目录
一、基础概念
二、先使用再了解
三、底层结构
1.HashMap结构(JDK1.8以前)
2.HashMap结构(JDK1.8以后)
四、HashMap实现
1.成员变量
2.put实现
3.get实现
4.remove实现
5.resize与rehash实现
五、源码
1.类属性与继承关系
2.构造函数
3.hash算法
4.HashMap 的容量
一、基础概念
首先说明几个概念:
Colllection接口为基本的接口,存储对象有List、Set、Quene。List为有序的允许重复的Collection,Set为无序不允许重复的Collection。
Map,图,是一种存储键值对映射的容器,在Map中键可以是任意类型的对象,但是键 不允许重复的。
每一个键对应有一个值如 name(Tom)-age(13)
HashMap基于哈希表的Map接口的非同步实现,继承自AbstractMap,AbstractMap 是部分实现Map接口的抽象类。
jdk1.8之前 数组+链表
jdk1.8 数组+链表+红黑树
terator迭代器是每个集合都有的一个对象。
Java中的Iterator功能比较简单,并且只能单向移动:
(1) 使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
二、先使用再了解
定义一个Map对象,测试如何初始化及下列各种方法的使用:
HashMap方法
| 方法 | 描述 |
|---|
| clear() | 删除 hashMap 中的所有键/值对 |
| clone() | 复制一份 hashMap |
| isEmpty() | 判断 hashMap 是否为空 |
| size() | 计算 hashMap 中键/值对的数量 |
| put() | 将键/值对添加到 hashMap 中 |
| putAll() | 将所有键/值对添加到 hashMap 中 |
| putIfAbsent() | 如果 hashMap 中不存在指定的键,则将指定的键/值对插入到 hashMap 中。 |
| remove() | 删除 hashMap 中指定键 key 的映射关系 |
| containsKey() | 检查 hashMap 中是否存在指定的 key 对应的映射关系。 |
| containsValue() | 检查 hashMap 中是否存在指定的 value 对应的映射关系。 |
| replace() | 替换 hashMap 中是指定的 key 对应的 value。 |
| replaceAll() | 将 hashMap 中的所有映射关系替换成给定的函数所执行的结果。 |
| get() | 获取指定 key 对应对 value |
| getOrDefault() | 获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值 |
| forEach() | 对 hashMap 中的每个映射执行指定的操作。 |
| entrySet() | 返回 hashMap 中所有映射项的集合集合视图。 |
| keySet() | 返回 hashMap 中所有 key 组成的集合视图。 |
| values() | 返回 hashMap 中存在的所有 value 值。 |
| merge() | 添加键值对到 hashMap 中 |
| compute() | 对 hashMap 中指定 key 的值进行重新计算 |
| computeIfAbsent() | 对 hashMap 中指定 key 的值进行重新计算,如果不存在这个 key,则添加到 hasMap 中 |
| computeIfPresent() | 对 hashMap 中指定 key 的值进行重新计算,前提是该 key 存在于 hashMap 中。 |
package sefl.HashMap;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class test {
public static void main(String[] args) {
//1.声明HashMap对象
Map<String, Integer> map = new HashMap<>();
//2.添加数据 put
map.put("zhangsan", 90);
map.put("wangwu", 79);
map.put("lisi", 80);
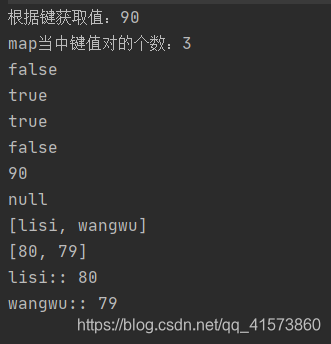
//3.根据键获取值 get
System.out.println("根据键获取值:"+map.get("zhangsan"));
//4.获取Map中键值对的个数
System.out.println("map当中键值对的个数:"+map.size());
//5.判断Map集合是否包含键为key的键值对
System.out.println(map.containsKey("tom"));
System.out.println(map.containsKey("zhangsan"));
//6.判断Map集合是否包含值为value的键值对
System.out.println(map.containsValue(90));
System.out.println(map.containsValue(100));
//7、根据键删除Map中的健值对 remove
System.out.println(map.remove("zhangsan"));
System.out.println(map.remove("tom"));
//8、 返回Map集合中所有key组成的Set集合
System.out.println(map.keySet());
//9、返回Map集合中所有value组成的以Collection数据类型格式数据
System.out.println(map.values());
//10、获取HashMap中的所有键值对
Iterator<Map.Entry<String, Integer>> iterator = map.entrySet().iterator();
while(iterator.hasNext()){
Map.Entry<String, Integer> next = iterator.next();
System.out.println(next.getKey()+":: "+next.getValue());
}
//11、清空并输出打印
map.clear();
while(iterator.hasNext()){
Map.Entry<String, Integer> next = iterator.next();
System.out.println(next.getKey()+":: "+next.getValue());
}
}
}
测试结果:
三、底层结构
1.HashMap结构(JDK1.8以前)
如下图所示,在1.8版本之前,哈希表的结构是由数组+链表实现的,通常使用链地址法去解决哈希冲突,元素较少时,时间复杂度为O(1),但元素增多后,元素存于链表中,在链表上进行操作,时间复杂度为O(N)。

2.HashMap结构(JDK1.8以后)
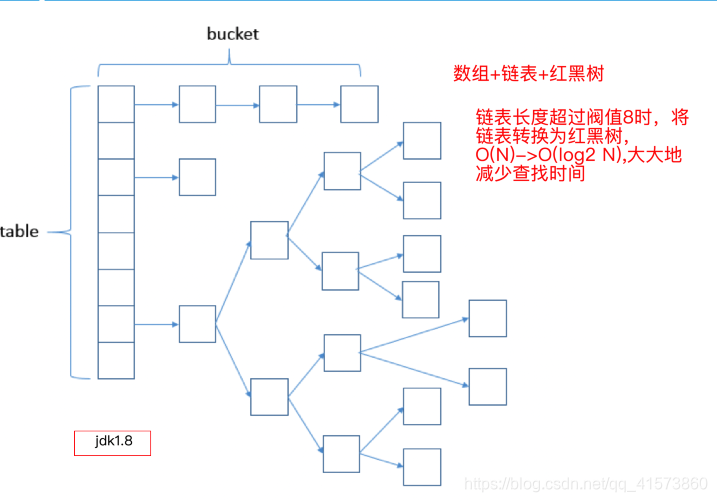
在1.8版本以后,结构变为了数组+链表+红黑树。
红黑树的概念:
红黑树是一种自平衡二叉查找树 它在O(log2 N)的时间内做查找、添加、删除 红黑树和AVL树是二叉查找树的变体,红黑树的性能要好于AVL树
红黑树特点:
1) 每个节点是红色或黑色
2)根节点一定是黑色
3)每个叶子节点是黑色
4)如果一个节点是红色,则叶子节点必须是黑色
5)每个节点到叶子节点所经过的黑节点的个数必须是一样
四、HashMap实现
仿照源码,实现HashMap的结构以及一些重要函数如put,get,remove等。
1.成员变量
主要有三个参数,key,value,与散列值hash。
private int size; //表示map中有多少个键值对
private Node<K, V>[] table;
class Node<K, V> {
private K key;
private V value;
private Node<K, V> next;
private int hash;
public Node(int hash, K key, V value) {
this.hash = hash;
this.key = key;
this.value = value;
}
}
2.put实现
put方法主要用于将键值对放入哈希表中,其实现流程为:
- 1)key-> hash(key) 散列码 -> hash & table.length-1 index
- 2)table[index] == null 是否存在节点
- 3)不存在 直接将key-value键值对封装成为一个Node 直接放到index位置
- 4)存在 key不允许重复
- 5)存在 key重复 考虑新值去覆盖旧值
- 6)存在 key不重复 尾插法 将key-value键值对封装成为一个Node 插入新节点
public void put(K key, V value){
//key->Hash值->index
int hash = hash(key);//散列码
//table.length-1 & h->index确定插入位置
int index = table.length-1 & hash;
//当前index位置不存在节点
Node<K, V> firstNode = table[index];
if(firstNode == null){
//table[index]位置不存在节点 直接插入
table[index] = new Node(hash, key, value);
size++;
}
//key不允许有重复的
//查找当前链表中key是否已经存在
//当前位置存在节点 判断key是否重复
if(firstNode.key.equals(key)){
firstNode.value = value;
}else{
//遍历当前链表
Node<K, V> tmp = firstNode;
while(tmp.next != null && !tmp.key.equals(key)){
tmp = tmp.next;
}
if(tmp.next == null){
//表示最后一个节点之前的所有节点都不包含key
if(tmp.key.equals(key)){
//最后一个节点的key与当前所要插入的key是否相等,考虑新值覆盖旧值
tmp.value = value;
}else{
//如果不存在,new Node,尾插法插入链表当中
tmp.next = new Node(hash, key, value);
size++;
}
}else{
//如果存在,考虑新值覆盖旧值
tmp.value = value;
}
}
}
3.get实现
get方法返回指定键所映射的值,没有该key对应的值则返回null,其实现流程如下:
1)通过key获取到位置index
2)在index位置的所有节点中找与当前key相等的key,不存在返回null,存在返回对应value
public V get(K key){
//获取key所对应的value
//key->index
int hash = hash(key);
int index = table.length-1 & hash;
//在index位置的所有节点中找与当前key相等的key
Node<K,V> firstNode = table[index];
//当前位置点是否存在节点 不存在
if(firstNode == null){
return null;
}
//判断第一个节点
if(firstNode.key.equals(key)){
return firstNode.value;
}else{
//遍历当前位置点的链表进行判断
Node<K,V> tmp = firstNode.next;
while(tmp != null && !tmp.key.equals(key)){
tmp = tmp.next;
}
if(tmp == null){
return null;
}else{
return tmp.value;
}
}
}
4.remove实现
remove方法用于删除Map集合中键为key的数据并返回其所对应value值,实现流程:
1)通过key获取到位置index
2)index位置没有节点返回null
3)找到与key对应的key所在位置,将链表向前覆盖进行删除,同时返回key对应的value
public V remove(K key){
//key->index
//当前位置中寻找当前key所对应的节点
int hash = hash(key);
int index = table.length-1 & hash;
Node<K,V> firstNode = table[index];
if(firstNode == null){
//表示table桶中的该位置不存在节点
return null;
}
//删除的是第一个节点
if(firstNode.key.equals(key)){
table[index] = firstNode.next;
size--;
return firstNode.value;
}
//相当于在链表中删除中间某一个节点
while(firstNode.next != null){
if(firstNode.next.key.equals(key)){
//firstNode.next是所要删除的节点
//firstNode是它的前一个节点
//firstNode.next.next是它的后一个节点
firstNode.next = firstNode.next.next;
size--;
return firstNode.next.value;
}else{
firstNode = firstNode.next;
}
}
return null;
}
5.resize与rehash实现
resize用于对哈希表进行2倍扩容。
public void resize(){
//HashMap的扩容
//table进行扩容 2倍的方式 扩容数组
Node<K, V>[] newTable = new Node[table.length*2];
//index -> table.length-1 & hash
//重哈希
for(int i=0; i<table.length; i++){
rehash(i, newTable);
}
this.table = newTable;
}
在容量进行扩充后,需要对哈希表进行重哈希操作。

如上图所示,一开始数组长度为4,,0,4,8分别于table.length取余后得到index均在0号位置,1,2,6,3,也同样如此,在进行二倍扩容后,以4为例,扩容器前在0号位置,扩容后到了4号位置,因为需要对哈希表中的元素进行重哈希操作,并且发现扩容后元素位置有个特点,要么它还在原位置,要么在原位置+扩容后的长度的位置上。
实现如下:
将每一个元素都进行重新计算,rehash需要两个参数,一个index位置,一个新数组newTable。先获取当前结点在原数组中的index,若为空则直接return。若不为空,将原位置看做低位,原位置+扩容长度的位置看成高位, 根据新数组的长度重新计算散列值,若新位置与旧位置相等,说明在低位,如果lowHead为空,就是第一次插入,将当前结点既当头又当尾,否则就尾插法插到tail后面。while结束后,要将tail的next置null,然后将head放在高低位对应的位置,即原位或原位+扩容长度位置。
public void rehash(int index, Node<K,V>[] newTable){
//相当于对原先哈希表中每一个有效节点 进行 重哈希的过程
Node<K,V> currentNode = table[index];
if(currentNode == null){
return;
}
Node<K,V> lowHead = null; //低位的头
Node<K,V> lowTail = null;//低位的尾
Node<K,V> highHead = null;//高位的头
Node<K,V> highTail = null;//高位的尾
while(currentNode != null){
//遍历index位置的所有节点
int newIndex = hash(currentNode.key) & (newTable.length-1);
if(newIndex == index){
//当前节点链到lowTail之后
if(lowHead == null){
lowHead = currentNode;
lowTail = currentNode;
}else{
lowTail.next = currentNode;
lowTail = lowTail.next;
}
}else{
//当前节点链到highTail之后
if(highHead == null){
highHead = currentNode;
highTail = currentNode;
}else{
highTail.next = currentNode;
highTail = highTail.next;
}
}
currentNode = currentNode.next;
}
//要么在原位置 (低位位置)
if(lowHead != null && lowTail != null){
lowTail.next = null;
newTable[index] = lowHead;
}
//要么跑到原位置 + 扩容前长度 (高位位置)
if(highHead != null && highTail != null){
highTail.next = null;
newTable[index + table.length] = highHead;
}
}
}
五、源码
1.类属性与继承关系
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// 序列号
private static final long serialVersionUID = 362498820763181265L;
// 默认的初始容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的填充因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当桶(bucket)上的结点数大于这个值时会转成红黑树;+对应的table的最小大小为64,即MIN_TREEIFY_CAPACITY ;这两个条件都满足,会链表会转红黑树
static final int TREEIFY_THRESHOLD = 8;
// 当桶(bucket)上的结点数小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
// 桶中结构转化为红黑树对应的table的最小大小
static final int MIN_TREEIFY_CAPACITY = 64;
// 存储元素的数组,总是2的幂次倍
transient Node<k,v>[] table;
// 存放具体元素的集
transient Set<map.entry<k,v>> entrySet;
// 存放元素的个数,注意这个不等于数组的长度。
transient int size;
// 每次扩容和更改map结构的计数器
transient int modCount;
// 临界值 当实际大小(容量*填充因子)超过临界值时,会进行扩容
int threshold;
// 填充因子
final float loadFactor;
}
HashMap继承自父类(AbstractMap),实现了Map、Cloneable、Serializable接口。其中,Map接口定义了一组通用的操作;Cloneable接口则表示可以进行拷贝,在HashMap中,实现的是浅层次拷贝,即对拷贝对象的改变会影响被拷贝的对象;Serializable接口表示HashMap实现了序列化,即可以将HashMap对象保存至本地,之后可以恢复状态。
其中链表转红黑树,并不是达到8个Node节点的阈值就进行转换,而是要判断一下整个数据结构中的Node数量是否大于64,大于才会转,小于就会用扩容数组的方式代替红黑树的转换。在源码的putVal中,当 binCount >= TREEIFY_THRESHOLD - 1时,会调用 treeifyBin(tab, hash)方法,就是链表转红黑树方法,当 tab.length)< MIN_TREEIFY_CAPACITY ,会扩容数组大小。
2.构造函数
public HashMap(int initialCapacity, float loadFactor) {
// 初始容量不能小于0,否则报错
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 初始容量不能大于最大值,否则为最大值
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 填充因子不能小于或等于0,不能为非数字
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// 初始化填充因子
this.loadFactor = loadFactor;
// 初始化threshold大小
this.threshold = tableSizeFor(initialCapacity);
}
其中tableSizeFor(initialCapacity)返回大于initialCapacity的最小的二次幂数值,>>> 操作符表示无符号右移,高位取0。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
3.hash算法
在jdk1.8中:
首先获取对象的hashCode()值,然后将hashCode值右移16位,然后将右移后的值与原来的hashCode做异或运算,返回结果。(其中h>>>16,在JDK1.8中,优化了高位运算的算法,使用了零扩展,无论正数还是负数,都在高位插入0)。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
在putVal源码中,通过(n-1)&hash获取该对象的键在hashmap中的位置。(其中hash的值就是(1)中获得的值)其中n表示的是hash桶数组的长度,并且该长度为2的n次方,这样(n-1)&hash就等价于hash%n。因为&运算的效率高于%运算。其中 n:hash槽数组大小;i:Node在数组中的索引值。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
...
if ((p = tab[i = (n - 1) & hash]) == null)//获取位置
tab[i] = newNode(hash, key, value, null);
...
}
4.HashMap 的容量
源码中HashMap的容量为2的幂次方,为什么要这样设置呢?
例如:
不采用2的幂次方,假设数组长度是10
1010 & 101010100101001001000 结果:1000 = 8
1010 & 101000101101001001001 结果:1000 = 8
1010 & 101010101101101001010 结果: 1010 = 10
1010 & 101100100111001101100 结果: 1000 = 8
这样做的结果会使不同的key值进入到相同的插槽中,形成链表,性能急剧下降。因此要保将& 中的二进制位全置为 1,也就是2的幂次方,才能最大限度的利用 hash 值,并更好的散列。如果是 1010,有的散列结果是永远都不会出现的,比如 0111,0101,1111,1110…,只要 & 之前的数有 0, 对应的 1 肯定就不会出现(因为只有都是1才会为1),大大限制了散列的范围。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)