rq
任务排序的依据:vruntime
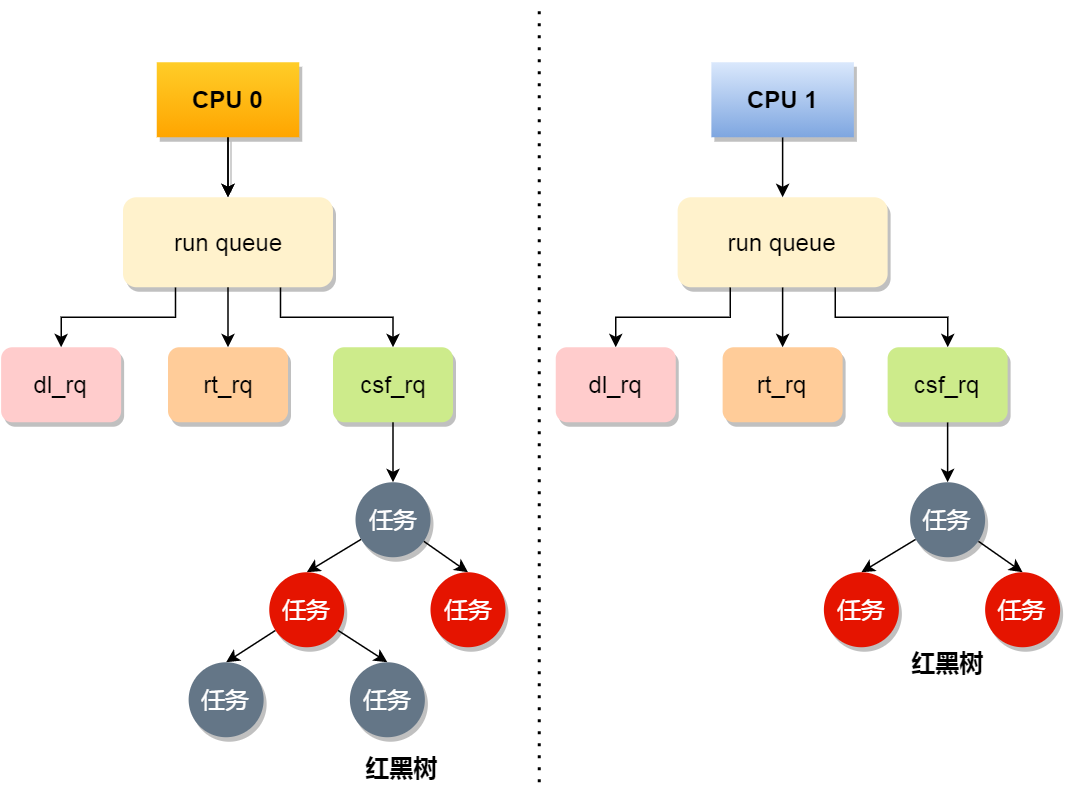
调度的优先级为:Deadline > Realtime > Fair,因此,实时任务总是会比普通任务优先被执行。
4. 调整优先级
如果我们启动任务的时候,没有特意去指定优先级的话,默认情况下都是普通任务。普通任务的调度类是 Fail,由 CFS 调度器来进行管理。实现任务运行的公平性。
权重值与 nice 值的关系的,nice 值越低,权重值就越大,计算出来的 vruntime 就会越少,由于 CFS 算法调度的时候,就会优先选择 vruntime 少的任务进行执行,所以 nice 值越低,任务的优先级就越高。
我们要想让某个普通任务拥有更多的执行时间,需要将此任务的 nice 值进行调低。
四、总结
理解 CPU 是如何读写数据的前提,是要理解 CPU 的架构,CPU 内部的多个 Cache + 外部的内存和磁盘都就构成了金字塔的存储器结构,在这个金字塔中,越往下,存储器的容量就越大,但访问速度就会小。
CPU 读写数据的时候,并不是按一个一个字节为单位来进行读写,而是以 CPU Line 大小为单位,CPU Line 大小一般是 64 个字节,也就意味着 CPU 读写数据的时候,每一次都是以 64 字节大小为一块进行操作。
因此,如果我们操作的数据是数组,那么访问数组元素的时候,按内存分布的地址顺序进行访问,这样能充分利用到 Cache,程序的性能得到提升。但如果操作的数据不是数组,而是普通的变量,并在多核 CPU 的情况下,我们还需要避免 Cache Line 伪共享的问题。
所谓的 Cache Line 伪共享问题就是,多个线程同时读写同一个 Cache Line 的不同变量时,而导致 CPU Cache 失效的现象。那么对于多个线程共享的热点数据,即经常会修改的数据,应该避免这些数据刚好在同一个 Cache Line 中,避免的方式一般有 Cache Line 大小字节对齐,以及字节填充等方法。
系统中需要运行的多线程数一般都会大于 CPU 核心,这样就会导致线程排队等待 CPU,这可能会产生一定的延时,如果我们的任务对延时容忍度很低,则可以通过一些人为手段干预 Linux 的默认调度策略和优先级。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)