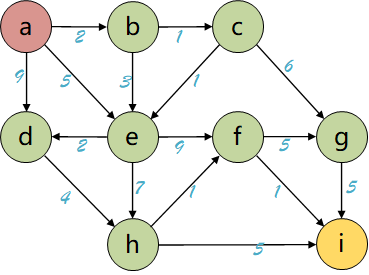
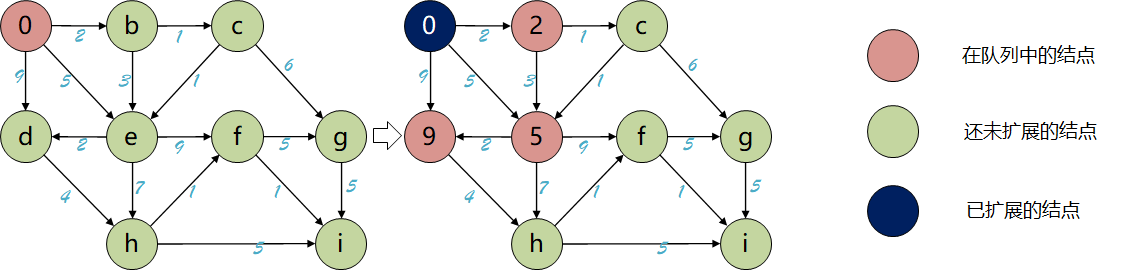
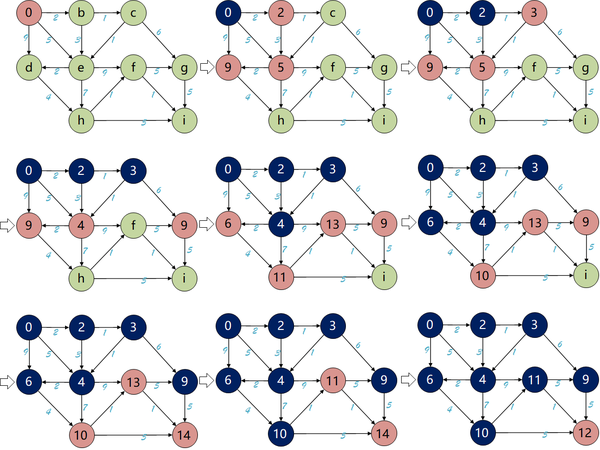
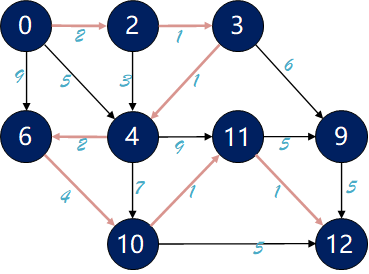
本文将从图搜索算法的基本流程入手,层层递进地介绍几种图搜索算法。首先是两种针对无权图的基本图搜索算法:深度优先搜索(Depth First Search, DFS)、广度优先搜索(Breadth First Search, BFS)。它们的区别在于openlist(后面介绍)所选用的数据结构类型不同,前者使用栈,后者使用队列;之后引入一种启发式搜索算法:贪婪最佳优先算法(Greedy Best First Search, GBFS),用来提高搜索效率,但是不能确保找到最优路径;最后介绍两种在路径规划中非常经典的算法:Dijkstra算法、A*算法,前者是广度优先算法(BFS)在带权图中的扩展,后者则是在前者中加入启发函数得到的算法,兼顾效率和完备性。
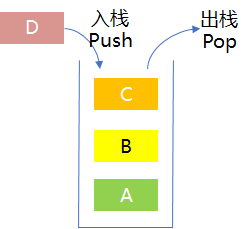
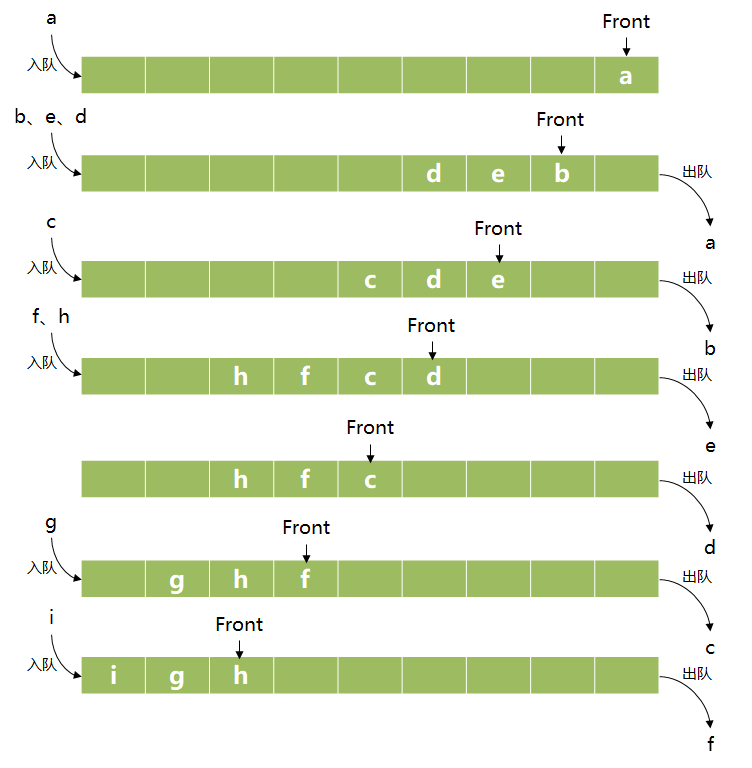
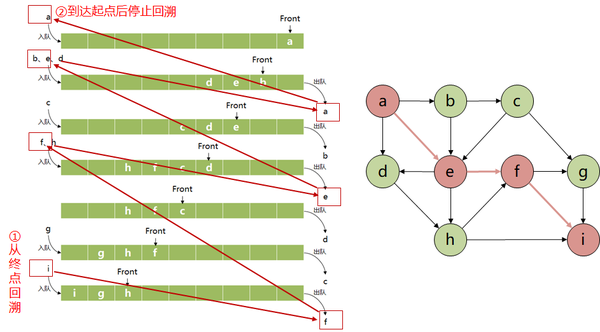
BFS和DFS的区别主要在于节点的弹出策略,根据弹出策略的区别,分别使用了队列和栈两种数据结构,而栈和队列作为两种相当基本的容器,只将节点进入容器的顺序作为弹出节点的依据,并未考虑目标位置等因素,这就使搜索过程变得漫无目的,导致效率低下。启发式搜索算法(Heuristic Algorithm)就是用来解决搜索效率问题的,下面将以贪婪最佳优先算法(Greedy Best First Search, GBFS)为例来介绍启发式搜索算法。
GBFS也是图搜索算法的一种,它的算法流程和BFS、DFS并没有本质的不同,区别仍然在于openlist采用的数据结构,GBFS使用的是优先队列(Priority Queue),普通队列是一种先进先出的数据结构,而在优先队列中元素被赋予了优先级,最高优先级元素优先删除,也就是first in, largest out。(记住这种数据结构,后面的Dijkstra和A*算法都会用到这个结构)。
在图搜索算法中,使用代价函数
f
(
n
)
f(n)
f(n)来作为优先级判断的标准,
f
(
n
)
f(n)
f(n)越小,优先级越高,反之优先级越低。
GBFS作为一种启发式搜索算法,使用启发评估函数
h
(
n
)
h(n)
h(n)来作为代价函数,也就是
f
(
n
)
=
h
(
n
)
f(n)=h(n)
f(n)=h(n) 其中
h
(
n
)
h(n)
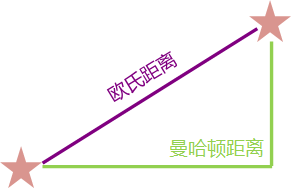
h(n)是当前节点到终点的代价,它可以指引搜索算法往终点靠近,主要用欧氏距离(Euclidean Distance) 或者曼哈顿距离(Manhattan Distance) 来表示,它们的区别如下图:
假设有两个点
(
x
1
,
y
1
)
(x_1, y_1)
(x1,y1)和
(
x
2
,
y
2
)
(x_2,y_2)
(x2,y2),则它们的欧氏距离和曼哈顿距离分别为:
D
E
u
c
l
i
d
e
a
n
=
(
x
1
−
x
2
)
2
+
(
y
1
−
y
2
)
2
D
M
a
n
h
a
t
t
a
n
=
∣
x
1
−
x
2
∣
+
∣
y
1
−
y
2
∣
D_{Euclidean}=\sqrt{(x_1-x_2)^2 + (y_1 - y_2)^2}\\ D_{Manhattan}=|x_1-x_2| + |y_1-y_2|
DEuclidean=(x1−x2)2+(y1−y2)2DManhattan=∣x1−x2∣+∣y1−y2∣
Dijkstra算法是从一个顶点到其余各顶点的最短路径算法,其流程仍然与上述算法基本一致,它也是用优先队列作为openlist的数据结构,它和GBFS的区别在于代价函数
f
(
n
)
f(n)
f(n)的定义,Dijkstra算的
f
(
n
)
f(n)
f(n)定义为:
f
(
n
)
=
g
(
n
)
f(n)=g(n)
f(n)=g(n) 其中
g
(
n
)
g(n)
g(n)表示从起点到当前点的移动代价。
A*算法也是一种启发式算法,它的代价函数表示为:
f
(
n
)
=
g
(
n
)
+
h
(
n
)
f(n)=g(n)+h(n)
f(n)=g(n)+h(n) 其中
g
(
n
)
g(n)
g(n)为起点到当前扩展节点的移动代价函数,
h
(
n
)
h(n)
h(n)是启发函数,用节点到目标点的距离函数来表示。
根据这个式子,可以得到A*算法的几个特点:
如果令
h
(
n
)
=
0
h(n)=0
h(n)=0,A* 算法就退化为Dijkstra算法;如果令
g
(
n
)
=
0
g(n)=0
g(n)=0,A* 算法就退化为GBFS算法。
能否找到最优路径的关键是启发函数
h
(
n
)
h(n)
h(n)的选取,如果
h
(
n
)
h(n)
h(n)在大部分情况下比从当前节点到目标点的移动代价小,则能找到最优路径。
由于A* 算法的启发函数是位置上的距离,因此在不带位置信息的图数据中不适用。
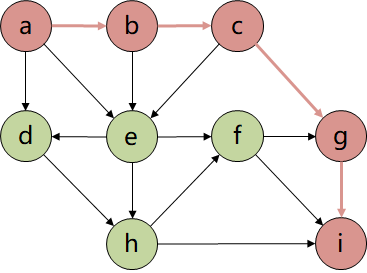
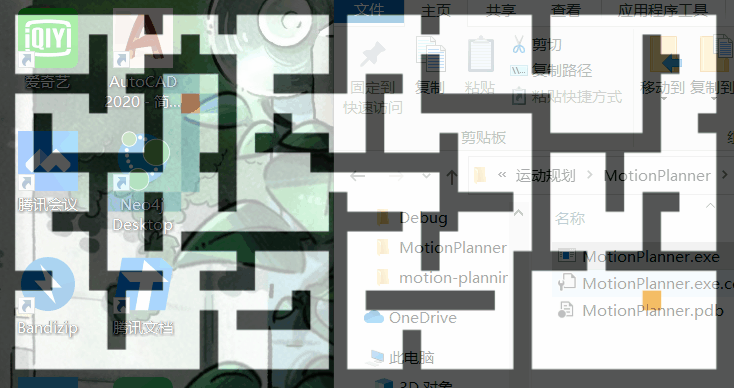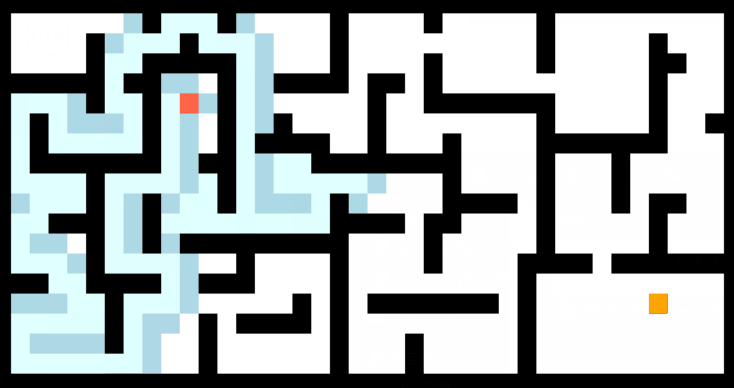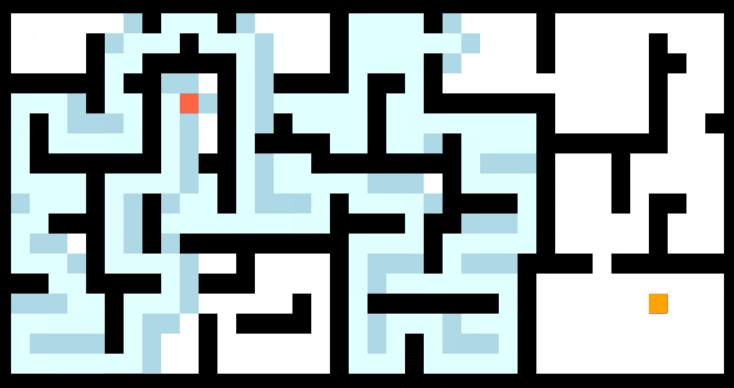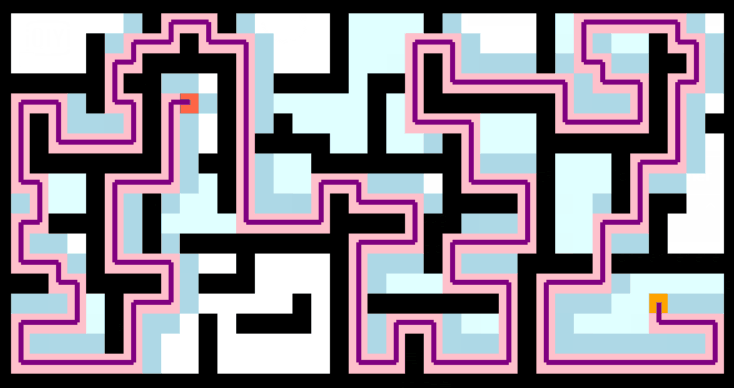
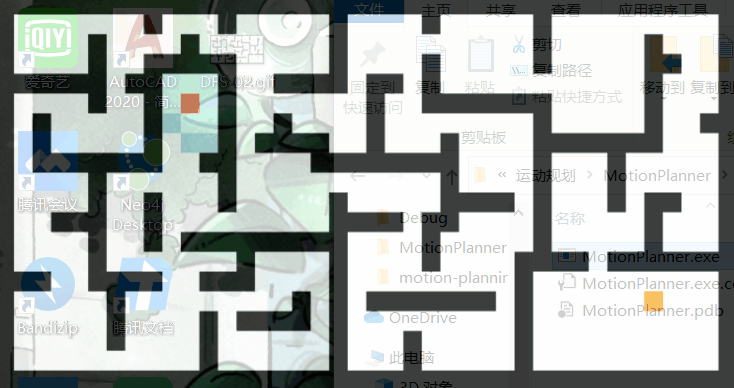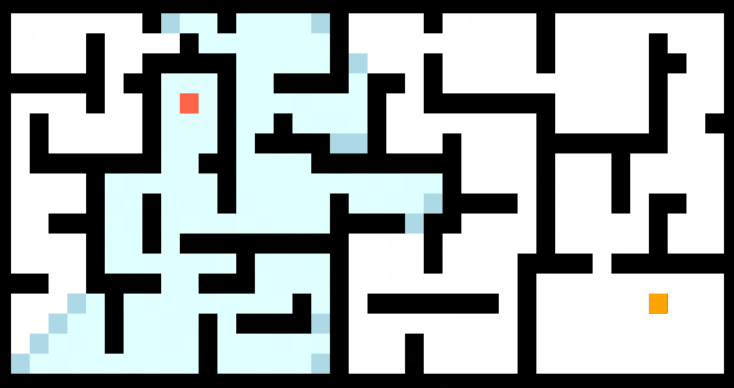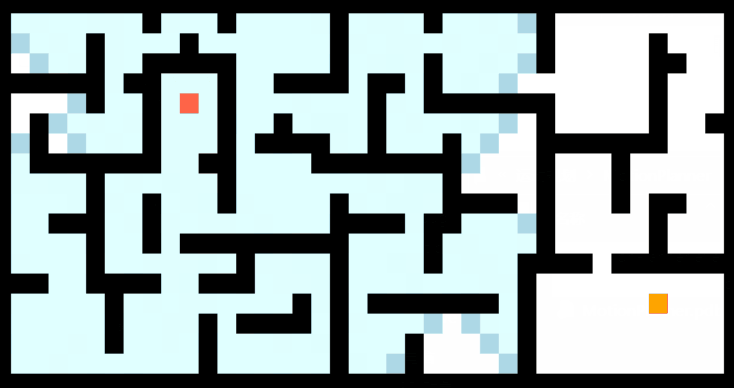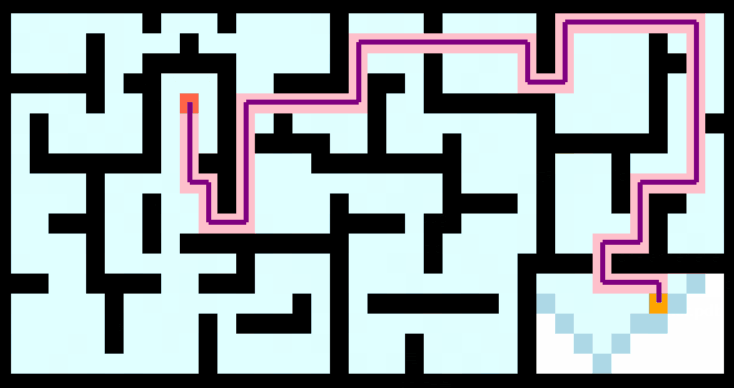
将A*算法应用到二维地图路径规划中,如下图:
附录:图基础
本节附录将介绍什么是图数据结构,以及图数据结构在计算机中的表示方法。
图结构
图结构是一种由数据元素集合及元素间的关系集合组成的非线性数据结构。数据元素用节点(node)表示,元素间的关系用边(edge)表示,如果两个元素相关,就用一条边将相应的节点连接起来,这两个节点称为相邻节点。根据边的方向性,可以分为无向图和有向图,一个无向图G记做
G
=
(
V
,
E
)
G=(V,E)
G=(V,E),其中
V
V
V是节点的有限集合,
E
E
E是边的有限集合,则有:
V
=
{
x
∣
x
∈
某个具有相同特性的数据元素集合
}
E
=
{
e
(
x
,
y
)
∣
x
,
y
∈
V
}
V=\{x|x\in某个具有相同特性的数据元素集合 \}\\ E=\{e(x,y)|x,y\in V\}
V={x∣x∈某个具有相同特性的数据元素集合}E={e(x,y)∣x,y∈V} 上式中,
e
(
x
,
y
)
e(x,y)
e(x,y)表示节点x和节点y之间的相邻关系,是一种无序节点对,无方向性,称为连接节点x和节点y的一条边。如果节点间关系是有序节点对,则用
e
<
x
,
y
>
e<x,y>
e<x,y>表示,表示从节点x到节点y的一条单向边,是有方向的,则有向边的集合可表示为:
E
=
{
e
<
x
,
y
>
∣
x
,
y
∈
V
}
E=\{e<x,y>|x,y\in V\}
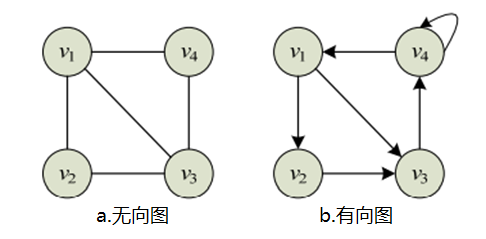
E={e<x,y>∣x,y∈V} 下图分别为无向图和有向图的图形化示例:
上图中的无向图可以表示为:
V
(
G
)
=
{
v
1
,
v
2
,
v
3
,
v
4
}
E
(
G
)
=
{
(
v
1
,
v
2
)
,
(
v
1
,
v
3
)
,
(
v
1
,
v
4
)
,
(
v
2
,
v
3
)
,
(
v
3
,
v
4
)
}
V(G)=\{v_1,v_2,v_3,v_4\}\\ E(G)=\{(v_1,v_2),(v_1,v_3),(v_1,v_4),(v_2,v_3),(v_3,v_4)\}
V(G)={v1,v2,v3,v4}E(G)={(v1,v2),(v1,v3),(v1,v4),(v2,v3),(v3,v4)} 有向图可表示为:
V
(
G
)
=
{
v
1
,
v
2
,
v
3
,
v
4
}
E
(
G
)
=
{
<
v
1
,
v
2
>
,
<
v
1
,
v
3
>
,
<
v
2
,
v
3
>
,
<
v
3
,
v
4
>
,
<
v
4
,
v
4
>
,
<
v
4
,
v
1
>
}
V(G)=\{v_1,v_2,v_3,v_4\}\\ E(G)=\{<v_1,v_2>,<v_1,v_3>,<v_2,v_3>,<v_3,v_4>,<v_4,v_4>,<v_4,v_1>\}
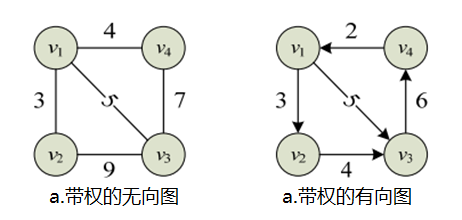
V(G)={v1,v2,v3,v4}E(G)={<v1,v2>,<v1,v3>,<v2,v3>,<v3,v4>,<v4,v4>,<v4,v1>} 在图中除了用边表示两个节点之间的相邻关系外,有时还需要表示它们相关的强度信息,例如从一个节点到另一个节点的距离、花费的代价、所需的时间等,诸如此类的信息可以通过在图的每条边上加上一个称作权(weight)的数值表示,这类图称为带权图
上述就是图结构的基本概念,我们还需要知道图结构在计算机中的表示方法
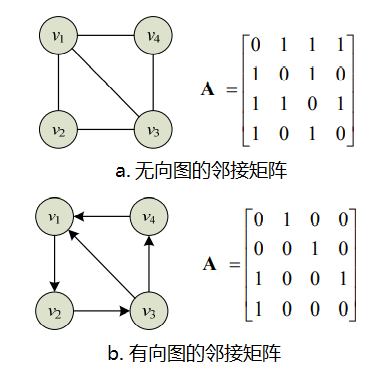
图结构的邻接矩阵表示法
邻接矩阵用来表示图的边集,即节点间的相邻关系集合。设
G
=
(
V
,
E
)
G=(V,E)
G=(V,E)是一个具有n个节点的图,它的邻接矩阵是一个n阶矩阵,则其中的元素
a
i
j
a_{ij}
aij满足:
a
i
j
=
{
1
若
e
(
v
i
,
v
j
)
∈
E
或者
e
<
v
i
,
v
j
>
∈
E
0
若
e
(
v
i
,
v
j
)
∉
E
或者
e
<
v
i
,
v
j
>
∉
E
a_{ij}=\begin{cases}1&若e(v_i,v_j)\in E或者e<v_i,v_j>\in E\\ 0&若e(v_i,v_j)\notin E或者e<v_i,v_j>\notin E\end{cases}
aij={10若e(vi,vj)∈E或者e<vi,vj>∈E若e(vi,vj)∈/E或者e<vi,vj>∈/E 对于无向图,其邻接矩阵是对称矩阵,即
a
i
j
=
a
j
i
a_{ij}=a_{ji}
aij=aji,而有向图的邻接矩阵不一定对称,其空间复杂度均为
O
(
n
2
)
O(n^2)
O(n2)。以下为两个不带权图的邻接矩阵示例:
对于带权图,设
e
(
v
i
,
v
j
)
e(v_i,v_j)
e(vi,vj)或者
e
<
v
i
,
v
j
>
e<v_i,v_j>
e<vi,vj>上的权值为
w
i
j
w_{ij}
wij,则带权图的邻接矩阵定义为:
a
i
j
=
{
w
i
j
若
e
(
v
i
,
v
j
)
∈
E
或者
e
<
v
i
,
v
j
>
∈
E
∞
若
e
(
v
i
,
v
j
)
∉
E
或者
e
<
v
i
,
v
j
>
∉
E
0
若
v
i
=
v
j
a_{ij}=\begin{cases}w_{ij}&若e(v_i,v_j)\in E或者e<v_i,v_j>\in E\\ \infty&若e(v_i,v_j)\notin E或者e<v_i,v_j>\notin E\\ 0&若v_i=v_j \end{cases}
aij=⎩⎨⎧wij∞0若e(vi,vj)∈E或者e<vi,vj>∈E若e(vi,vj)∈/E或者e<vi,vj>∈/E若vi=vj 以下为两个带权图的邻接矩阵示例:
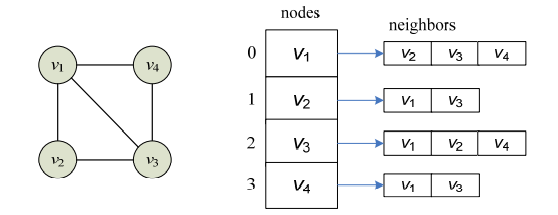
图结构的邻接表表示法
邻接矩阵表示法的空间复杂度为
O
(
n
2
)
O(n^2)
O(n2),其占用的空间大小与图中节点数量相关,而与边的数目无关。对于稀疏图,其边的数量可能远小于
n
2
n^2
n2,这样邻接矩阵中就会有很多零或
∞
\infty
∞元素。对于这种情况,可以用节点表和邻接表来表示和存储图结构,其占用的存储空间既与图的节点数有关,也与边数有关。