看论文总是会看出来一堆堆奇奇怪怪的名词。
从远程监督、有监督、半监督、无监督开始,最近又看到了一个自监督。
首先先对上面的概念进行简述:
半监督(semi-supervised learning):利用好大量无标注数据和少量有标注数据进行监督学习;
远程监督(distant-supervised learning):利用知识库对未标注数据进行标注;
无监督:不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类相关的任务。
自监督:利用辅助任务从无监督的数据中挖掘大量自身的信息。(辅助任务就是基于数据特征构造一个任务进行训练)
介绍
自监督学习的核心在于如何自动为数据产生标签。
自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。
所以对于自监督学习来说,存在三个挑战:
对于大量的无标签数据,如何进行表征学习?
从数据的本身出发,如何设计有效的辅助任务pretext?
对于自监督学习到的表征,如何来评测他的有效性?
对于第三点,评测自监督学习的能力,主要是通过Pretrain-Fintune的模式。我们首先回顾下监督学习中的pretrain-finetune流程:
我们首先从大量的有标签数据上进行训练,得到预训练的模型,然后对于新的下游任务(Downstream task),我们将学习到的参数进行迁移,在新的标签任务上进行微调,从而得到一个能适应新任务的网络。
而自监督的Pretrain-Finetune流程,首先从大量的无标签数据中通过pretext来训练网络。而自监督的pretrain-finetune流程:
首先从大量的无标签数据中通过pretext来训练网络,得到预训练模型,然后对于新的下游任务,和监督学习一样,迁移学习到的参数候微调即可。所以自监督学习的能力主要由下游任务的性能来体现。
自监督的主要方法
主要可以分为三类:
基于上下文(Context based)
基于时序(Temporal Based)
基于对比(Contrastive Based)
1、基于上下文(Context Based)
基于数据本身的上下文信息,我们其实可以构造很多任务,比如在 NLP 领域中最重要的算法 Word2vec 。Word2vec 主要是利用语句的顺序,例如 CBOW 通过前后的词来预测中间的词,而 Skip-Gram 通过中间的词来预测前后的词。
BERT中的MASK LM训练方式。
只要是解耦的特征,都可以互相监督的学习表征。
Split-Brain Autoencoders(Zhang, R., Isola, P., & Efros, A. A. Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction. In CVPR 2017)就是这样方式,
2、基于时序(Temporal Based)
样本间其实是具有很多约束关系的,以视频(体现时序的数据类型)来介绍利用时序约束来进行自监督学习的方法。
视频
(1)基于帧的相似性,对于视频中每一帧,其实存在着特征相似的概念,简单来说,可以认视频中的相邻特征是相似的,而相隔较远的视频帧是不相似的,通过构建这种相似和不相似的样本来进行自监督约束。
(2)基于无监督追踪方法,首先在大量的无标签视频中进行无监督追踪,获取大量的物体追踪框。那么对于一个物体追踪框在不同帧的特征应该是相似的(positive),而对于不同物体的追踪框中的特征应该是不相似的(negative)。
(3)除了基于特征相似性外,视频的先后顺序也是一种自监督信息。
对话
(1)基于顺序的约束可以用于对话系统中,ACL2019(Wu, Jiawei et al. “Self-Supervised Dialogue Learning.” ACL (2019).)提出的自监督对话系统就是基于这种思想。这篇文章主要是想解决对话系统中生成的话术连贯性的问题,期待机器生成的回复和人类交谈一样是符合之前的说话的风格、习惯等。从大量的历史预料中挖掘出顺序的序列(positive)和乱序的序列(negative),通过模型来预测是否符合正确的顺序来进行训练。训练完成后就拥有了一个可以判断连贯性的模型,从而可以嵌入到对话系统中,最后利用对抗训练的方式生成更加连贯的话术。
(2)BERT的Next Sentence Prediction也可以看作是基于顺序的约束,通过构造大量的上下文样本,目的是让模型理解两个句子之间的联系。这一任务的训练语料可以从语料库中抽取句子对包括两个句子A和B来进行生成,其中50%的概率B是A的下一个句子,50%的概率B是语料中的一个随机句子。该任务预测B是否是A的下一句。
3、基于对比(Contrastive Based)
相关参考:
ankeshanand.com/blog/20
Velickovic, Petar et al. “Deep Graph Infomax.” ArXiv abs/1809.10341 (2018): n. pag.
第三类自监督学习的方法是基于对比约束的,它通过学习对两个事物的相似或不相似进行编码来构建表征,这类方法的性能目前来说是非常强的。
其实第二部分所介绍的基于时序的方法已经涉及到了这种基于对比的约束,通过构建正样本(positive)和负样本(negative),然后度量正负样本的距离来实现自监督学习。
核心思想:
样本和正负样本之间的距离远远大于样本和负样本之间的距离:

这里的x通常也称为[anchor]数据,为了优化anchor数据和其正负样本的关系,我们可以使用点积的方式构造距离函数,然后构造一个softmax分类器,以正确分类正样本和负样本。这应该鼓励相似性度量函数(点积)将较大的值分配给正例,将较小的值分配给负例。
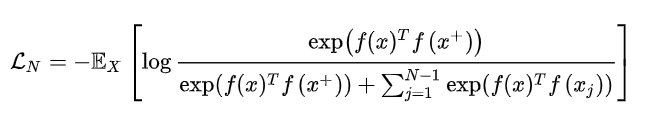
通常这个损失也被称为 InfoNCE ,后面的所有工作也基本是围绕这个损失进行的。
CPC同样是一个基于对比约束的自监督框架,主要是可以应用于能够以有序序列表示的任何形式的数据:文本、语音、视频、甚至图象(图象可以被视为像素或块的序列)。CPC 主要是利用自回归的想法,对相隔多个时间步长的数据点之间共享的信息进行编码来学习表示,这个表示 c_t 可以代表融合了过去的信息,而正样本就是这段序列 t 时刻后的输入,负样本是从其他序列中随机采样出的样本。CPC的主要思想就是基于过去的信息预测的未来数据,通过采样的方式进行训练。
以下部分为直接的copy,还没有消化。
对于具体的实现上,因为存在大量的样本,如何存取和高效的计算损失是急需解决的。研究人员提出了memory bank [27]的概念,也就是说我们把之前模型产生样本特征全部存起来,当前计算损失的时候直接拿来用就可以了,每次模型更新完后将当前的特征重新更新到 memory bank 中,以便下一次使用。这个工作的缺点就在于每次需要将所有样本的特征全部存起来。后续 kaiming 大神提出的 Moco[28], 主要的贡献是 Momentum Update、 shuffleBN 等技术点来优化这个过程。关于 Moco 知乎上已经有了很多的解释了,推荐大家阅读 [2],这里我们就不展开介绍了。
最近 hinton 组又放出了 SimCLR[29],这个工作主要是对于一个输入的样本,进行不同的数据增广方式,对于同一个样本的不同增广是正样本,对于不同样本的增广是负样本。整个过程比之前kaiming提出的动量对比(MoCo)更加的简单,同时省去了数据存储队列。这个工作的创新主要有两个:
-
在表征层和最后的损失层增加了一个非线性映射可以增加性能 (这个地方我比较好奇,希望能有大佬给出更直观的解释)。
-
数据增广对于自监督学习是有益的,不同数据增广方式的结合比单一增广更好。
同时作者公布了非常多的实验经验,比如自监督学习需要更大的 batch 和更长的训练时间。
自监督学习的“标注”通常来自于数据本身,其常规操作是通过各自的“auxiliary task”来提高学习表征(representation)的质量,从而提高下游任务的质量。
自监督的方法常用的情景或任务:为了解决数据集无标签或者标签较少质量低的问题。
自我监督方法可以看作是一种具有监督形式的特殊形式的非监督学习方法,这里的监督是由自我监督任务而不是预设先验知识诱发的。与完全不受监督的设置相比,自监督学习使用的数据集本身的信息来构造伪标签。在表示学习方面,自我监督学习具有取代完全监督学习的巨大潜力。人类学习的本质告诉我们,大型注释数据集可能不是必需的,我们可以自发地从未标记地数据集中学习。更为现实的设置是使用少量带注释的数据进行自学习。这称为Few-shot Learning。
所有的非监督学习方法,例如数据降维(PCA:在减少数据维度的同时最大化的保留原有数据的方差),数据拟合分类(GMM: 最大化高斯混合分布的似然), 本质上都是为了得到一个良好的数据表示并希望其能够生成(恢复)原始输入。这也正是目前很多的自监督学习方法赖以使用的监督信息。基本上所有的encoder-decoder模型都是以数据恢复为训练损失。
其他
自动编码器(autoencoder)
https://mp.weixin.qq.com/s/Ekh0CqHuXGxKsy7sFropoA

编码器将输入的样本映射到隐层向量,解码器将这个隐层向量映射回样本空间。我们期待网络的输入和输出可以保持一致,同时隐层向量的维度大大小于输入样本的维度,以此达到了降维的目的,利用学习到的隐层向量再进行聚类等任务时将更加简单高效。对于如何学习隐层向量的研究,可以称之为表征学习(Representation Learning)。对于自编码器,可能仅仅是做了维度的降低而已,我们希望学习的目的不仅仅是维度更低,还可以包含更多的语义特征,让模型懂的输入究竟是什么,从而帮助下游任务。而自监督学习最主要的目的就是学习到更丰富的语义表征。
参考:
https://zhuanlan.zhihu.com/p/125721565
https://mp.weixin.qq.com/s/Ekh0CqHuXGxKsy7sFropoA
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)