一、运行时优化
Grappler是TensorFlow提供的运行时优化功能,图1为Grappler模块主要功能的UML关系图。其中tensorflow.grappler.GrapplerItem:表示待优化的TensforFlow模型,主要包括计算图、fetch节点、feed节点;
tensorflow.grappler.GraphOptimizer:是grappler中所有派生类的父类;tensorflow.grappler.MetaOptimizer: 进行op fusion的优化类;
tensorflow.gappler.ModelPruner:裁剪计算图,剔除不需要的节点;tensorflow.grappler.ConstantFolding:做常量的折叠,所谓的常量折叠是将计算图中可以预先可以确定输出值的节点替换成常量,并对计算图进行一些结构简化的操作。
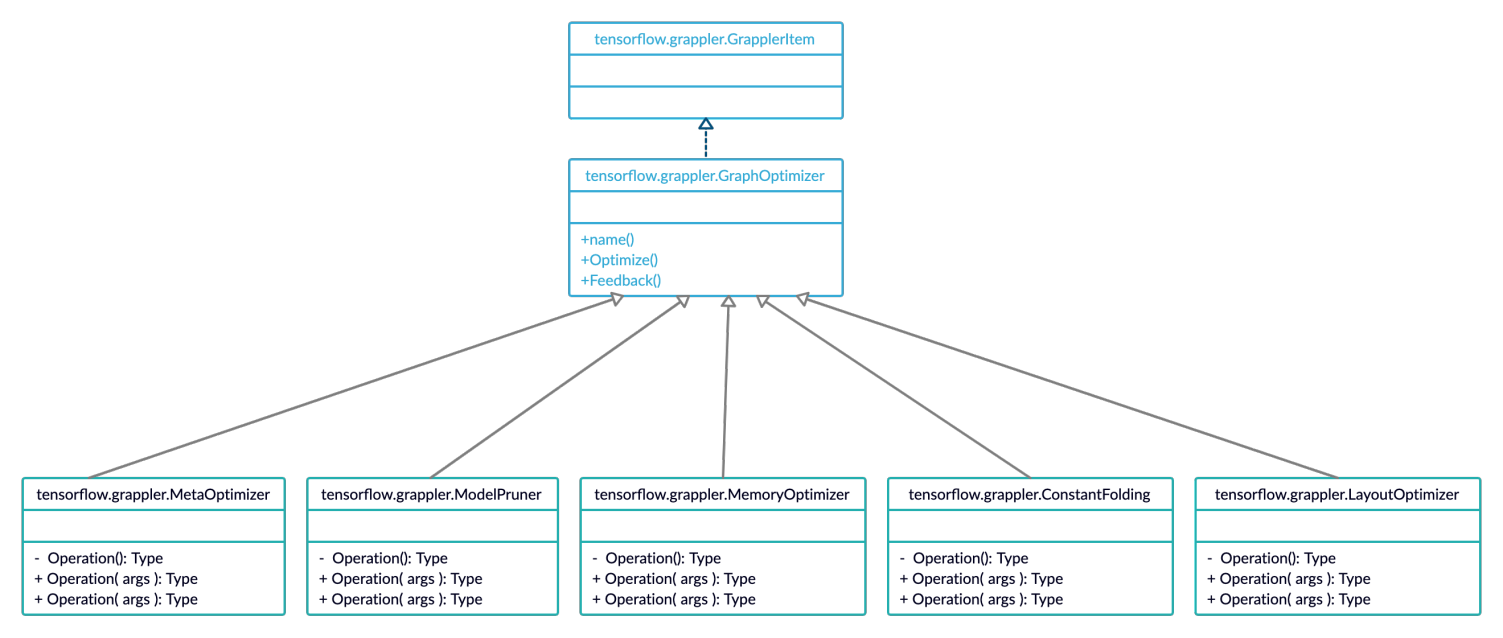
图1 grappler模块类的UML结构
运行时优化与离线优化不同,只在inference会话时对加载的graph进行online优化,并不会改变用户保存的graph结构。创建session会话,tensorflow默认开启Grappler全部的优化功能。经过测试以及论证,通过有效的配置可进一步提升inference效率。
layout optimizer优化
通常情况,卷积内存布局分为NHWC以及NCHW两种格式。tensorflow默认layout为NHWC,通常开启layout optimizer选项,GPU模式下运行时将layout转换为NCHW。
经实验可知在卷积kernel size大于1的情况下,GPU测试在NCHW的内存布局上执行的效率高于NHWC格式。而当卷积kernel size为1时,tensorflow源码在laytout为NHWC时采用矩阵乘的方式,layout为NCHW时则采用cuDNN卷积实现,此时在GPU上测试Conv2D执行效率,NCHW格式执行效率会低于NHWC格式。
故根据模型结构,合理配置layout optimizer功能能更好的发挥Grappler优化器的效果。ALPS根据业务需求提炼出得的一系列image模型存在大量的1x1卷积,关闭该选项inference效率相比默认开启时效率更高。
二、离线优化
graph transformtool是tf提供的离线图优化工具,具体使用形式包含python API以及命令行两种。
接口介绍:
2.1 remapper
remapper表示对op或者op组合做了重新映射,目前支持的映射组合case列为: Conv2D+FusedBatchNorm --> Conv2D+BiasAdd;
Conv2D+BatchNormWithGlobalNormalization --> Conv2D+BiasAdd;
MatMul+FusedBatchNorm --> MatMul+BiasAdd;
MatMul+BatchNormWithGlobalNormalization --> MatMul+BiasAdd。
BN层实现如公式(1):
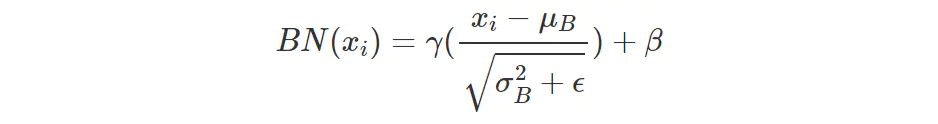
(1)
将BN层与卷积以及矩阵乘通过参数融合,重映射为BiasAdd,经过映射BN层的参数融合到卷积以及矩阵乘,乘加操作减少为BiasAdd层的加法操作,有效减少了计算量。
2.1.2 Constant folding optimizer
该类优化主要对graph结构做进一步简化,主要优化结构包含:
1)删除冗余的算子: identity Reshape, Transpose 1-d tensor,Slice(x) = x等等。
2)通过Enter进行的常量传播;
3)重写依赖;
Constant push-down:
■ Add(c1, Add(x, c2)) => Add(x, c1 + c2)
■ ConvND(c1 * x, c2) => ConvND(x, c1 * c2)
Partial constfold:
■ AddN(c1, x, c2, y) => AddN(c1 + c2, x, y),
■ Concat([x, c1, c2, y]) = Concat([x, Concat([c1, c2]), y)
Operations with neutral & absorbing elements:
■ x * Ones(s) => Identity(x), if shape(x) == output_shape
■ x * Ones(s) => BroadcastTo(x, Shape(s)), if shape(s) == output_shape
■ Same for x + Zeros(s) , x / Ones(s), x * Zeros(s) etc.
■ Zeros(s) - y => Neg(y), if shape(y) == output_shape
■ Ones(s) / y => Recip(y) if shape(y) == output_shape
2.1.3 strip unused nodes
tensorflow计通过构图搭建好完整的计算图,且提供了接口可直接指定计算图的输入输出,指定了inputs/outputs,实际运行的输入输出流所产生的数据依赖图应当是原始构造的graph结构的子集,通过使用strip_unused_nodes功能可删除不在数据依赖中的节点以及参数。
2.1.4 remove training nodes
该功能主要删除一些训练过程存在的一些冗余节点,包括标志节点identity、检查节点CheckNumerics等。在inference阶段,通过判断该类节点是否存在数据流控制依赖对节点进行删除。
结论:单独的graph transform优化对模型inference效率提升的数据。列表中GPU提升在11%~22%之间。
graph transform + layout optimize组合优化后的效率与原始的predict接口inference的时间的对比,相比较原来的inference,组合优化提升效率较明显,GPU提升在20%~37%之间,CPU上同样略有提升。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)