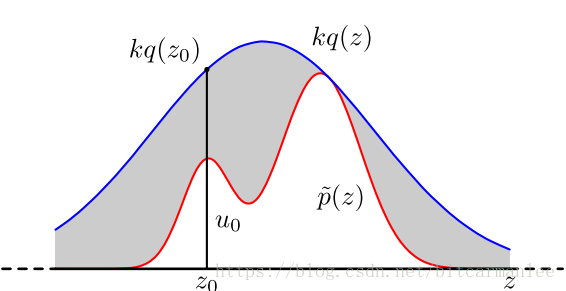
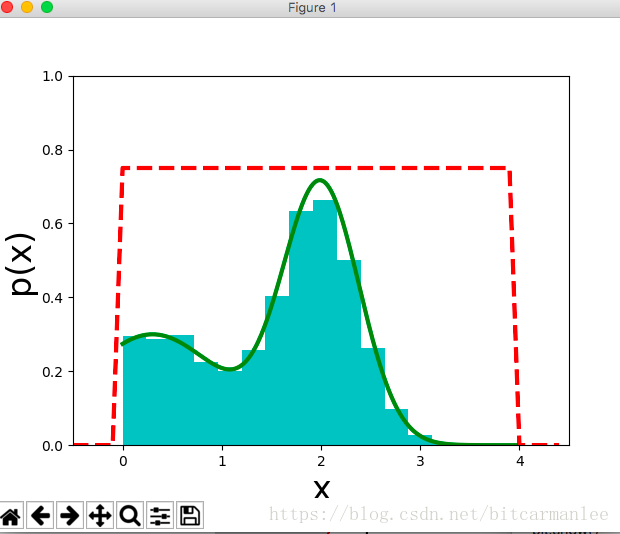
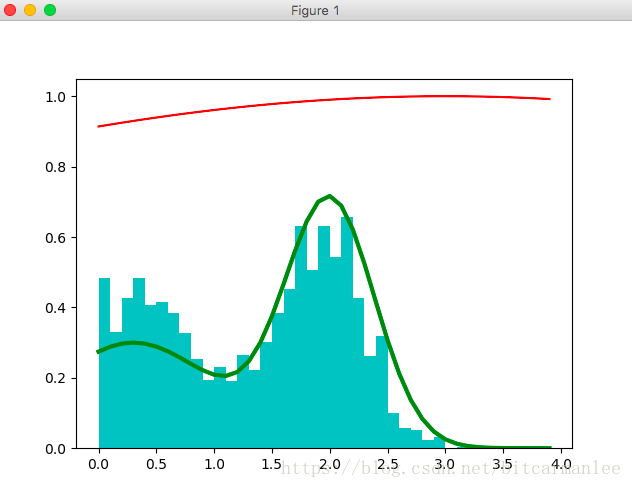
均匀分布式是一种最简单的分布。在计算机中生成[0,1]之间的伪随机数序列,就可以看做是一种均匀分布。随机数生成的方法有很多,比较简单的一种方式比如:
x
n
+
1
=
(
a
x
n
+
c
)
m
o
d
m
x_{n+1} = (ax_n + c) \ mod \ m
xn+1=(axn+c)modm
当然计算机中产生的随机数一般都是伪随机数,不过在绝大部分场景下也够用了。
3.离散分布采样
离散分布是比均匀分布稍微复杂一点的情况。例如令
p
(
x
)
=
[
0.1
,
0.2
,
0.3
,
0.4
]
p(x) = [0.1, 0.2, 0.3, 0.4]
p(x)=[0.1,0.2,0.3,0.4],那么我们可以把概率分布的向量看做一个区间段,然后从
x
∼
U
(
0
,
1
)
x \sim U_{(0,1)}
x∼U(0,1)分布中采样,判断x落在哪个区间内。区间长度与概率成正比,这样当采样的次数越多,采样就越符合原来的分布。 举个例子,假设
p
(
x
)
=
[
0.1
,
0.2
,
0.3
,
0.4
]
p(x) = [0.1, 0.2, 0.3, 0.4]
p(x)=[0.1,0.2,0.3,0.4],分别为"hello", “java”, “python”, "scala"四个词出现的概率。我们按照上面的算法实现看看最终的结果
import numpy as np
from collections import defaultdict
dic = defaultdict(int)
def sample():
u = np.random.rand()
if u <= 0.1:
dic["hello"] += 1
elif u <= 0.3:
dic["java"] += 1
elif u <= 0.6:
dic["python"] += 1
else:
dic["scala"] += 1
def sampleNtimes():
for i in range(10000):
sample()
for k,v in dic.items():
print k,v
sampleNtimes()
代码输出结果:
python 3028
java 2006
hello 971
scala 3995
上面的采样方法,基本满足我们的要求。
4. Box-Muller算法
如果概率密度分布函数
p
(
x
)
p(x)
p(x)是连续分布,如果这个分布可以计算累积分布函数(Cumulative Distribution Function, CDF),可以通过计算CDF的反函数,获得采样。
如果随机变量
U
1
U_1
U1,
U
2
U_2
U2是IID独立同分布,且
U
1
,
U
2
∼
U
n
i
f
o
r
m
[
0
,
1
]
U_1, U_2 \sim Uniform[0, 1]
U1,U2∼Uniform[0,1],那么有:
Z
0
=
−
2
l
n
U
1
c
o
s
(
2
π
U
2
)
Z_0 = \sqrt{-2ln U_1} cos(2 \pi U_2)
Z0=−2lnU1cos(2πU2)
Z
1
=
−
2
l
n
U
1
s
i
n
(
2
π
U
2
)
Z_1 = \sqrt{-2ln U_1} sin(2 \pi U_2)
Z1=−2lnU1sin(2πU2)
Z
0
,
Z
1
Z_0, Z_1
Z0,Z1独立且服从标准正态分布。 具体证明过程可以见参考文献2。
Box–Muller变换最初由 George E. P. Box 与 Mervin E. Muller 在1958年提出。George E. P. Box 是统计学的一代大师,统计学中的很多名词术语都以他的名字命名。Box 之于统计学的家学渊源相当深厚,他的导师是 统计学开山鼻祖 皮尔逊的儿子,英国统计学家Egon Pearson,同时Box还是统计学的另外一位巨擘级奠基人 费希尔 的女婿。统计学中的名言“all models are wrong, but some are useful”(所有模型都是错的,但其中一些是有用的)也出自Box之口
利用Box-Muller变换生成高斯分布随机数的方法可以总结为以下步骤: 1.生成两个随机数
U
1
,
U
2
∼
U
[
0
,
1
]
U_1, U_2 \sim U[0,1]
U1,U2∼U[0,1] 2.令
R
=
−
2
l
n
(
u
1
)
R = \sqrt{-2ln(u_1)}
R=−2ln(u1),
θ
=
2
π
U
2
\theta = 2 \pi U_2
θ=2πU2 3.
z
0
=
R
c
o
s
θ
,
z
1
=
R
s
i
n
θ
z_0 = Rcos \theta, z_1 = Rsin \theta
z0=Rcosθ,z1=Rsinθ
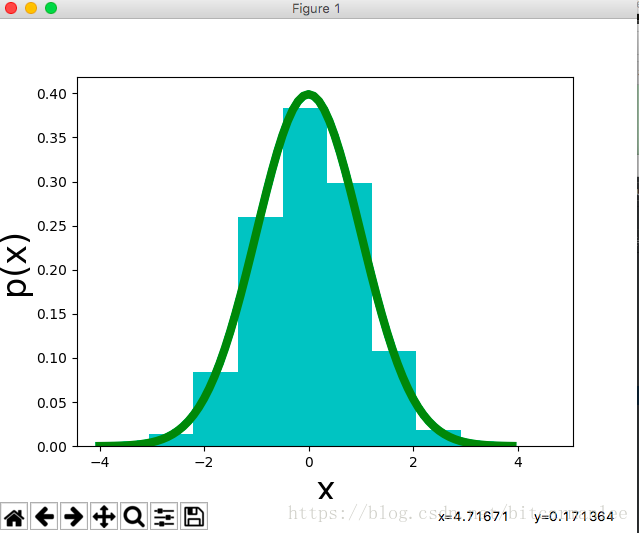
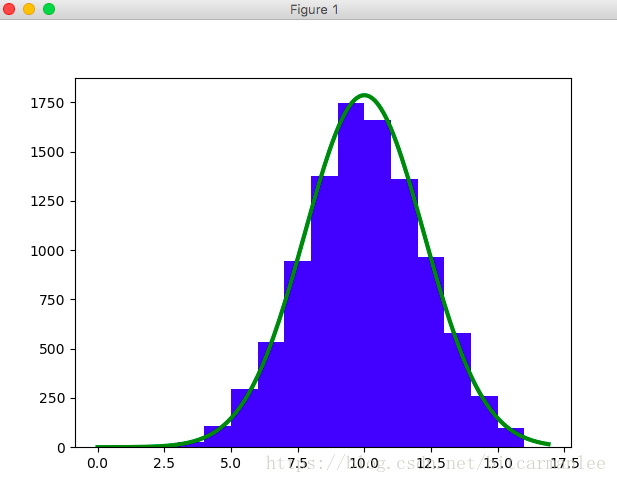
按上面的步骤生成正态分布的抽样:
import numpy as np
from pylab import *
def sample():
x = np.random.rand() # 两个均匀分布分别为x, y
y = np.random.rand()
R = np.sqrt(-2 * np.log(x))
theta = 2 * np.pi * y
z0 = R * np.cos(theta)
#z1 = R * np.sin(theta)
return z0
def sampleNtimes():
list = []
n = 100000
for i in range(n):
x = sample()
list.append(x)
y = np.reshape(list, n, 1)
hist(y, normed=1, fc='c') # 直方图
x = arange(-4, 4, 0.1)
plot(x, 1 / np.sqrt(2 * np.pi) * np.exp(-0.5 * x ** 2), 'g', lw=6) # 标准正态分布
xlabel('x', fontsize = 24)
ylabel('p(x)', fontsize = 24)
show()
sampleNtimes()
MCMC采样方法中的两个MC,分别指的是马尔可夫链Markov Chain与蒙特卡洛算法。关于蒙特卡洛算法,前面写的蒙特卡洛算法有专门分析过,见参考文献3。关于马尔可夫链见参考文献4。 之前提到的抽样方法都是可以并行的。换句话说,后面的样本跟前面的样本没关系。而MCMC是一个链式抽样的过程,每一个抽样的样本跟且只跟前面的一个样本有关系。 由平稳马尔可夫过程的结论可知: 1.不论初始状态为啥,只要该马尔科夫链收敛,第n次的抽样概率
p
(
x
n
)
p(x^n)
p(xn)一定会收敛到我们预期的分布
p
(
x
)
p(x)
p(x) 2.如果非周期马尔科夫链的状态转移矩阵P和概率分布π(x)对于所有的i,j满足:
π
(
i
)
P
(
i
,
j
)
=
π
(
j
)
P
(
j
,
i
)
\pi(i) P(i, j) = \pi(j) P(j, i)
π(i)P(i,j)=π(j)P(j,i) 则称概率分布π(x)是状态转移矩阵P的平稳分布。
由于马氏链能收敛到平稳分布, 于是一个很的漂亮想法是:如果我们能构造一个转移矩阵为
P
P
P的马氏链,使得该马氏链的平稳分布恰好是p(x),那么我们从任何一个初始状态
x
0
x_0
x0出发沿着马氏链转移, 得到一个转移序列
x
0
,
x
1
,
⋯
,
x
n
,
x
n
+
1
,
⋯
x_0, x_1, \cdots, x_n, x_{n+1}, \cdots
x0,x1,⋯,xn,xn+1,⋯。如果马氏链在第n步已经收敛,那么
x
n
+
1
x_{n+1}
xn+1以后的样本必然都满足p(x)分布,就达到了我们的抽样样本满足概率为p(x)分布的条件。
由于一般情况下,目标平稳分布
π
(
x
)
\pi(x)
π(x)和某一个马尔科夫链状态转移矩阵Q不满足细致平稳条件
π
(
i
)
Q
(
i
,
j
)
≠
π
(
j
)
Q
(
j
,
i
)
\pi(i) Q(i, j) \ne \pi(j) Q(j,i)
π(i)Q(i,j)=π(j)Q(j,i) 为了使细致平稳条件成立,可以这样做:
π
(
i
)
Q
(
i
,
j
)
α
(
i
,
j
)
=
π
(
j
)
Q
(
j
,
i
)
α
(
j
,
i
)
\pi(i) Q(i, j) \alpha(i,j) = \pi(j) Q(j,i) \alpha(j,i)
π(i)Q(i,j)α(i,j)=π(j)Q(j,i)α(j,i) 为了两边相等,可以取
α
(
i
,
j
)
=
π
(
j
)
Q
(
j
,
i
)
\alpha(i, j) = \pi(j) Q(j,i)
α(i,j)=π(j)Q(j,i)
α
(
j
,
i
)
=
π
(
i
)
Q
(
i
,
j
)
\alpha(j, i) = \pi(i) Q(i, j)
α(j,i)=π(i)Q(i,j) 这样,转移矩阵
P
P
P最后就变成为:
P
(
i
,
j
)
=
Q
(
i
,
j
)
α
(
i
,
j
)
P(i,j) = Q(i, j) \alpha(i, j)
P(i,j)=Q(i,j)α(i,j) 也就是说,目标矩阵
P
P
P可以通过任意一个马尔科夫链状态转移矩阵Q乘以
α
(
i
,
j
)
\alpha(i,j)
α(i,j)得到,
α
(
i
,
j
)
\alpha(i,j)
α(i,j)一般称为接受率,取值在[0,1]之间,即目标矩阵P 可以通过任意一个马尔科夫链状态转移矩阵Q以一定的接受率获得。与前面的拒绝采样比较,拒绝采样是以一个常用的分布通过一定的拒绝率获得一个非常见的分布。而MCMC则是以一个常见的马尔科夫链状态转移矩阵Q通过一定的拒绝率得到目标转移矩阵P,两者思路类似。
总结一下上面的过程,MCMC采样算法的过程为: 1.初始化马尔科夫链初始状态为
X
0
=
x
0
X_0 = x_0
X0=x0 2.循环采样过程如下: 2.1 第t个时刻马尔科夫链状态为
X
t
=
x
t
X_t = x_t
Xt=xt,由转移矩阵
Q
(
x
)
Q(x)
Q(x)中采样得到
y
∼
q
(
x
∣
x
t
)
y \sim q(x | x_t)
y∼q(x∣xt) 2.2 从均匀分布采样
u
∼
U
n
i
f
o
r
m
[
0
,
1
]
u \sim Uniform[0,1]
u∼Uniform[0,1] 2.3 如果
u
<
α
(
x
t
,
y
)
=
p
(
y
)
q
(
y
,
x
t
)
u <\alpha(x_t, y) = p(y) q(y, x_t)
u<α(xt,y)=p(y)q(y,xt),则接受转移
x
t
→
y
x_t \to y
xt→y,
X
t
+
1
=
y
X_{t+1} = y
Xt+1=y 2.4 否则不接受转移,即
X
t
+
1
=
x
t
X_{t+1} = x_t
Xt+1=xt
看,我们提高了接受率,而细致平稳条件并没有打破!这启发我们可以把细致平稳条件中的α(i,j),α(j,i) 同比例放大,使得两数中最大的一个放大到1,这样我们就提高了采样中的跳转接受率。所以我们可以取
α
(
i
,
j
)
=
m
i
n
{
p
(
j
)
q
(
j
,
i
)
p
(
i
)
q
(
i
,
j
)
,
1
}
\alpha(i, j) = min\{\frac{p(j)q(j, i)}{p(i)q(i,j)}, 1\}
α(i,j)=min{p(i)q(i,j)p(j)q(j,i),1}
经过以上细微的变化,我们就得到了如下教科书中最常见的 Metropolis-Hastings 算法。 1.初始化马尔科夫链初始状态为
X
0
=
x
0
X_0 = x_0
X0=x0 2.循环采样过程如下: 2.1 第t个时刻马尔科夫链状态为
X
t
=
x
t
X_t = x_t
Xt=xt,由转移矩阵
Q
(
x
)
Q(x)
Q(x)中采样得到
y
∼
q
(
x
∣
x
t
)
y \sim q(x | x_t)
y∼q(x∣xt) 2.2 从均匀分布采样
u
∼
U
n
i
f
o
r
m
[
0
,
1
]
u \sim Uniform[0,1]
u∼Uniform[0,1] 2.3 如果
u
<
α
(
x
t
,
y
)
=
m
i
n
{
p
(
j
)
q
(
j
,
i
)
p
(
i
)
q
(
i
,
j
)
,
1
}
u <\alpha(x_t, y) = min\{\frac{p(j)q(j, i)}{p(i)q(i,j)}, 1\}
u<α(xt,y)=min{p(i)q(i,j)p(j)q(j,i),1},则接受转移
x
t
→
y
x_t \to y
xt→y,
X
t
+
1
=
y
X_{t+1} = y
Xt+1=y 2.4 否则不接受转移,即
X
t
+
1
=
x
t
X_{t+1} = x_t
Xt+1=xt (以上部分内容来自参考文献5)
吉布斯采样(Gibbs sampling)是统计学中用于马尔科夫蒙特卡洛(MCMC)的一种算法,用于在难以直接采样时从某一多变量概率分布中近似抽取样本序列。该序列可用于近似联合分布、部分变量的边缘分布或计算积分(如某一变量的期望值)。某些变量可能为已知变量,故对这些变量并不需要采样。 在高维的情况下,由于接受率
α
\alpha
α的存在,Metropolis-Hastings算法效率不够高。如果能找到一个转移矩阵Q使得
α
=
1
\alpha = 1
α=1,那么抽样的效率会大大提高。 先看看二维的情况。假设有一个概率分布
p
(
x
,
y
)
p(x,y)
p(x,y),x坐标相同的两个点
A
(
x
1
,
y
1
)
,
B
(
x
1
,
y
2
)
A(x_1, y_1), B(x_1, y_2)
A(x1,y1),B(x1,y2),有:
p
(
x
1
,
y
1
)
p
(
y
2
∣
x
1
)
=
p
(
x
1
)
p
(
y
1
∣
x
1
)
p
(
y
2
∣
x
1
)
p
(
x
1
,
y
2
)
p
(
y
1
∣
x
1
)
=
p
(
x
1
)
p
(
y
2
∣
x
1
)
p
(
y
1
∣
x
1
)
p(x_1, y_1) p(y_2 | x_1) = p(x_1)p(y_1|x_1)p(y_2|x_1) \\ p(x_1, y_2) p(y_1 | x_1) = p(x_1)p(y_2|x_1)p(y_1|x_1)
p(x1,y1)p(y2∣x1)=p(x1)p(y1∣x1)p(y2∣x1)p(x1,y2)p(y1∣x1)=p(x1)p(y2∣x1)p(y1∣x1) 很容易得到
p
(
x
1
,
y
1
)
p
(
y
2
∣
x
1
)
=
p
(
x
1
,
y
2
)
p
(
y
1
∣
x
1
)
p(x_1, y_1) p(y_2 | x_1) = p(x_1, y_2) p(y_1 | x_1)
p(x1,y1)p(y2∣x1)=p(x1,y2)p(y1∣x1) 即
p
(
A
)
p
(
y
2
∣
x
1
)
=
p
(
B
)
p
(
y
1
∣
x
1
)
p(A) p(y_2 | x_1) = p(B) p(y_1 | x_1)
p(A)p(y2∣x1)=p(B)p(y1∣x1)
通过上面的式子,我们发现在
x
=
x
1
x = x_1
x=x1这条平行于y轴的直线上,如果使用条件分布
p
(
y
∣
x
1
)
p(y|x_1)
p(y∣x1)作为任意两个点之间的转移概率,那么任意两个点之间的转移满足细致平稳条件。同理,如果在
y
=
y
1
y = y_1
y=y1这条直线上任意去两个点
A
(
x
1
,
y
1
)
,
C
(
x
2
,
y
1
)
A(x_1,y_1), C(x_2, y_1)
A(x1,y1),C(x2,y1),有如下等式
p
(
A
)
p
(
x
2
∣
y
1
)
=
p
(
C
)
p
(
x
1
∣
y
1
)
p(A) p(x_2 | y_1) = p(C) p(x_1 | y_1)
p(A)p(x2∣y1)=p(C)p(x1∣y1)
我们可以如下构造平面上任意两点之间的转移概率矩阵Q
Q
(
A
→
B
)
=
p
(
y
B
∣
x
1
)
i
f
x
A
=
x
B
=
x
1
Q
(
A
→
C
)
=
p
(
x
C
∣
y
1
)
i
f
y
A
=
y
C
=
y
1
Q
(
A
→
D
)
=
0
o
t
h
e
r
s
Q(A \to B) = p(y_B|x_1) \qquad if x_A = x_B = x_1 \\ Q(A \to C) = p(x_C|y_1) \qquad if y_A = y_C = y_1 \\ Q(A \to D) = 0 \qquad others
Q(A→B)=p(yB∣x1)ifxA=xB=x1Q(A→C)=p(xC∣y1)ifyA=yC=y1Q(A→D)=0others
于是这个二维空间上的马氏链将收敛到平稳分布 p(x,y)。而这个算法就称为 Gibbs Sampling 算法,是 Stuart Geman 和Donald Geman 这两兄弟于1984年提出来的,之所以叫做Gibbs Sampling 是因为他们研究了Gibbs random field, 这个算法在现代贝叶斯分析中占据重要位置。
则二维Gibbs Sampling的算法为: 1随机初始化
X
0
=
x
0
,
Y
0
=
y
0
X_0 = x_0, Y_0 = y_0
X0=x0,Y0=y0 2.循环采样 2.1
y
t
+
1
∼
p
(
y
∣
x
t
)
y_{t+1} \sim p(y|x_t)
yt+1∼p(y∣xt) 2.2
x
t
+
1
∼
p
(
x
∣
y
t
+
1
)
x_{t+1} \sim p(x|y_{t+1})
xt+1∼p(x∣yt+1)