转载于老狼:
https://zhuanlan.zhihu.com/p/26172972
https://zhuanlan.zhihu.com/p/26244141
PCI总线和设备树是X86硬件体系内很重要的组成部分,几乎所有的外围硬件都以这样或那样的形式连接到PCI设备树上。虽然Intel为了方便各种IP的接入而提出IOSF总线,但是其主体接口(primary interface)还依然是PCIe形式。我们下面分成两部分介绍PCI和他的继承者PCIe(PCI express):第一部分是历史沿革和硬件架构;第二部分是软件界面和UEFI中的PCI/PCe。
自PC在1981年被IBM发明以来,主板上都有扩展槽用于扩充计算机功能。现在最常见的扩展槽是PCIe插槽,实际上在你看不见的计算机主板芯片内部,各种硬件控制模块大部分也是以PCIe设备的形式挂载到了一颗或者几颗PCI/PCIe设备树上。固件和操作系统正是通过枚举设备树们才能发现绝大多数即插即用(PNP)设备的。那究竟什么是PCI呢?
PCI/PCIe的历史
在我们看PCIe是什么之前,我们应该要了解一下PCIe的祖先们,这样我们才能对PCIe的一些设计有了更深刻的理解,并感叹计算机技术的飞速发展和工程师们的不懈努力。
1. ISA (Industry Standard Architecture)
2. MCA (Micro Channel Architecture)
3. EISA (Extended Industry Standard Architecture)
4. VLB (VESA Local Bus)
5. PCI (Peripheral Component Interconnect)
6. PCI-X (Peripheral Component Interconnect eXtended)
7. AGP (Accelerated Graphics Port)
8. PCI Express (Peripheral Component Interconnect Express)
科技的每一步前进都是为了解决前一代中出现的问题,这里的问题就是速度。作为扩展接口,它主要用于外围设备的连接和扩展,而外围设备吞吐速度的提高,往往会倒推接口速度的提升。第一代ISA插槽出现在第一代IBM PC XT机型上(1981),作为现代PC的盘古之作,8位的ISA提供了4.77MB/s的带宽(或传输率)。到了1984年,IBM就在PC AT上将带宽提高了几乎一倍,16位ISA第二代提供了8MB/s的传输率。但其对传输像图像这种数据来说还是杯水车薪。
IBM自作聪明在PS/2产品线上引入了MCA总线,迫使其他几家PC兼容机厂商联合起来捣鼓出来EISA。因为两者都期待兼容ISA,导致速度没有多大提升。真正的高速总线始于VLB,它绑定自己的频率到了当时486 CPU内部总线频率:33MHz。而到了奔腾时代,内部总线提高到了66MHz,给VLB带来了严重的兼容问题,造成致命一击。
Intel在1992年提出PCI(Peripheral Component Interconnect)总线协议,并召集其它的小伙伴组成了名为 PCI-SIG (PCI Special Interest Group)(PCI 特殊兴趣组J)的企业联盟。从那以后这个组织就负责PCI和其继承者们(PCI-X和PCIe的标准制定和推广。
不得不点赞下这种开放的行为,相对IBM当时的封闭,合作共赢的心态使得PCI标准得以广泛推广和使用。有似天雷勾动地火,统一的标准撩拨起了外围设备制造商的创新,从那以后各种各样的PCI设备应运而生,丰富了PC的整个生态环境。
PCI总线标准初试啼声就提供了133MB/s的带宽(33MHz时钟,每时钟传送32bit)。这对当时一般的台式机已经是超高速了,但对于服务器或者视频来说还是不够。于是AGP被发明出来专门连接北桥与显卡,而为服务器则提出PCI-X来连接高速设备。
2004年,Intel再一次带领小伙伴革了PCI的命。PCI express(PCIe,注意官方写法是这样,而不是PCIE或者PCI-E)诞生了,其后又经历了两代,现在是第三代(gen3,3.0),gen4有望在2017年公布,而gen5已经开始起草中。
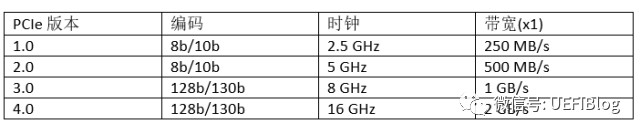
下面这个大表列出所有的速度比较。其中一些x8,x16的概念后面细节部分有介绍。
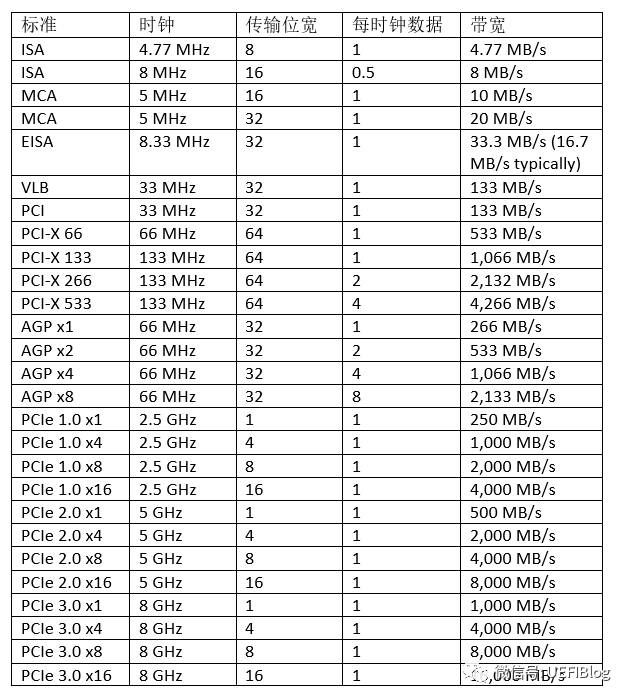
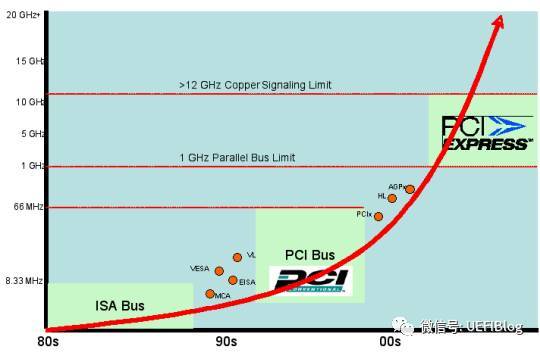
从下面的主频变化图中,大家可能注意到更新速度越来越快。
PCI和PCIe架构
1。PCI架构
一个典型的桌面系统PCI架构如下图:
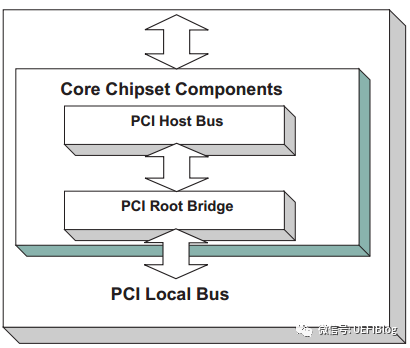
如图,桌面系统一般只有一个Host Bridge用于隔离处理器系统的存储器域与PCI总线域,并完成处理器与PCI设备间的数据交换。每个Host Bridge单独管理独立的总线空间,包括PCI Bus, PCI I/O, PCI Memory, and PCI
Prefetchable Memory Space。桌面系统也一般只有一个Root Bridge,每个Root Bridge管理一个Local Bus空间,它下面挂载了一颗PCI总线树,在同一颗PCI总线树上的所有PCI设备属于同一个PCI总线域。一颗典型的PCI总线树如图:
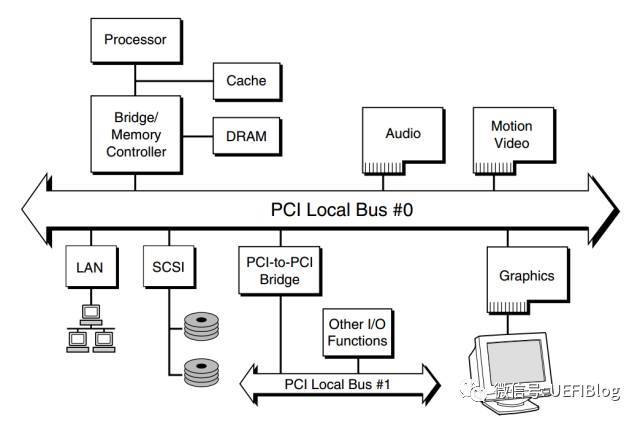
从图中我们可以看出 PCI 总线主要被分成三部分:
1. PCI 设备。符合 PCI 总线标准的设备就被称为 PCI 设备,PCI 总线架构中可以包含多个 PCI 设备。图中的 Audio、LAN 都是一个 PCI 设备。PCI 设备同时也分为主设备和目标设备两种,主设备是一次访问操作的发起者,而目标设备则是被访问者。
2. PCI 总线。PCI 总线在系统中可以有多条,类似于树状结构进行扩展,每条 PCI 总线都可以连接多个 PCI 设备/桥。上图中有两条 PCI 总线。
3. PCI 桥。当一条 PCI 总线的承载量不够时,可以用新的 PCI 总线进行扩展,而 PCI 桥则是连接 PCI 总线之间的纽带。
服务器的情况要复杂一点,举个例子,如Intel志强第三代四路服务器,共四颗CPU,每个CPU都被划分了共享但区隔的Bus, PCI I/O, PCI Memory范围,其构成可以表示成如下图:
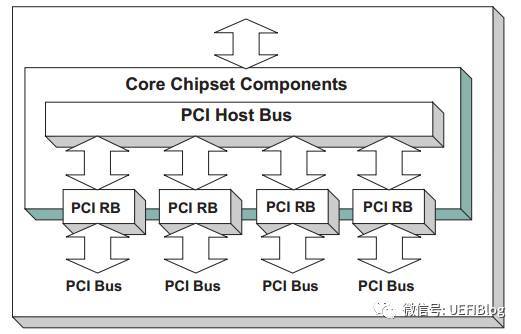
可以看出,只有一个Host Bridge,但有四个Root Bridge,管理了四颗单独的PCI树,树之间共享Bus等等PCI空间。
在某些时候,当服务器连接入大量的PCI bridge或者PCIe设备后,Bus数目很快就入不敷出了,这时就需要引入Segment的概念,扩展PCI Bus的数目。如下例:
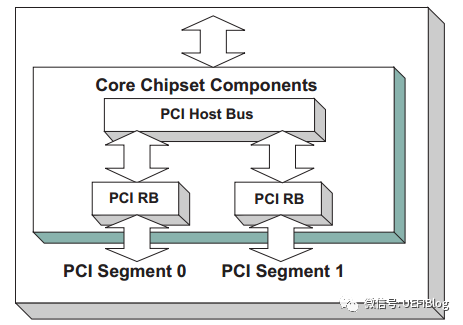
如图,我们就有了两个Segment,每个Segment有自己的bus空间,这样我们就有了512个Bus数可以分配,但其他PCI空间因为只有一个Host Bridge所以是共享的。会不会有更复杂的情况呢? 在某些大型服务器上,会有多个Host bridge的情况出现,这里我们就不展开了。
PCI标准有什么特点吗?
1. 它是个并行总线。在一个时钟周期内32个bit(后扩展到64)同时被传输。引脚定义如下:
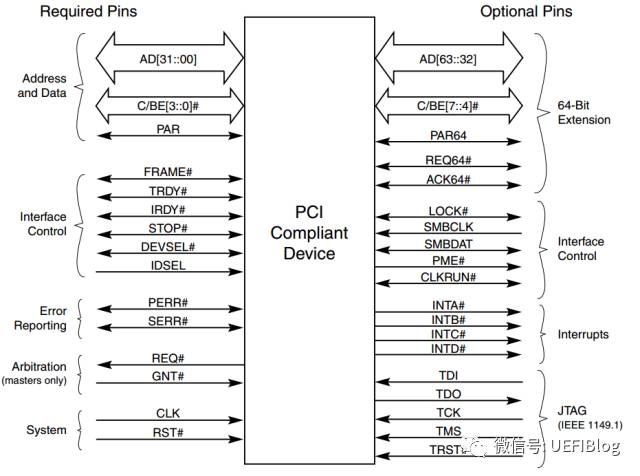
地址和数据在一个时钟周期内按照协议,分别一次被传输。
**2. PCI空间与处理器空间隔离。**PCI设备具有独立的地址空间,即PCI总线地址空间,该空间与存储器地址空间通过Host bridge隔离。处理器需要通过Host bridge才能访问PCI设备,而PCI设备需要通过Host bridge才能主存储器。在Host bridge中含有许多缓冲,这些缓冲使得处理器总线与PCI总线工作在各自的时钟频率中,彼此互不干扰。Host bridge的存在也使得PCI设备和处理器可以方便地共享主存储器资源。处理器访问PCI设备时,必须通过Host bridge进行地址转换;而PCI设备访问主存储器时,也需要通过Host bridge进行地址转换。
深入理解PCI空间与处理器空间的不同是理解和使用PCI的基础。
**3.扩展性强。**PCI总线具有很强的扩展性。在PCI总线中,Root Bridge可以直接连出一条PCI总线,这条总线也是该Root bridge所管理的第一条PCI总线,该总线还可以通过PCI桥扩展出一系列PCI总线,并以Root bridge为根节点,形成1颗PCI总线树。在同一条PCI总线上的设备间可以直接通信,并不会影响其他PCI总线上设备间的数据通信。隶属于同一颗PCI总线树上的PCI设备,也可以直接通信,但是需要通过PCI桥进行数据转发。
2。PCIe架构
PCI后期越来越不能适应高速发展的数据传输需求,PCI-X和AGP走了两条略有不同的路径,PCI-x不断提高时钟频率,而AGP通过在一个时钟周期内传输多次数据来提速。随着频率的提高,PCI并行传输遇到了干扰的问题:高速传输的时候,并行的连线直接干扰异常严重,而且随着频率的提高,干扰(EMI)越来越不可跨越。
乱入一个话题,经常有朋友问我为什么现在越来越多的通讯协议改成串行了,SATA/SAS,PCIe,USB,QPI等等,经典理论不是并行快吗?一次传输多个bit不是效率更高吗?从PCI到PCIe的历程我们可以一窥原因。
PCIe和PCI最大的改变是由并行改为串行,通过使用差分信号传输(differential transmission),如图
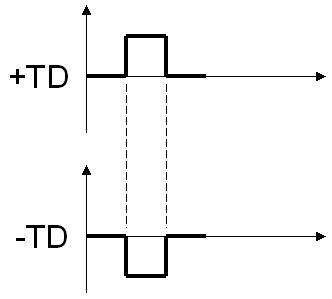
相同内容通过一正一反镜像传输,干扰可以很快被发现和纠正,从而可以将传输频率大幅提升。加上PCI原来基本是半双工的(地址/数据线太多,不得不复用线路),而串行可以全双工。综合下来,如果如果我们从频率提高下来得到的收益大于一次传输多个bit的收益,这个选择就是合理的。我们做个简单的计算:
PCI传输: 33MHz x 4B = 133MB/s
PCIe 1.0 x1: 2.5GHz x 1b = 250MB/s (知道为什么不是2500M / 8=312.5MB吗?)
速度快了一倍!我们还得到了另外的好处,例如布线简单,线路可以加长(甚至变成线缆连出机箱!),多个lane还可以整合成为更高带宽的线路等等。
PCIe还在很多方面和PCI有很大不同:
1. PCI是总线结构,而PCIe是点对点结构。一个典型的PCIe系统框图如下:
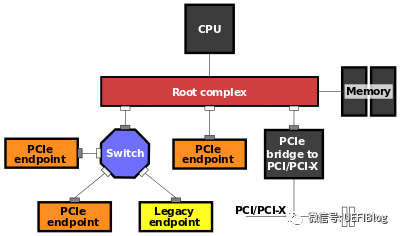
一个典型的结构是一个root port和一个endpoint直接组成一个点对点连接对,而Switch可以同时连接几个endpoint。一个root port和一个endpoint对就需要一个单独的PCI bus。而PCI是在同一个总线上的设备共享同一个bus number。过去主板上的PCI插槽都公用一个PCI bus,而现在的PCIe插槽却连在芯片组不同的root port上。
2. PCIe的连线是由不同的lane来连接的,这些lane可以合在一起提供更高的带宽。譬如两个1lane可以合成2lane的连接,写作x2。两个x2可以变成x4,最大直到x16,往往给带宽需求最大的显卡使用。
3. PCI配置空间从256B扩展为4k,同时提供了PCIe memory map访问方式,我们在软件部分会详细介绍。
4.PCIe提供了很多特殊功能,如Complete Timeout(CTO),MaxPayload等等几十个特性,而且还在随着PCIe版本的进化不断增加中,对电源管理也提出了单独的State(L0/L0s/L1等等)。这些请参见PCIe 3.0 spec,本文不再详述。
5. 其他VC的内容,和固件理解无关,本文不再提及。INT到MSI的部分会在将来介绍PC中断系统时详细讲解。
PCIe 1.0和2.0采用了8b/10b编码方式,这意味着每个字节(8b)都用10bit传输,这就是为什么2.5GHz和5GHz时钟,每时钟1b数据,结果不是312.5MB/s和625MB/s而是250MB/s和500MB/s。PCIe 3.0和4.0采用128b/130b编码,减小了浪费(overhead),所以才能在8GHz时钟下带宽达到1000MB/s(而不是800MB/s)。即将于今年发布的PCIe 4.0还会将频率提高一倍,达到16GHz,带宽达到2GB/s每Lane。
后记
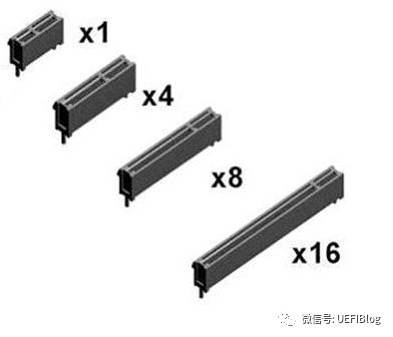
对于一般用户来说,PCIe对用户可见的部分就是主板上大大小小的PCIe插槽了,有时还和PCI插槽混在一起,造成了一定的混乱,其实也很好区分:

如图,PCI插槽都是等长的,防呆口位置靠上,大部分都是纯白色。PCIe插槽大大小小,最小的x1,最大的x16,防呆口靠下。各种PCIe插槽大小如下:
常见问题:
Q:我主板上没有x1的插槽,我x1的串口卡能不能插在x4的插槽里。
A: 可以,完全没有问题。除了有点浪费外,串口卡也将已x1的方式工作。
Q:我主板上只有一个x16的插槽,被我的显卡占据了。我还有个x16的RAID卡可以插在x8的插槽内吗?
A: 你也许会惊讶,但我的答案同样是:可以!你的RAID卡将以x8的方式工作。实际上来说,你可以将任何PCIe卡插入任何PCIe插槽中! PCIe在链接training的时候会动态调整出双方都可以接受的宽度。最后还有个小问题,你根本插不进去!呵呵,有些主板厂商会把PCIe插槽尾部开口,方便这种行为,不过很多情况下没有。这时怎么办?你懂的。。。。
Q: 我的显卡是PCIe 3.0的,主板是PCIe2.0的,能工作吗?
A: 可以,会以2.0工作。反之,亦然。
Q: 我把x16的显卡插在主板上最长的x16插槽中,可是benchmark下来却说跑在x8下,怎么回事?!
A: 主板插槽x16不见得就连在支持x16的root port上,最好详细看看主板说明书,有些主板实际上是x8。有个主板原理图就更方便了。
Q: 我新买的SSD是Mini PCIe的,Mini PCIe是什么鬼?
A: Mini PCIe接口常见于笔记本中,为54pin的插槽。多用于连接wifi网卡和SSD,注意不要和mSATA弄混了,两者完全可以互插,但大多数情况下不能混用(除了少数主板做了特殊处理),主板设计中的防呆设计到哪里去了!请仔细阅读主板说明书。另外也要小心不要和m.2(NGFF)搞混了,好在卡槽大小不一样。
PCI/PCIe软件界面
1。配置空间
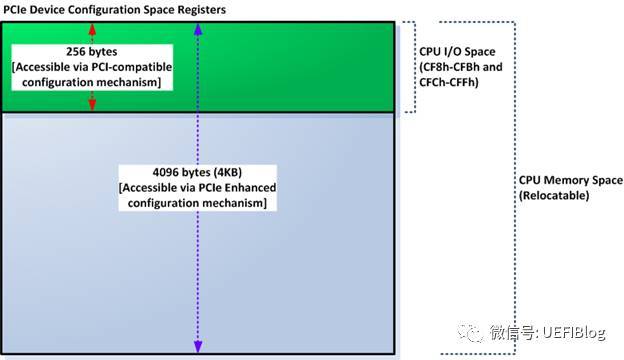
PCI spec规定了PCI设备必须提供的单独地址空间:配置空间(configuration space),前64个字节(其地址范围为0x000x3F)是所有PCI设备必须支持的(有不少简单的设备也仅支持这些),此外PCI/PCI-X还扩展了0x400xFF这段配置空间,在这段空间主要存放一些与MSI或者MSI-X中断机制和电源管理相关的Capability结构。
前文提到过,PCI配置空间和内存空间是分离的,那么如何访问这段空间呢?我们首先要对所有的PCI设备进行编码以避免冲突,通常我们是以三段编码来区分PCI设备,即Bus Number, Device Number和Function Number,以后我们简称他们为BDF。有了BDF我们既可以唯一确定某一PCI设备。不同的芯片厂商访问配置空间的方法略有不同,我们以Intel的芯片组为例,其使用IO空间的CF8h/CFCh地址来访问PCI设备的配置寄存器:

CF8h: CONFIG_ADDRESS。PCI配置空间地址端口。
CFCh: CONFIG_DATA。PCI配置空间数据端口。
CONFIG_ADDRESS寄存器格式:
31 位:Enabled位。
23:16 位:总线编号。
15:11 位:设备编号。
10: 8 位:功能编号。
7: 2 位:配置空间寄存器编号。
1: 0 位:恒为“00”。这是因为CF8h、CFCh端口是32位端口。
如上,在CONFIG_ADDRESS端口填入BDF,即可以在CONFIG_DATA上写入或者读出PCI配置空间的内容。
PCIe规范在PCI规范的基础上,将配置空间扩展到4KB。原来的CF8/CFC方法仍然可以访问所有PCIe设备配置空间的头255B,但是该方法访问不了剩下的(4K-255)配置空间。怎么办呢?Intel提供了另外一种PCIe配置空间访问方法:通过将配置空间映射到Memory map IO(MMIO)空间,对PCIe配置空间可以像对内存一样进行读写访问了。如图
这样再加上PCI板子上的RAM或者ROM,整个PCIe Device空间如下图:
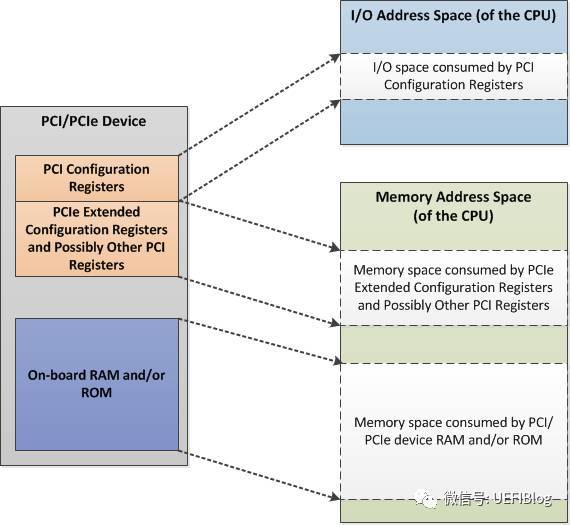
MMIO这段空间有256MB,因为按照PCIe规范,支持最多256个buses,每个Bus支持最多32个PCI devices,每个device支持最多8个function,也就是说:占用内存的最大值为:256 * 32 * 8 * 4K = 256MB。在台式机上我们很多时候觉得占用256MB空间太浪费(造成4G以下memory可用空间变少,虽然实际memory可以映射到4G以上,但对32位OS影响很大),PCI Bus也没有那么多,所以可以设置成最低64MB,即最多64个Bus。那么这个256MB的MMIO空间在在哪里呢?我们以Intel的Haswell平台为例:
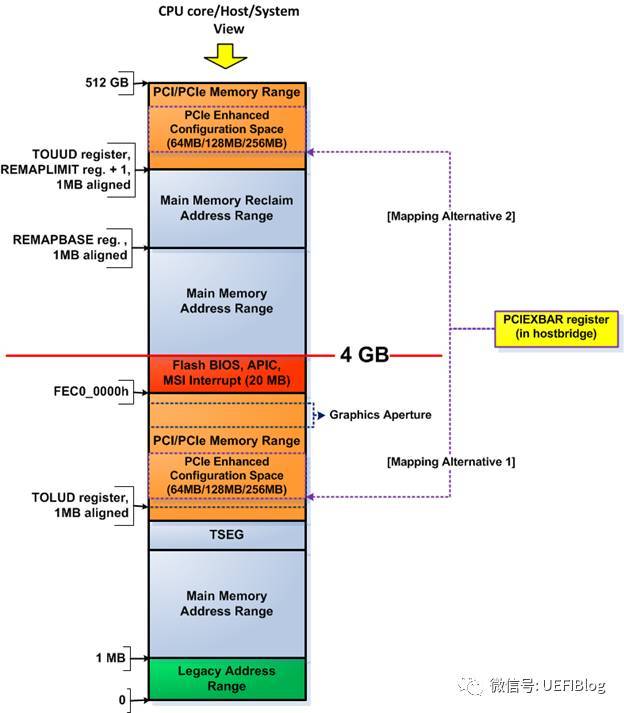
其中PCIEXBAR就是这个MMIO的起始位置,在4G下面占据64MB/128MB/256MB空间(4G以上部分不在本文范围内,我们今后会详细介绍固件中的内存布局),其具体位置可以由平台进行设置,设置寄存器一般在Root complex(下文简称RC)中。
如果大家忘记RC,可以参考前文硬件部分的典型PCIe框图。
RC是PCIe体系结构的一个重要组成部件,也是一个较为混乱的概念。RC的提出与x86处理器系统密切相关,PCIe总线规范中涉及的RC也以x86处理器为例进行说明,而且一些在PCIe总线规范中出现的最新功能也在Intel的x86处理器系统中率先实现。事实上,只有x86处理器才存在PCIe总线规范定义的“标准RC”,而在多数处理器系统,并不含有在PCIe总线规范中涉及的,与RC相关的全部概念。
在x86处理器系统中,RC内部集成了一些PCI设备、RCRB(RC Register Block)和Event Collector等组成部件。其中RCRB由一系列的寄存器组成的大杂烩,而仅存在于x86处理器中;而Event Collector用来处理来自PCIe设备的错误消息报文和PME消息报文。RCRB的访问基地址一般在LPC设备寄存器上设置。
如果将RC中的RCRB、内置的PCI设备和Event Collector去除,该RC的主要功能与PCI总线中的Host Bridge类似,其主要作用是完成存储器域到PCI总线域的地址转换。但是随着虚拟化技术的引入,尤其是引入MR-IOV技术之后,RC的实现变得异常复杂。
2。BAR空间
现在我们来看看在配置空间里具体有些什么。我们以一个一般的type 0(非Bridge)设备为例:
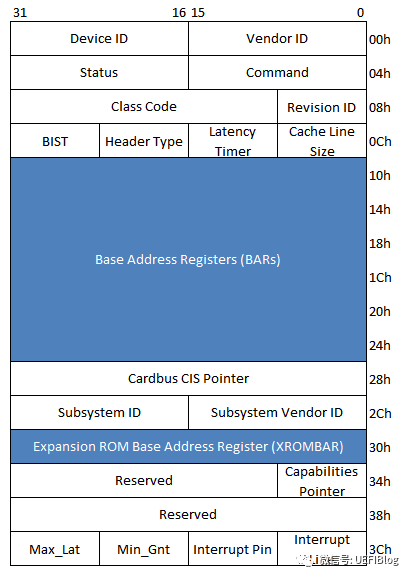
其中Device ID和Vendor ID是区分不同设备的关键,OS和UEFI在很多时候就是通过匹配他们来找到不同的设备驱动(Class Code有时也起一定作用)。为了保证其唯一性,Vendor ID应当向PCI特别兴趣小组(PCI SIG)申请而得到。
我们重点来了解一下这些Base Address Registers(BAR)。BAR是PCI配置空间中从0x10 到 0x24的6个register,用来定义PCI需要的配置空间大小以及配置PCI设备占用的地址空间。
每个PCI设备在BAR中描述自己需要占用多少地址空间,UEFI通过所有设备的这些信息构建一张完整的关系图,描述系统中资源的分配情况,然后在合理的将地址空间配置给每个PCI设备。
BAR在bit0来表示该设备是映射到memory还是IO,bar的bit0是readonly的,也就是说,设备寄存器是映射到memory还是IO是由设备制造商决定的,其他人无法修改。
下图是BAR寄存器的结构,分别是Memory和IO:
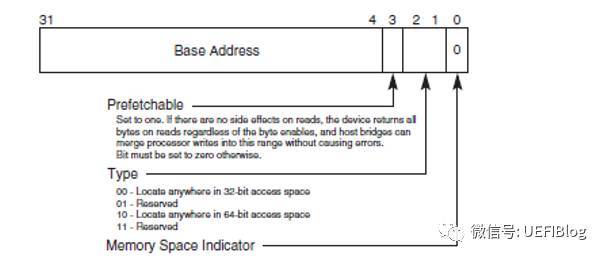
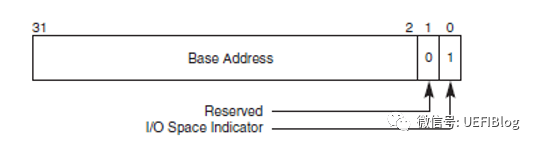
BAR通过将某些位设置为只读,且0来表示需要的地址空间大小,比如一个PCI设备需要占用1MB的地址空间,那么这个BAR就需要实现高12bit是可读写的,而20-4bit是只读且位0。地址空间大小的计算方法如下:
**a.**向BAR寄存器写全1
**b.**读回寄存器里面的值,然后clear 上图中特殊编码的值,(IO 中bit0,bit1, memory中bit0-3)。
**c.**对读回来的值去反,加一就得到了该设备需要占用的地址内存空间。
这样我们就可以在构建一张大表,用于记录所有PCI设备所需要的空间。这也是PCI枚举的主要任务之一。另外别忘记设置Command寄存器enable这些BARs。
3。PCI桥设备
PCI桥在PCI设备树中起到呈上起下的作用。一个PCI-to-PCI桥它的配置空间如下:
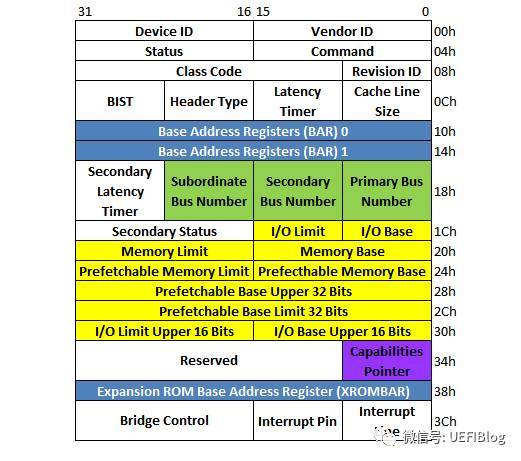
注意其中的三组绿色的BUS Number和多组黄色的BASE/Limit对,它决定了桥和桥下面的PCI设备子树相应/被分配的Bus和各种资源大小和位置。这些值都是由PCI枚举程序来设置的。
4。Capabilities结构
PCI-X和PCIe总线规范要求其设备必须支持Capabilities结构。在PCI总线的基本配置空间中,包含一个Capabilities Pointer寄存器,该寄存器存放Capabilities结构链表的头指针。在一个PCIe设备中,可能含有多个Capability结构,这些寄存器组成一个链表,其结构如图:
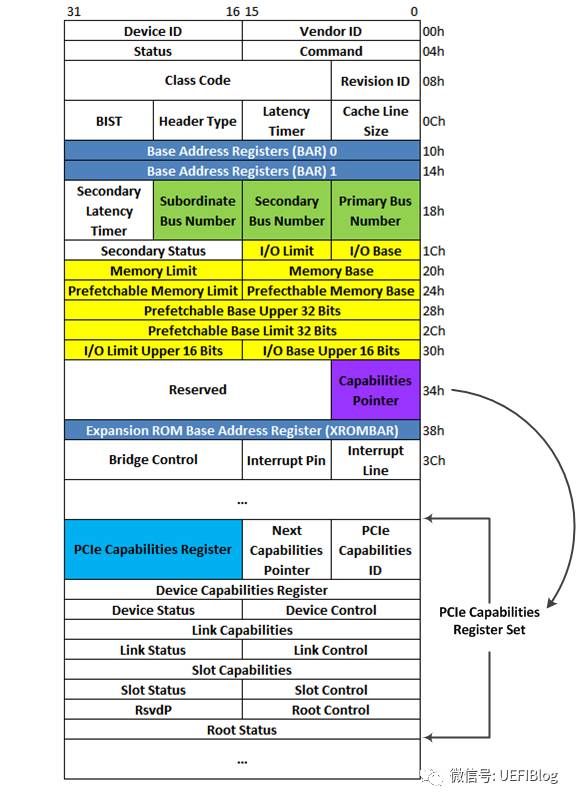
PCIe的各种特性如Max Payload、Complete Timeout(CTO)等等都通过这个链表链接在一起,Capabilities ID由PCIe spec规定。链表的好处是如果你不关心这个Capabilities(或不知道怎么处理),直接跳过,处理关心的即可,兼容性比较好。另外扩展性也强,新加的功能不会固定放在某个位置,淘汰的功能删掉即好。
5。PCI枚举
PCI枚举是个不断递归调用发现新设备的过程,PCI枚举简单来说主要包括下面几个步骤:
A. 利用深度优先算法遍历整个PCI设备树。从Root Complex出发,寻找设备和桥。发现桥后设置Bus,会发现一个PCI设备子树,递归回到A)
B. 递归的过程中通过读取BARs,记录所有MMIO和IO的需求情况并予以满足。
C. 设置必要的Capabilities
在整个过程结束后,一颗完整的资源分配完毕的树就建立好了。
6。地址译码
在PCI总线中定义了两种“地址译码”方式,一个是正向译码,一个是负向译码。当访问Bus N时,其下的所有PCI设备都将对出现在地址周期中的PCI总线地址进行译码。如果这个地址在某个PCI设备的BAR空间中命中时,这个PCI设备将接收这个PCI总线请求。这个过程也被称为PCI总线的正向译码,这种方式也是大多数PCI设备所采用的译码方式。
但是在PCI总线上的某些设备,如PCI-to-(E)ISA桥(或LPC)并不使用正向译码接收来自PCI总线的请求, PCI BUS N上的总线事务在三个时钟周期后,没有得到任何PCI设备响应时(即总线请求的PCI总线地址不在这些设备的BAR空间中),PCI-to-ISA桥将被动地接收这个数据请求。这个过程被称为PCI总线的负向译码。可以进行负向译码的设备也被称为负向译码设备。
在PCI总线中,除了PCI-to-(E)ISA桥可以作为负向译码设备,PCI桥也可以作为负向译码设备,但是PCI桥并不是在任何时候都可以作为负向译码设备。在绝大多数情况下,PCI桥无论是处理“来自上游总线(upstream)”,还是处理“来自下游总线(downstream)”的总线事务时,都使用正向译码方式。如图:
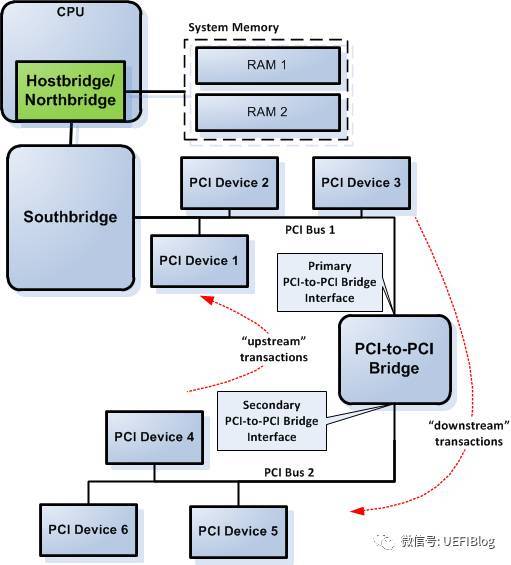
在某些特殊应用中,PCI桥也可以作为负向译码设备。PCI总线规定使用负向译码的PCI桥,其Base Class Code寄存器为0x06,Sub Class Code寄存器为0x04,而Interface寄存器为0x01;使用正向译码方式的PCI桥的Interface寄存器为0x00。
如笔记本在连接Dock插座时,也使用了PCI桥。因为在大多数情况下,笔记本与Dock插座是分离使用的,而且Dock插座上连接的设备多为慢速设备,此时用于连接Dock插座的PCI桥使用负向译码。在该桥管理的设备并不参与处理器系统对PCI总线的枚举过程。当笔记本插入到Dock之后,系统软件并不需要重新枚举Dock中的设备并为这些设备分配系统资源,而仅需要使用负向译码PCI桥管理好其下的设备即可,从而极大降低了Dock对系统软件的影响。
UEFI对PCI/PCIe的支持
UEFI对于PCI总线的支持包括以下三个方面:
1) 提供分配PCI设备资源的协议(Protocol)。
2) 提供访问PCI设备的协议(Protocol)。
3) 提供PCI枚举器,枚举PCI总线上的设备以及分配设备所需的资源。
4) 提供各种Lib,方便驱动程序访问PCI/PCIe配置空间或者MMIO/IO空间。
1.PCI驱动
UEFI BIOS提供了两个主要的模块来支持PCI总线,一个是PCI Host Bridge控制器驱动,另一个是PCI总线驱动。
PCI Host Bridge控制器驱动是跟特定的平台硬件绑定的。根据系统实际I/O空间和memory map,为PCI设备指定I/O空间和Memory空间的范围,并且产生PCI Host Bridge Resource Allocation 协议(Protocol)供PCI总线驱动使用。该驱动还对HostBridge控制器下所有RootBridge设备产生句柄(Handle),该句柄上安装了PciRootBridgeIoProtocol。PCI总线驱动则利用PciRootBridgeIo Protocol枚举系统中所有PCI设备,发现并获得PCI设备的Option Rom,并且调用PCI Host Bridge Resource Allocation 协议(Protocol)分配PCI设备资源。PCI Host Bridge Resource Allocation协议的实现是跟特定的芯和平台相结合的,毕竟只有平台所有者才知道资源从哪里来和有多少。每一个PCI HostBridge Controller下面可以接一个或者多个PCI root bridges,PCI Root Bridge会产生PCI local Bus。正如我们前文举得例子,如Intel志强第三代四路服务器,共四颗CPU,每个CPU都被划分了共享但区隔的Bus, PCI I/O, PCI Memory范围,其构成可以表示成如下图:
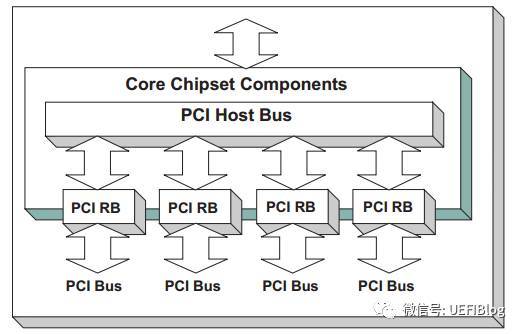
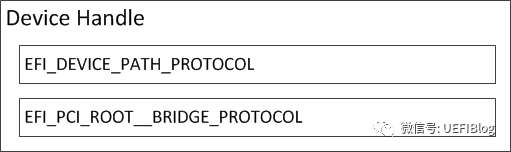
其他情况可见上文。PCI设备驱动不会使用PCI Root Bridge I/O协议访问PCI设备,而是会使用PCI总线驱动为PCI设备产生的PCI IO Protocol来访问PCI设备的IO/MEMORY空间和配置空间。PCI Root Bridge I/O协议(Protocol)是安装在RootBridge设备的句柄上(handle),同时在该handle上也会有表明RootBridge设备的DevicePath协议(Protocol),如下图所示
PCI总线驱动在BDS阶段会枚举整个PCI设备树并分配资源(BUS,MMIO和IO等),它还会在不同的枚举点调用Notify event通知平台,平台的Hook可以挂接在这些点上做些特殊的动作。具体各种点的定义请参阅UEFI spec。
PCI bus驱动在这里:tianocore/edk2
2。PCI Lib
在MdePackage下有很多PCI lib。有Cf8/CFC形式访问配置空间的,有PCIe方式访问的。都有些许不同。注意Cf8/CFC只能访问255以内的,而PCIe方式访问的要配置正确PCIe base address PCD。
结语
本篇没有介绍下列内容,以后有机会再补。
\1. Non-transparent bridge
\2. LPC
\3. 各种PCIe的feature
\4. MSI中断处理
如果你还觉得意犹未尽,仔细思考一下下面这些问题并找找资料有助于你更深入了解PCI/PCIe
1. 前文说过,PCIe的速度和Lane的数目是在Training的时候由Root Port和EndPoint协调得到的。那这个Training的过程发生在什么时候呢? (提示,Hard Strap,Soft Strap, Wait for BIOS/Bifurcation)。
2. UEFI PCI Bus枚举发生在BDS阶段,很靠后。那我们如果在芯片初始化阶段需要对PCI设备MMIO空间的寄存器甚至Bridge后面的设备做些设置,该怎么办呢?
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)