配置一下"可能需要修改的参数",就可以食用底部代码了,ps:可能已失效
- 本文章代码功能
- 准备工作
-
- 可能需要修改的参数
- 在CMD中打开一个Chrome浏览器并启用端口给Selenium调用
- 导入模块
- 调用刚打开的Chrome浏览器与Python建立连接
- 全部代码复制可用
- 在c盘新建一个app/chrome文件夹用来存放浏览器数据就行
本文章代码功能
-
淘宝搜索关键词,收集搜索到1到100页根据销量排名的各个商品信息:
- 商品本次排名
- 商品链接
- 商品搜索页的图片链接
- 商品店铺旺旺名称
- 商品标题
- 商品价格
- 商品销量
- 抓取的时间
- 商品ID
-
商品信息写入SQLite数据库,数据库表名为搜索的关键词。
如果商品ID和销量与表中的一样则不写入数据库,如果商品ID有了但是销量不一样则添加这条新的数据,即防止出现完全重复的数据又能记录每个商品在不同时间段销量的变化。
-
第一次写文章,有什么不足的地方欢迎指点和探讨。
-
有收获的话点个赞,让小弟知道还有人在看这篇文章。
-
代码运行样式:
-
数据库样式: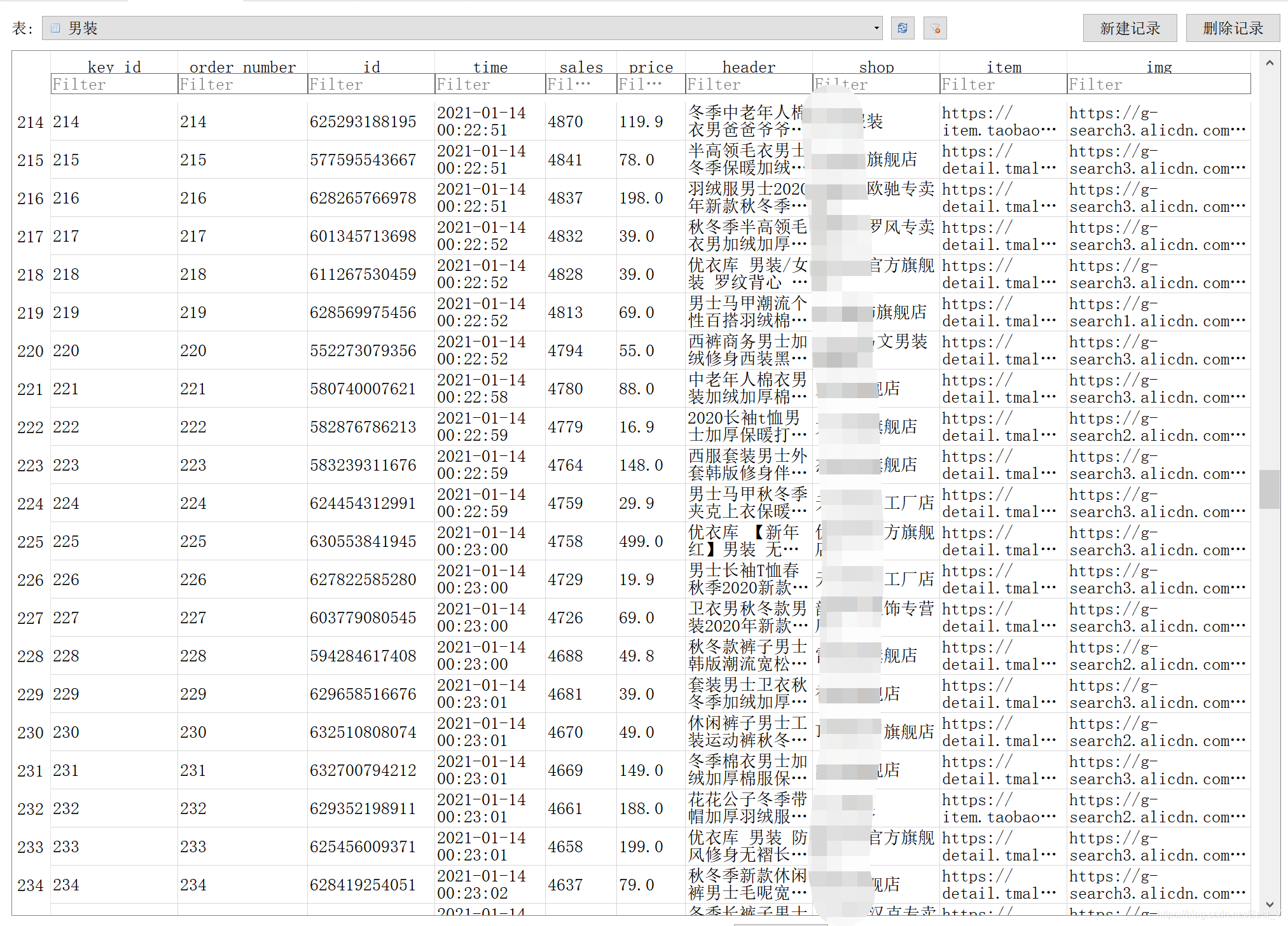
-
测试查询100页没有问题
准备工作
淘宝反爬虫比较严格,所以使用Selenium比较贴近真实使用环境,出现验证滑动条比较容易过。然后用了SQLite数据库来储存数据,要是觉得SQLite数据库用的不方便可以在Python中加条函数导出到Excel。
参考代码:
from xlsxwriter.workbook import Workbook
import sqlite3
workbook = Workbook('output.xlsx')
worksheet = workbook.add_worksheet('男装')
content=sqlite3.connect('content.db')
c=conn.cursor()
ti=c.execute("select * from '男装'")
for i, row in enumerate(ti):
for j, value in enumerate(row):
worksheet.write(i, j, value)
workbook.close()
Python用到的库和准备工作
- Python3.7开发环境
- re库
- time库
- sqlite3库:
- Selenium库 :调用Chrome浏览器的webdriver驱动文件,点击下载chromedrive 。将下载的浏览器驱动文件chromedriver丢到Chrome浏览器目录中的Application文件夹下,配置Chrome浏览器位置到PATH环境。
Selenium 入门参考文献; - SQLite数据库,安装和配置如下:
- SQLite下载链接 ,下载sqlite-tools-win32-**.zip 和 sqlite-dll-win32-*.zip 压缩文件。
- 在盘根目录创建sqlite文件夹,并添加到 PATH 环境变量。解压上面两个压缩文件(得到 sqlite3.def、sqlite3.dll 和 sqlite3.exe 文件)到sqlite文件夹。
- 在命令提示符下,使用 sqlite3 命令,显示如下就是安装成功了:
C:\>sqlite3
SQLite version 3.7.15.2 2013-01-09 11:53:05
Enter ".help" for instructions
Enter SQL statements terminated with a ";"
sqlite>
可能需要修改的参数
在CMD中打开一个Chrome浏览器并启用端口给Selenium调用
remote-debugging-port= 浏览器使用的端口,自己定义一个就行。
user-data-dir= 新打开的浏览器文件目录,自己创建一个就行。
示例代码:
chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\App\Chrome"
第一次创建浏览器文件,在打开浏览器之后最好去登录一下淘宝
导入模块
from selenium import webdriver
import time
import re
import sqlite3
from selenium.webdriver.common.action_chains import ActionChains
调用刚打开的Chrome浏览器与Python建立连接
配置Chrome浏览浏览器
chromedriver.exe的目录根据自己放的位置自行修改
增加一个js代码,在页面打开前修改windows.navigator.webdriver检测结果为undefined
代码如下:
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
chrome_driver = r"C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe"
Chrome = webdriver.Chrome(chrome_driver, options=chrome_options)
Chrome.set_window_position(x=1000, y=353)
Chrome.set_window_size(width=900, height=500)
Chrome.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""})
全部代码复制可用
路径配置没问题的话,新建一个.py文件就可以用了。
2021年1月24日更新代码
在c盘新建一个app/chrome文件夹用来存放浏览器数据就行
数据库中的两个值解读:
- key_id :主键,自增加的不用理会
- order_number:本次运行中的排名,每次运行都是从1开始添加的
from selenium import webdriver
import time
import re
import os
import sqlite3
from selenium.webdriver.common.action_chains import ActionChains
'''
根据关键词,在淘宝搜索页面按照销量排序,收集商品信息.
在cmd中运行: chrome.exe --remote-debugging-port=9222 --user-data-dir=""
数据库表查询:先根据id选取唯一值,根据time时间排序,根据sales观察销量变化
'''
def open_chrome():
user_port = input('输入要使用的端口(回车默认9222):') or 9222
find_port = os.popen('netstat -ano|findstr {}'.format(user_port)).read()
while str(user_port) in find_port:
print(user_port, '端口已被占用,正在更换端口')
user_port += 1
find_port = os.popen('netstat -ano|findstr {}'.format(user_port)).read()
os.system(r'start chrome.exe --remote-debugging-port={} --user-data-dir="C:\app\chrome"'.format(user_port))
print('使用端口:',user_port)
class ItemClass:
def __init__(self, url_keyword, user_page):
self.url_keyword = url_keyword
self.user_page = user_page
self.img_url = None
self.item_url = None
self.sales = None
self.price = None
self.detail_head = None
self.shop_name = None
self.order_number = 0
self.t_dic = []
self.conn = None
self.cursor = None
self.img_err = 0
self.err_log = []
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:{}".format(user_port))
chrome_driver = r"C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe"
try:
self.Chrome = webdriver.Chrome(chrome_driver, options=chrome_options)
except Exception as err:
print('开启浏览器错误:\n', err)
print(r'cmd中打开chrome.exe --remote-debugging-port=9222 --user-data-dir=""')
self.err_log.append(err)
self.Chrome.set_window_position(x=1000, y=353)
self.Chrome.set_window_size(width=900, height=500)
self.Chrome.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""})
def searchwords(self):
self.Chrome.get('https://taobao.com')
self.Chrome.find_element_by_xpath('//*[@id="q"]').send_keys('{}'.format(self.url_keyword))
time.sleep(0.3)
self.Chrome.find_element_by_xpath('//button[@class="btn-search tb-bg"]').click()
def intercept(self):
if '验证码拦截' in self.Chrome.title:
print('滑动验证码')
slider = self.Chrome.find_element_by_xpath("//span[contains(@class, 'btn_slide')]")
try:
if slider.is_displayed():
ActionChains(self.Chrome).click_and_hold(on_element=slider).perform()
ActionChains(self.Chrome).move_by_offset(xoffset=258, yoffset=0).perform()
ActionChains(self.Chrome).pause(0.5).release().perform()
except Exception as err:
print('验证码滑动出错')
print(err)
self.err_log.append(err)
time.sleep(1)
def scrolldown(self):
y_plus = 450
y = 0
for i in range(9):
y += y_plus
self.Chrome.execute_script("window.scroll(0,{})".format(y))
time.sleep(0.2)
def scrolldown_two(self):
t = True
y = 400
x = self.Chrome.execute_script("return document.body.scrollHeight;")
while t:
check_height = self.Chrome.execute_script("return document.body.scrollHeight;")
x += y
self.Chrome.execute_script("window.scroll(0,{})".format(x))
time.sleep(0.5)
check_height1 = self.Chrome.execute_script("return document.body.scrollHeight;")
if check_height == check_height1:
t = False
self.Chrome.execute_script("window.scroll(0,200)")
def sales_sort(self):
time.sleep(1)
self.Chrome.find_element_by_xpath('//a[@data-value="sale-desc"]').click()
def click_next(self):
self.Chrome.execute_script("window.scroll(400,150)")
self.Chrome.find_element_by_xpath('//a[@title="下一页"]').click()
time.sleep(1)
def get_content(self):
time.sleep(0.2)
self.scrolldown()
time.sleep(0.5)
for item in self.Chrome.find_elements_by_xpath('.//*[@class="item J_MouserOnverReq "]'):
try:
self.order_number += 1
self.img_url = \
item.find_element_by_xpath('.//*[@class="J_ItemPic img"]').get_attribute('src').split('_360')[0]
self.item_url = item.find_element_by_xpath('.//*[@class="pic-link J_ClickStat J_ItemPicA"]')\
.get_attribute('href').split('&')[0]
sales_tem = item.find_element_by_xpath('.//*[@class="deal-cnt"]').text
self.sales = int(''.join(re.findall(r'\d*\d', sales_tem)))
self.price = float(item.find_element_by_xpath('.//*[@class="price g_price g_price-highlight"]/strong').text)
self.detail_head = item.find_element_by_xpath('.//*[@class="J_ItemPic img"]').get_attribute('alt')
self.shop_name = item.find_element_by_xpath('.//*[@class="shopname J_MouseEneterLeave J_ShopInfo"]').text
if '万' in sales_tem:
self.sales = int(float(re.findall(r'\d+.\d*', sales_tem)[0])*10000)
if '.gif' in self.img_url:
self.img_err += 1
print('排名第{}位:\t销量:{}件,\t价格为:{}元, \t店铺名:{}, \t图片错误:{}'.format(self.order_number, self.sales, self.price, self.shop_name, self.img_url))
else:
print('排名第{}位:\t销量:{}件,\t价格为:{}元, \t店铺名:{}'.format(self.order_number, self.sales, self.price, self.shop_name))
self.t_dic = [self.item_url, self.img_url, self.shop_name, self.detail_head, self.price, self.sales]
self.save_content_one()
except Exception as err:
print('第{}号出错,出错代码为: '.format(self.order_number), err)
self.err_log.append('第{}号,出错代码为:{} '.format(self.order_number, err))
continue
def save_content(self):
t_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
id_and_table_name = int(self.item_url.split('=')[1])
self.t_dic.append(t_time)
self.t_dic.append(id_and_table_name)
sql_if_exists = '''
CREATE TABLE IF NOT EXISTS [{}] (
sales INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
order_number INT,
id INT,
time TEXT,
price REAL,
header TEXT,
shop TXEXT,
item TEXT,
img TEXT);
'''
sql_insert_or_ignore = '''
INSERT INTO [{0}] (order_number,id,time,sales,price,header,shop,img,item) \
SELECT '{2}',{1[7]},'{1[6]}','{1[5]}','{1[4]}','{1[3]}','{1[2]}','{1[1]}','{1[0]}'
WHERE NOT EXISTS (SELECT *FROM [{0}] WHERE id='{1[7]}' AND sales='{1[5]}');
'''
self.cursor.execute(sql_if_exists.format(id_and_table_name))
self.cursor.execute(sql_insert_or_ignore.format(id_and_table_name, self.t_dic, self.order_number))
self.conn.commit()
self.t_dic = []
def save_content_one(self):
t_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
t_id = int(self.item_url.split('=')[1])
self.t_dic.append(t_time)
self.t_dic.append(t_id)
table_name = self.url_keyword
sql_if_exists = '''
CREATE TABLE IF NOT EXISTS [{}] (
key_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
order_number INT,
id INT,
time TEXT,
sales INT,
price REAL,
header TEXT,
shop TXEXT,
item TEXT,
img TEXT);
'''
sql_insert_or_ignore = '''
INSERT INTO [{0}] (order_number,id,time,sales,price,header,shop,img,item) \
SELECT '{2}',{1[7]},'{1[6]}','{1[5]}','{1[4]}','{1[3]}','{1[2]}','{1[1]}','{1[0]}'
WHERE NOT EXISTS (SELECT *FROM [{0}] WHERE id='{1[7]}' AND sales='{1[5]}');
'''
self.cursor.execute(sql_if_exists.format(table_name))
self.cursor.execute(sql_insert_or_ignore.format(table_name, self.t_dic, self.order_number))
self.conn.commit()
self.t_dic = []
def start(self, t_path=r'content.db'):
print('开始运行')
self.conn = sqlite3.connect(t_path)
self.cursor = self.conn.cursor()
get_page = 0
self.searchwords()
time.sleep(1)
self.intercept()
self.sales_sort()
try:
while get_page < self.user_page:
get_page += 1
print('抓取第{}页:'.format(get_page))
self.get_content()
if get_page != self.user_page:
self.click_next()
except Exception as err:
print('出现错误:', err)
self.err_log.append(err)
self.cursor.close()
self.conn.commit()
self.conn.close()
else:
print('抓取结束一共抓取了{}位'.format(self.order_number))
self.cursor.close()
self.conn.commit()
self.conn.close()
if __name__ == '__main__':
start_time = time.time()
user_port = 9222
open_chrome()
browser = ItemClass(url_keyword=input('输入要查询的关键词(默认男童):') or '男童', user_page=int(input('查询的页数(默认10):') or 10))
browser.start()
end_time = time.time()
run_time = '%.2f' % (end_time-start_time)
print('运行了:{}秒'.format(run_time))
with open('log.txt', 'a+') as f:
f.write('\n程序运行结束日期:{}\n抓取数量:{}\n使用时间:{}秒\n图片获取错误:{}个\n程序出错信息:{}个\n'.format
(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())),
browser.order_number, run_time, browser.img_err, len(browser.err_log)))
for err_tosrt in browser.err_log:
f.write(str(err_tosrt)+'\n')
==如果有收获、点个赞哦=
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)