一、原因
多线程对爬虫的效率提高是非凡的,当我们使用python的多线程有几点是需要我们知道的:
1.Python的多线程并不如java的多线程,其差异在于当python解释器开始执行任务时,受制于GIL(全局解释所),Python 的线程被限制到同一时刻只允许一个程执行这样一个执行模型。
2.Python 的线程更适用于处理 I/O 和其他需要并发行的阻塞操作(比如等待 I/O、等待从数据库获取数据等等),而不是需要多处理器行的计算密集型任务。幸运的是,爬虫大部分时间在网络交互上,所以可以使用多线程来编写爬虫。
3.这点其实和多线程关系不大,scrapy的并发并不是采用多线程来实现,它是一个twisted应用,通过异步非阻塞来达到并发,这个后面我会写文章来讲解。
4.Python中当你想要提高执行效率,大部分开发者是通过编写多进程来提高运行效率,使用multiprocessing进行并行编程,当然,你可以编写多进程爬虫来爬取信息,缺点是每个进程都会有自己的内存,数据多的话,内存会吃不消。
5.使用线程有什么缺点呢,缺点就是你在编写多线程代码时候,要注意死锁的问题、阻塞的问题、以及需要注意多线程之间通信的问题(避免多个线程执行同一个任务)。
二、了解threading
我们通过 threading 模块来编写多线程代码,或者你可以使用 from concurrent.futures import ThreadPoolExecutor (线程池)也可以达到同样的目的,线程池的知识我会在后续讲。
我们先看怎么编写线程代码,以及它如何使用,简单的示例:
import time
from threading import Thread
def countdown(n):
while n > 0:
print('T-minus', n)
n -= 1
time.sleep(5)
t = Thread(target=countdown, args=(10,))
t.start()
countdown是一个计数的方法,正常执行它,我们一般使用countdown(10),就可以达到执行的目的,当你通过线程去调用它时,首先你需要从threading模块中引入Thread,然后,t = Thread(target=countdown, args=(10,)),当你创建好一个线程对象后,该对象并不会立即执行,除非你调用它的 start方法(当你调用 start() 方法时,它会调用你传递进来的函数,并把你传递进来的数传递给该函数),这就是一个简单的线程执行的例子。
你可以查询一个线程对象的状态,看它是否还执行:
if t.is_alive():
print('Still running')
else:
print('Completed, Go out !')
Python 解释器直到所有线程都终止前仍保持运行。对于需要长时间运行的线程或
者需要一直运行的后台任务,你应当考虑使用后台线程。
t = Thread(target=countdown, args=(10,), daemon=True)
t.start()
如果你需要终止线程,那么这个线程必须通过编程在某个特定点轮询来退
出。你可以像下边这样把线程放入一个类中:
class CountDownTask:
def __init__(self):
self._running = True
def terminate(self):
self._running = False
def run(self, n):
while self._running and n > 0:
print('T-minus', n)
n -= 1
time.sleep(5)
if __name__ == '__main__':
c = CountDownTask()
t = Thread(target=c.run, args=(10,))
t.start()
c.terminate()
t.join()
三、多线程初体验
上面的代码都是单线程,下面我们来看看多线程,并使用它来编写多线程爬虫,不过,在真正编写多线程爬虫之前,我们还要为编写多线程做准备,如何保持各线程之间的通信,在这里,我们使用队列Queue作为多线程之间通信的桥梁。
首先,创建一个被多个线程共享的 Queue 对象,这些线程通过使用 put() 和 get() 操来向队列中添加或者删除元素。
from queue import Queue
from threading import Thread
def producer(out_q):
while True:
out_q.put(1)
def consumer(in_q):
while True:
data = in_q.get()
if __name__ == '__main__':
q = Queue()
t1 = Thread(target=consumer, args=(q, ))
t2 = Thread(target=producer, args=(q, ))
t1.start()
t2.start()
上面的produecer(生产者)和consumer(消费者),是两个不同的线程,它们共用一个队列:q,当生产者生产了数据后,消费者会拿到,然后消费它,所以不用担心,产生其他相同的数据。值得注意的是:尽管列是最常见的线程间通信机制,但是仍然可以自己通过创建自己的数据结构并添加需的锁和同步机制来实现线程间通信。
下面我们来编写一个简单的多线程爬虫,方法写的比较臃肿,正常情况下不应该这么写,作为简易的例子我就这么写了:
import re
import time
import requests
import threading
from lxml import etree
from bs4 import BeautifulSoup
from queue import Queue
from threading import Thread
def run(in_q, out_q):
headers = {
'Accept': '',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Cookie': '',
'DNT': '1',
'Host': 'www.g.com',
'Referer': '',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
while in_q.empty() is not True:
data = requests.get(url=in_q.get(), headers=headers)
r = data.content
content = str(r, encoding='utf-8', errors='ignore')
soup = BeautifulSoup(content, 'html5lib')
fixed_html = soup.prettify()
html = etree.HTML(fixed_html)
nums = html.xpath('//div[@class="col-md-1"]//text()')
for num in nums:
num = re.findall('[0-9]', ''.join(num))
real_num = int(''.join(num))
out_q.put(str(threading.current_thread().getName()) + '-' + str(real_num))
in_q.task_done()
if __name__ == '__main__':
start = time.time()
queue = Queue()
result_queue = Queue()
for i in range(1, 1001):
queue.put('http://www.g.com?page='+str(i))
print('queue 开始大小 %d' % queue.qsize())
for index in range(10):
thread = Thread(target=run, args=(queue, result_queue, ))
thread.daemon = True
thread.start()
queue.join()
end = time.time()
print('总耗时:%s' % (end - start))
print('queue 结束大小 %d' % queue.qsize())
print('result_queue 结束大小 %d' % result_queue.qsize())

首先构造一个任务队列,一个保存结果的队列。

构造一个1000页的任务队列。

使用十个线程来执行run方法消化任务队列,run方法有两个参数,一个任务队列,一个保存结果的队列。
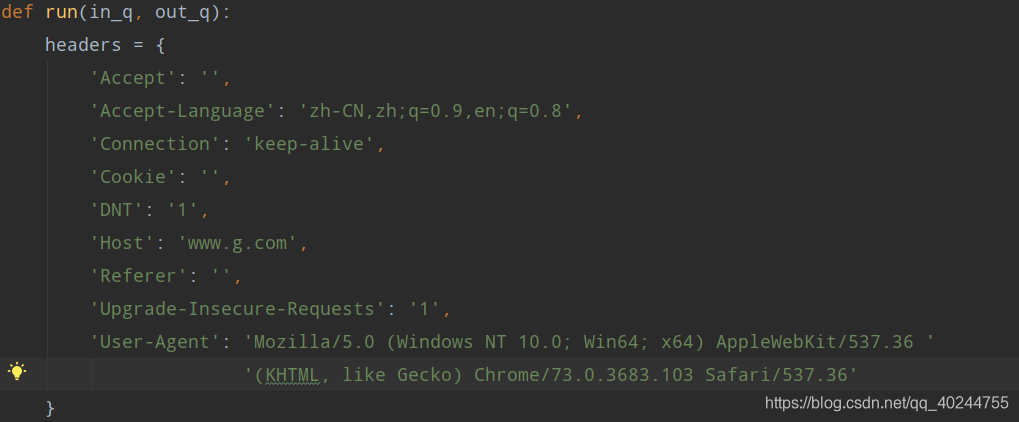
headers是爬虫的请求头。
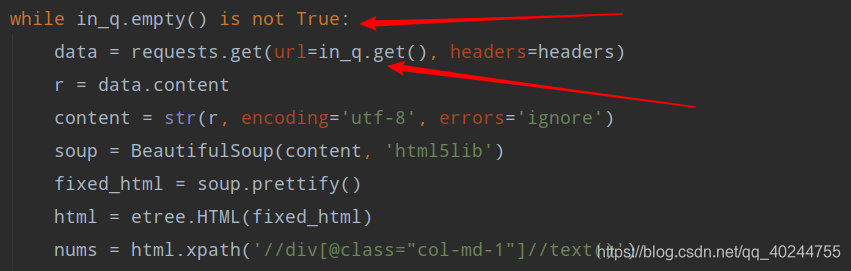
in_q.empty(),是对列的一个方法,它是检测队列是否为空,是一个布尔值,url = in_q.get(),这个操作是拿出队列的一个值出来,然后,把它从队列里删掉。

out_q.put 队列的添加操作,相当于list的append操作。in_q.task_done(),通知对列已经完成任务。
以上,我们就完成了一个多线程爬虫。
一个线程时所消耗的时间:
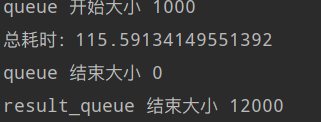
多线程所消耗的时间:

可以看到提升效果还是很多的,人生苦短,有些事情能快则快,爬虫亦然。
4.生产者消费者爬虫
下面实现一个简易的生产者消费者爬虫:
import re
import time
import requests
import threading
from lxml import etree
from bs4 import BeautifulSoup
from queue import Queue
from threading import Thread
def producer(in_q):
ready_list = []
while in_q.full() is False:
for i in range(1, 1001):
url = 'http://www.g.com/?page='+str(i)
if url not in ready_list:
ready_list.append(url)
in_q.put(url)
else:
continue
def consumer(in_q, out_q):
headers = {
'Accept': ‘',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Cookie': ',
'DNT': '1',
'Host': 'www..com',
'Referer': 'http://www.g.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
while True:
data = requests.get(url=in_q.get(), headers=headers)
r = data.content
content = str(r, encoding='utf-8', errors='ignore')
soup = BeautifulSoup(content, 'html5lib')
fixed_html = soup.prettify()
html = etree.HTML(fixed_html)
nums = html.xpath('//div[@class="col-md-1"]//text()')
for num in nums:
num = re.findall('[0-9]', ''.join(num))
real_num = int(''.join(num))
out_q.put(str(threading.current_thread().getName()) + '-' + str(real_num))
in_q.task_done()
if __name__ == '__main__':
start = time.time()
queue = Queue(maxsize=10)
result_queue = Queue()
print('queue 开始大小 %d' % queue.qsize())
producer_thread = Thread(target=producer, args=(queue,))
producer_thread.daemon = True
producer_thread.start()
for index in range(10):
consumer_thread = Thread(target=consumer, args=(queue, result_queue, ))
consumer_thread.daemon = True
consumer_thread.start()
queue.join()
end = time.time()
print('总耗时:%s' % (end - start))
print('queue 结束大小 %d' % queue.qsize())
print('result_queue 结束大小 %d' % result_queue.qsize())
一个线程执行生产,生产者一次生产十个url,十个线程执行消费,代码很简单,读了上面的代码,这部分代码不难理解,我就不解释了。
5.多进程爬虫
python中多进程与多线程有太多相似的地方,例如它们方法大体相同,甚至可以说完全相同,为什么使用多进程呢?当你想提高cpu密集型任务的效率时,你便可以使用多进程来改善这种情况,这里,我使用的是进程池来编写多进程爬虫,如果你不想使用进程池的话,编写多进程任务与多线程类似,只不过,你需要从from multiprocessing import Process方法,使用手法与Thread方法类似,所以我在这里就不多谈了,关于多进程写法的一些东西,我已经写在代码的注释里,需要了解请查看。
import re
import time
import requests
from lxml import etree
from bs4 import BeautifulSoup
import multiprocessing
def run(in_q, out_q):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8'
',application/signed-exchange;v=b3',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Cookie': ‘',
'DNT': '1',
'Host': 'www.g.com',
'Referer': 'http://www.g.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
while in_q.empty() is not True:
data = requests.get(url=in_q.get(), headers=headers)
r = data.content
content = str(r, encoding='utf-8', errors='ignore')
soup = BeautifulSoup(content, 'html5lib')
fixed_html = soup.prettify()
html = etree.HTML(fixed_html)
nums = html.xpath('//div[@class="col-md-1"]//text()')
for num in nums:
num = re.findall('[0-9]', ''.join(num))
real_num = int(''.join(num))
out_q.put(str(real_num))
in_q.task_done()
return out_q
if __name__ == '__main__':
start = time.time()
queue = multiprocessing.Manager().Queue()
result_queue = multiprocessing.Manager().Queue()
for i in range(1, 1001):
queue.put('http://www.g.com2?page='+str(i))
print('queue 开始大小 %d' % queue.qsize())
pool = multiprocessing.Pool(10)
for index in range(1000):
'''
For循环中执行步骤:
(1)循环遍历,将1000个子进程添加到进程池(相对父进程会阻塞)
(2)每次执行10个子进程,等一个子进程执行完后,立马启动新的子进程。(相对父进程不阻塞)
apply_async为异步进程池写法。异步指的是启动子进程的过程,与父进程本身的执行(爬虫操作)是异步的,
而For循环中往进程池添加子进程的过程,与父进程本身的执行却是同步的。
'''
pool.apply_async(run, args=(queue, result_queue,))
pool.close()
pool.join()
queue.join()
end = time.time()
print('总耗时:%s' % (end - start))
print('queue 结束大小 %d' % queue.qsize())
print('result_queue 结束大小 %d' % result_queue.qsize())
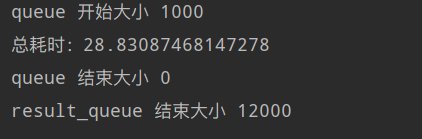
多进程运行结果:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)