From: 别魔改网络了,Google研究员:模型精度不高,是因为你的Resize方法不够好! - 知乎 (zhihu.com)
paper: 2103.09950v2.pdf (arxiv.org)
code: KushajveerSingh/resize_network_cv: PyTorch implementation of the paper "Learning to Resize Images for Computer Vision Tasks" on Imagenette and Imagewoof datasets (github.com)
Learning to Resize in Computer Vision (keras.io)
尽管近年来卷积神经网络很大地促进了计算机视觉的发展,但一个重要方面很少被关注:图像大小对被训练的任务的准确性的影响 。通常,输入图像的大小被调整到一个相对较小的空间分辨率(例如,224×224),然后再进行训练和推理。这种调整大小的机制通常是固定的图像调整器(image resizer)(如:双行线插值)但是这些调整器是否限制了训练网络的任务性能呢? 作者通过实验证明了典型的线性调整器可以被可学习的调整器取代,从而大大提高性能 。虽然经典的调整器通常会具备更好的小图像感知质量(即对人类识别图片更加友好),本文提出的可学习调整器不一定会具备更好的视觉质量,但能够提高CV任务的性能。
在不同的任务中,可学习的图像调整器与baseline视觉模型进行联合训练。这种可学习的基于cnn的调整器创建了机器友好的视觉操作,因此在不同的视觉任务中表现出了更好的性能 。作者使用ImageNet数据集来进行分类任务,实验中使用四种不同的baseline模型来学习不同的调整器,相比于baseline模型,使用本文提出的可学习调整器能够获得更高的性能提升。
背景
目前的resize方法一般都是已经设计好的,不可学习的,典型的有NEAREST,BILINEAR,BICUBIC。
我们先来看看这些resize算法的不同效果:
原图:

NEAREST:
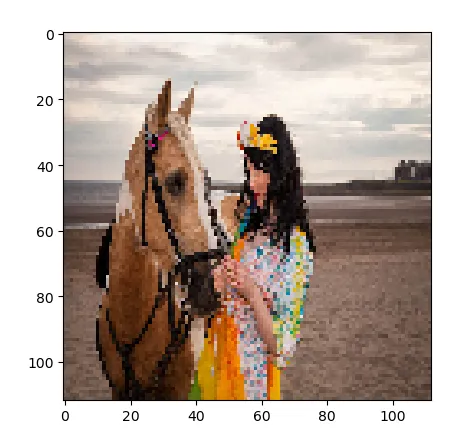
BILINEAR:
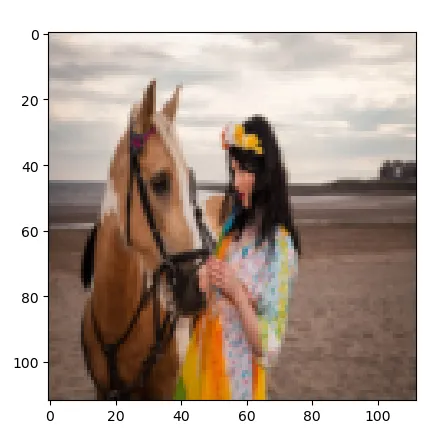
BICUBIC:
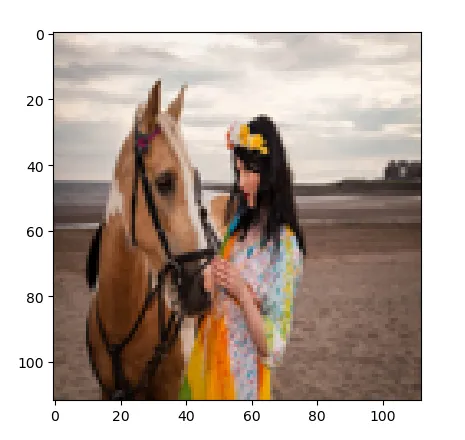
可以看出,对人来说,不同的resize方法差别还是蛮大的。那么对于模型来说应该采用什么样的resize方法呢?为此,作为提出了采用可学习的resizer model来对图片进行resize,以进一步提高CV任务的性能。
1. 论文和代码地址

Learning to Resize Images for Computer Vision Tasks
论文地址:https://arxiv.org/abs/2103.09950
代码地址:未开源
2. Motivation
深度神经网络和大规模图像数据集的出现使机器视觉识别取得了重大突破。这类数据集中的图像通常是从网络上获得的,因此已经经过了各种后处理步骤。除了收集数据时采用的一些处理方法,在CNN训练的时候,通常还需要额外的图像处理方法,比如resize。
图像下采样是分类模型中最常用的预处理模块。图像大小的调整主要有以下几个原因:
(1)通过梯度下降的mini-batch学习需要batch中的所有图像具有相同的空间分辨率 ;
(2)显存限制阻碍了在高分辨率下训练CNN模型;
(3)较大的图像尺寸会导致训练和推理的速度较慢。
给定固定的显存预算,需要在空间分辨率和Batch Size之间进行trade-off。而这个trade-off会很大程度上会影响模型的最终性能。
目前最基本的调整器的方法有最近邻、bilinear和bicubic(如Section 0中的可视化结果)。这些调整器速度快,可以灵活地集成到训练和测试框架中。但是,这些方法是在深度学习成为视觉识别任务的主流解决方案之前就发展起来的,因此没有对深度学习进行专门的优化。
近年来,通过图像处理方法在提高分类模型的准确性和保持感知质量方面取得了良好的效果。这类方法保持了分类模型的参数固定,并且只训练了增强模块。此外,也有一些方法采用了联合训练预处理模块和识别模型,这些算法建立了具有混合损失的训练框架,允许模型同时学习更好的增强和识别。然而,在实践中,调整图像大小等识别预处理操作不应该优化为更好的感知质量,因为最终目标是让识别网络产生准确的结果,而不是产生对人觉得“看起来好”的图像。
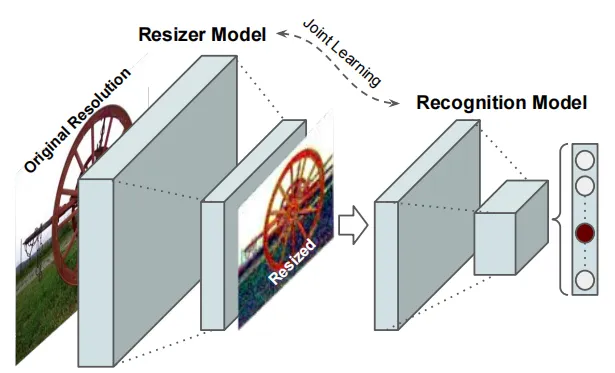
因此,本文提出了一种与分类模型联合训练的新型图像调整器(如上图所示)。
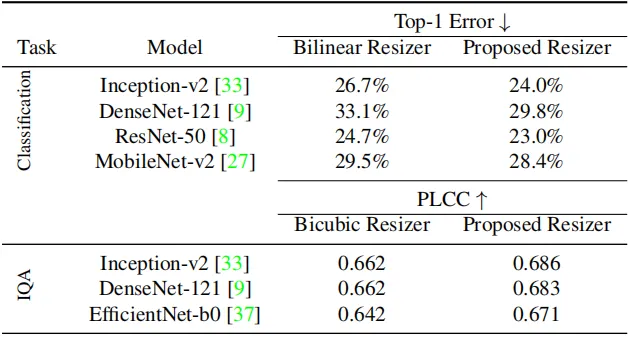
并且,这种设计能够提高分类模型的性能(如上表所示)。
3. 方法
本文的调整器模型是易于训练的,因此它可以插入到各种深度学习框架和任务中。此外,它还可以处理任何的缩放因子,包括不同比例的放大和缩小。在本文中,作者探索了分辨率与batch大小的trade-off,从而为特定CV任务寻找最佳的分辨率。在理想情况下,通过这种自适应调整大小获得的性能增益需要超过调整大小增加到的额外计算复杂度。另一方面,bilinear和bicubic等缩放方法本身是不可训练的,因此不适合完成这样的目标。为此,作者设计了一个满足这些标准的模型。
3.1. Resizer Model
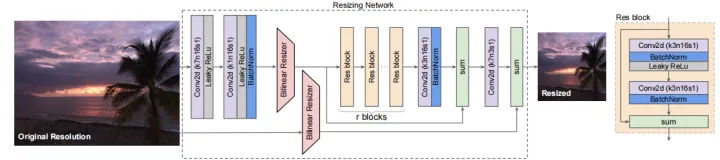
本文提出的调整器架构如上图所示。该模型最重要的特性是(1)bilinear resizer,(2)skip connection。bilinear resizer使得能够向模型中合并以原始分辨率计算的特征。skip connection使得模型能够更容易学习。上图中的bilinear resizer模块使得模型能够呈现一个bottleneck或者inverse bottleneck的结构。与典型的编码-解码器架构不同,Resizer Model能够将图像调整为任何目标大小和长宽比。此外,学习到的Resizer Model的性能几乎不依赖于bilinear resizer的选择。
在Resizer Model中有r个相同的残差块,在实验中,作者设置了r=1或2。所有的中间卷积层都有n(n=16)个大小为3×3的核。第一层和最后一层的卷积核大小为7×7。

本文提出的Resizer Model相对来说比较轻量级,与原始的模型相比,没有添加大量的可训练参数。Resizer Model各种配置的可训练参数数量如上表所示。ResNte-50有约2300万个参数,与原始模型的参数相比,Resizer Model引入的参数可以说是非常小的。
3.2. Learning Losses
Resizer Model是用Baseline Model的损失函数进行联合训练的。由于Resizer Model的目标是学习baseline视觉任务的最优调整器,因此作者没有对Resizer Mode用任何其他损失或正则化约束。
3.2.1 Image Classification
分类模型采用交叉熵损失进行训练。ImageNet由1000个类组成,因此,模型的输出代表1000个预测类概率。作者在训练过程中采用了label-smoothing方法,损失函数如下所示:
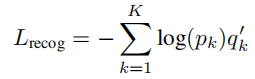
其中p和q′是预测和平滑的标签,K表示类的总数。
3.2.2 Image Quality Assessment (IQA)
质量评估模型通过回归损失进行训练。AVA数据集中的每张图像都有一个人工评级的直方图,得分从1到10不等。在本文中,作者使用Earth Mover's Distance (EMD)作为训练损失。具体地说,baseline模型有一个Softmax层,输出10个logits。EMD损失可以表示为:
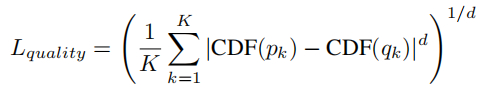
其中CDF(.)代表累积分布函数,d=2,K=10。
4.实验

上表展示了本文实验的细节的总结。首先,在每个数据集上,作者用 bilinear和bicubic进行图片缩放来训练baseline模型,而不用提出的Resizer Model。这些模型被用作benchmark来对比Resizer Model的性能。训练的任务包括分类和IQA。然后作者又用了可学习的Resizer Model和Baseline模型进行联合训练来对比实验结果。
4.1. Classification
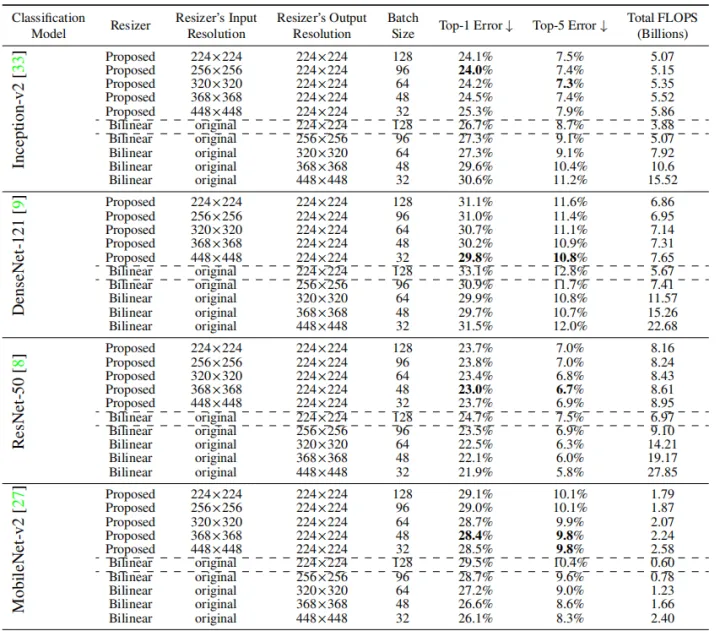
作者采用了四个模型来验证Resizer Model的有效性。可以看到,使用Resizer Model训练的网络显示出比默认baseline更好的性能。与默认baseline相比,DenseNet-121和MobileNet-v2分别显示出最大和最小的性能增益。
此外,无论是否使用Resizer Model,增加输入分辨率都有利于DenseNet-121、ResNet-50和MobileNet-v2的性能提升。


上表显示了不同resize方法和不同模型下resizer model的输出结果。这些结果的共同点是具备高频细节,这可能会使分类模型更有效。
4.2. Quality Assessment
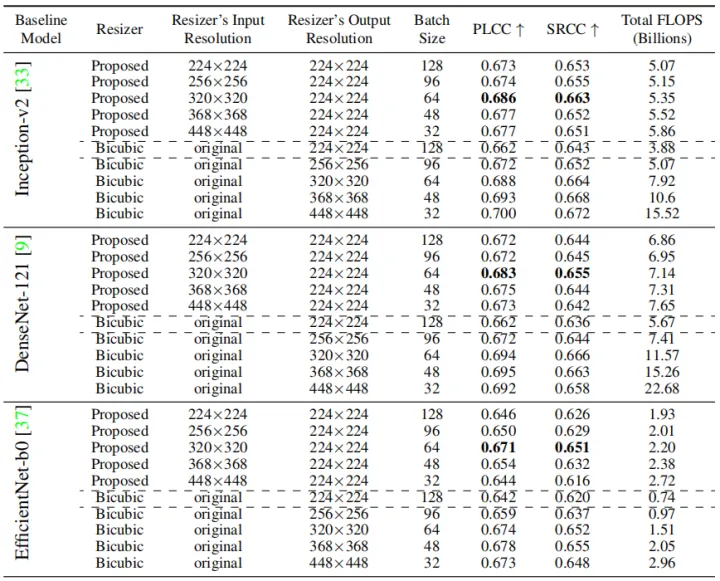
在AVA数据集上,作者训练了三个baseline模型,并使用PLCC和SRCC评价指标来评价模型的性能。可以看出,与Baseline模型相比,本文提出的resizer model能够进一步模型的性能。

上图展示了resizer model的输出结果。可以看出,Inception和DenseNet模型的图像有更多的细节信息;EfficientNet输出模型有很强颜色偏移。
4.3. Generalization


此外,作者还验证了resizer model的迁移泛化能力,作者尝试了在不同baseline模型训练的resizer model进行互换,结果如上表所示。这些结果表明,为一个模型训练的resizer model通过很少的fine-tune就可以作为另一个模型的resizer model。
4.4. Ablation
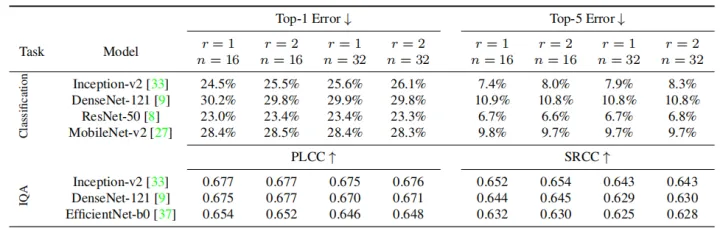
作者在不同的r和n上进行了消融实验,结果如上表所示。作者在实验中采用了r=1和n=16。
5. 总结
在本文中,作者提出了一个可学习的调整器模型(resizer model)来提高模型的性能。作者关注于调整图像大小,并没有对重新调整的图像施加像素或感知的损失函数,因此结果只针对机器视觉任务进行了优化。实验表明,用resizer model代替传统的图像调整器可以提高视觉模型的性能。
个人认为,本文的实现方法其实非常简单,就是用了一个模型去学习图片应该怎么resize。但是思路还是比较新奇的,因为以前的方法大多都是关注在怎么更改模型的结构来提升模型的性能,但是这篇论文自己开了一个赛道,学习一个更好的调整器模型,用更适用于深度学习模型的方式来进行resize。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)