https://www.cnblogs.com/hunter-56213/p/6230442.html
Hazelcast是什么
“分布式”、“集群服务”、“网格式内存数据”、“分布式缓存“、“弹性可伸缩服务”——这些牛逼闪闪的名词拿到哪都是ITer装逼的不二之选。在Javaer的世界,有这样一个开源项目,只需要引入一个jar包、只需简单的配置和编码即可实现以上高端技能,他就是 Hazelcast。
Hazelcast 是由Hazelcast公司(没错,这公司也叫Hazelcast!)开发和维护的开源产品,可以为基于jvm环境运行的各种应用提供分布式集群和分布式缓存服务。Hazelcast可以嵌入到任何使用Java、C++、.NET开发的产品中(C++、.NET只提供客户端接入)。Hazelcast目前已经更新到3.X版本,Java中绝大部分数据结构都被其以为分布式的方式实现。比如Javaer熟悉的Map接口,当通过Hazelcast创建一个Map实例后,在节点A调用 Map::put("A","A_DATA") 方法添加数据,节点B使用 Map::get("A") 可以获到值为"A_DATA" 的数据。Hazelcast 提供了 Map、Queue、MultiMap、Set、List、Semaphore、Atomic 等接口的分布式实现;提供了基于Topic 实现的消息队列或订阅\发布模式;提供了分布式id生成器(IdGenerator);提供了分布式事件驱动(Distributed Events);提供了分布式计算(Distributed Computing);提供了分布式查询(Distributed Query)。总的来说在独立jvm经常使用数据结果或模型 Hazelcast 都提供了分布式集群的实现。
Hazelcast 有开源版本和商用版本。开源版本遵循 Apache License 2.0 开源协议免费使用。商用版本需要获取特定的License,两者之间最大的区别在于:商用版本提供了数据高密度存储。我们都知道jvm有自己特定的GC机制,无论数据是在堆还是栈中,只要发现无效引用的数据块,就有可能被回收。而Hazelcast的分布式数据都存放在jvm的内存中,频繁的读写数据会导致大量的GC开销。使用商业版的Hazelcast会拥有高密度存储的特性,大大降低Jvm的内存开销,从而降低GC开销。
很多开源产品都使用Hazelcast 来组建微服务集群,例如咱们的Vert.x,首选使用Hazelcast来组建分布式服务。有兴趣可以看我的这篇分享——http://my.oschina.net/chkui/blog/678347 ,文中说明了Vert.x如何使用Hazelcast组建集群。
附:
- Hazelcast源码:https://github.com/hazelcast/hazelcast
- 关于Hazelcast的问题可以到https://github.com/hazelcast/hazelcast/issues或http://stackoverflow.com。
Hazelcast的特性
自治集群(无中心化)
Hazelcast 没有任何中心节点(文中的节点可以理解为运行在任意服务器的独立jvm,下同),或者说Hazelcast 不需要特别指定一个中心节点。在运行的过程中,它自己选定集群中的某个节点作为中心点来管理所有的节点。
数据按应用分布式存储
Hazelcast 的数据是分布式存储的。他会将数据尽量存储在需要使用该项数据的节点上,以实现数据去中心化的目的。在传统的数据存储模型中(MySql、MongDB、Redis 等等)数据都是独立于应用单独存放,当需要提升数据库的性能时,需要不断加固单个数据库应用的性能。即使是现在大量的数据库支持集群模式或读写分离,但是基本思路都是某几个库支持写入数据,其他的库不断的拷贝更新数据副本。这样做的坏处一是会产生大量脏读的问题,二是消耗大量的资源来传递数据——从数据源频繁读写数据会耗费额外资源,当数据量增长或创建的主从服务越来越多时,这个消耗呈指数级增长。
使用 Hazelcast 可以有效的解决数据中心化问题。他将数据分散的存储在每个节点中,节点越多越分散。每个节点都有各自的应用服务,而Hazelcast集群会根据每个应用的数据使用情况分散存储这些数据,在应用过程中数据会尽量“靠近”应用存放。这些在集群中的数据共享整个集群的存储空间和计算资源。
抗单点故障
集群中的节点是无中心化的,每个节点都有可能随时退出或随时进入。因此,在集群中存储的数据都会有一个备份(可以配置备份的个数,也可以关闭数据备份)。这样的方式有点类似于 hadoop,某项数据存放在一个节点时,在其他节点必定有至少一个备份存在。当某个节点退出时,节点上存放的数据会由备份数据替代,而集群会重新创建新的备份数据。
简易性
所有的 Hazelcast 功能只需引用一个jar包,除此之外,他不依赖任何第三方包。因此可以非常便捷高效的将其嵌入到各种应用服务器中,而不必担心带来额外的问题(jar包冲突、类型冲突等等)。他仅仅提供一系列分布式功能,而不需要绑定任何框架来使用,因此适用于任何场景。
除了以上特性,Hazelcast 还支持服务器/客户端模型,支持脚本管理、能够和 Docker 快速整合等等。
简单使用例子
前面说了那么多概念,必须要来一点干货了。下面是一个使用 Hazelcast 的极简例子。文中的所有代码都在github上:https://github.com/chkui/hazelcast-demo。
首先引入Hazelcast的jar包。
Maven(pom.xml):
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>${hazelcast.vertsion}</version>
</dependency>
Gradle(build.gradle):
compile com.hazelcast:hazelcast:${hazelcast.vertsion}
先创一个建 Hazelcast 节点:
//org.palm.hazelcast.getstart.HazelcastGetStartServerMaster
public class HazelcastGetStartServerMaster {
public static void main(String[] args) {
// 创建一个 hazelcastInstance实例
HazelcastInstance instance = Hazelcast.newHazelcastInstance();
// 创建集群Map
Map<Integer, String> clusterMap = instance.getMap("MyMap");
clusterMap.put(1, "Hello hazelcast map!");
// 创建集群Queue
Queue<String> clusterQueue = instance.getQueue("MyQueue");
clusterQueue.offer("Hello hazelcast!");
clusterQueue.offer("Hello hazelcast queue!");
}
}
上面的代码使用 Hazelcast 实例创建了一个节点。然后通过这个实例创建了一个分布式的Map和分布式的Queue,并向这些数据结构中添加了数据。运行这个main方法,会在console看到以下内容:
Members [1] {
Member [192.168.1.103]:5701 this
}
随后再创建另外一个节点:
// org.palm.hazelcast.getstart.HazelcastGetStartServerSlave
public class HazelcastGetStartServerSlave {
public static void main(String[] args) {
//创建一个 hazelcastInstance实例
HazelcastInstance instance = Hazelcast.newHazelcastInstance();
Map<Integer, String> clusterMap = instance.getMap("MyMap");
Queue<String> clusterQueue = instance.getQueue("MyQueue");
System.out.println("Map Value:" + clusterMap.get(1));
System.out.println("Queue Size :" + clusterQueue.size());
System.out.println("Queue Value 1:" + clusterQueue.poll());
System.out.println("Queue Value 2:" + clusterQueue.poll());
System.out.println("Queue Size :" + clusterQueue.size());
}
}
该节点的作用是从Map、Queue中读取数据并输出。运行会看到以下输出
Members [2] {
Member [192.168.1.103]:5701
Member [192.168.1.103]:5702 this
}
八月 06, 2016 11:33:29 下午 com.hazelcast.core.LifecycleService
信息: [192.168.1.103]:5702 [dev] [3.6.2] Address[192.168.1.103]:5702 is STARTED
Map Value:Hello hazelcast map!
Queue Size :2
Queue Value 1:Hello hazelcast!
Queue Value 2:Hello hazelcast queue!
Queue Size :0
至此,2个节点的集群创建完毕。第一个节点向map实例添加了{key:1,value:"Hello hazelcast map!"},向queue实例添加[“Hello hazelcast!”,“Hello hazelcast queue!”],第二个节点读取并打印这些数据。
除了直接使用Hazelcast服务来组建集群,Hazelcast还提供了区别于服务端的客户端应用包。客户端与服务端最大的不同是:他不会存储数据也不能修改集群中的数据。目前客户端有C++、.Net、Java多种版本。
使用客户端首先要引入客户端jar包。
Maven(pom.xml):
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-client</artifactId>
<version>${hazelcast.version}</version>
</dependency>
Gradle(build.gradle):
compile com.hazelcast:hazelcast-client:${hazelcast.vertsion}
创建一个client节点。
public class HazelcastGetStartClient {
public static void main(String[] args) {
ClientConfig clientConfig = new ClientConfig();
HazelcastInstance instance = HazelcastClient.newHazelcastClient(clientConfig);
Map<Integer, String> clusterMap = instance.getMap("MyMap");
Queue<String> clusterQueue = instance.getQueue("MyQueue");
System.out.println("Map Value:" + clusterMap.get(1));
System.out.println("Queue Size :" + clusterQueue.size());
System.out.println("Queue Value 1:" + clusterQueue.poll());
System.out.println("Queue Value 2:" + clusterQueue.poll());
System.out.println("Queue Size :" + clusterQueue.size());
}
}
然后先启动 HazelcastGetStartServerMaster::main,再启动 HazelcastGetStartClient::main。可以看到客户端输出:
Members [1] {
Member [192.168.197.54]:5701
}
八月 08, 2016 10:54:22 上午 com.hazelcast.core.LifecycleService
信息: HazelcastClient[hz.client_0_dev][3.6.2] is CLIENT_CONNECTED
Map Value:Hello hazelcast map!
Queue Size :2
Queue Value 1:Hello hazelcast!
Queue Value 2:Hello hazelcast queue!
Queue Size :0
至此,客户端功能也创建完毕 。可以看到客户端的console输出内容比服务端少了很多,这是因为客户端不必承载服务端的数据处理功能,也不必维护各种节点信息。
例子运行解析
下面我们根据console的输出来看看 Hazelcast 启动时到底干了什么事。(下面的输出因环境或IDE不同,可能会有差异)
class: com.hazelcast.config.XmlConfigLocator
info: Loading 'hazelcast-default.xml' from classpath.
这里输出的内容表示Hazelcast启动时加载的配置文件。如果用户没有提供有效的配置文件,Hazelcast会使用默认配置文件。后续的文章会详细说明 Hazelcast 的配置。
class: com.hazelcast.instance.DefaultAddressPicker
info: Prefer IPv4 stack is true.
class: com.hazelcast.instance.DefaultAddressPicker
info: Picked Address[192.168.197.54]:5701, using socket ServerSocket[addr=/0:0:0:0:0:0:0:0,localport=5701], bind any local is true
这一段输出说明了当前 Hazelcast 的网络环境。首先是检测IPv4可用且检查到当前的IPv4地址是192.168.197.54。然后使用IPv6启用socket。在某些无法使用IPv6的环境上,需要强制指定使用IPv4,增加jvm启动参数:-Djava.net.preferIPv4Stack=true 即可。
class: com.hazelcast.system
info: Hazelcast 3.6.2 (20160405 - 0f88699) starting at Address[192.168.197.54]:5701
class: com.hazelcast.system
info: [192.168.197.54]:5701 [dev] [3.6.2] Copyright (c) 2008-2016, Hazelcast, Inc. All Rights Reserved.
这一段输出说明了当前实例的初始化端口号是5701。Hazelcast 默认使用5701端口。如果发现该端口被占用,会+1查看5702是否可用,如果还是不能用会继续向后探查直到5800。Hazelcast 默认使用5700到5800的端口,如果都无法使用会抛出启动异常。
class: com.hazelcast.system
info: [192.168.197.54]:5701 [dev] [3.6.2] Configured Hazelcast Serialization version : 1
class: com.hazelcast.spi.OperationService
info: [192.168.197.54]:5701 [dev] [3.6.2] Backpressure is disabled
class: com.hazelcast.spi.impl.operationexecutor.classic.ClassicOperationExecutor
info: [192.168.197.54]:5701 [dev] [3.6.2] Starting with 2 generic operation threads and 4 partition operation threads.
这一段说明了数据的序列化方式和启用的线程。Hazelcast 在节点间传递数据有2种序列化方式,在后续的文章中会详细介绍。Hazelcast 会控制多个线程执行不同的工作,有负责维持节点连接的、有负责数据分区管理的。
class: com.hazelcast.instance.Node
info: [192.168.197.54]:5701 [dev] [3.6.2] Creating MulticastJoiner
class: com.hazelcast.core.LifecycleService
info: [192.168.197.54]:5701 [dev] [3.6.2] Address[192.168.197.54]:5701 is STARTING
class: com.hazelcast.nio.tcp.nonblocking.NonBlockingIOThreadingModel
info: [192.168.197.54]:5701 [dev] [3.6.2] TcpIpConnectionManager configured with Non Blocking IO-threading model: 3 input threads and 3 output threads
class: com.hazelcast.cluster.impl.MulticastJoiner
info: [192.168.197.54]:5701 [dev] [3.6.2]
上面这一段输出中,Creating MulticastJoiner表示使用组播协议来组建集群。还创建了6个用于维护非拥塞信息输出\输出。
Members [1] {
Member [192.168.197.54]:5701
Member [192.168.197.54]:5702 this
}
class: com.hazelcast.core.LifecycleService
info: [192.168.197.54]:5701 [dev] [3.6.2] Address[192.168.197.54]:5701 is STARTED
class: com.hazelcast.partition.InternalPartitionService
info: [192.168.197.54]:5701 [dev] [3.6.2] Initializing cluster partition table arrangement...
Members[2]表示当前集群只有2个节点。2个节点都在ip为192.168.197.54的这台设备上,2个节点分别占据了5701端口和5702端口。端口后面的this说明这是当前节点,而未标记this的是其他接入集群的节点。最后InternalPartitionService输出的信息表示集群初始化了“数据分片”,后面会介绍“数据分片”的概念和原理。
上面就是Hazelcast在默认情况下执行的启动过程,可以看出在初始化的过程中我们可以有针对性的修改一些Hazelcast的行为:
- 使用默认配置文档 hazelcast-default.xml 来启动集群。因此我们可以自定义这个配置文件来影响Hazelcast 的行为。
- 启用IPv4或IPv6来建立集群,因此可以知道Hazelcast集群的通信是基于TCP、UDP,需要打开socket支持集群交互。因此我们可以指定使用的通讯方案。
- Hazelcast会启动多个线程来执行不同的工作,有些负责维护数据、有些负责集群通信、有些负责一些基础操作。因此我们可以配置和管理这些线程。
- Hazelcast默认使用MulitCast(组播协议)来组建集群,因此在局域网环境他可以无需配置自己完成集群组建。因此我们可以指定使用TCP/IP或其他通讯协议。
- Hazelcast会自己探寻可以使用的端口,默认情况下会使用5700到5800间没有被占用的端口。因此我们可以配置这些端口如何使用。
- Hazelcast初始化一个名为“数据分片”的方案来管理和存储数据。因此我们可以调整和控制这些数据分片。
以上所有红色字体的部分都可以通过配置文件来影响。在后续的文章中会详细介绍相关的 配置说明(待续)。
-----------------------------------亮瞎人的分割线-----------------------------------
如果对Hazelcast的基本原理没什么兴趣,就不用向下看“运行结构“和“数据分片原理”了,直接去下一篇了解如何使用Hazelcast吧。
Hazelcast运行结构
Hazelcast的官网上列举了2种运行模式,一种是p2p(点对点)模式、一种是在点对点模式上扩展的C/S模式。下图是p2p模式的拓补结构。
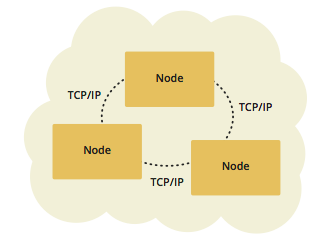
在p2p模式中,所有的节点(Node)都是集群中的服务节点,提供相同的功能和计算能力。每个节点都分担集群的总体性能,每增加一个节点都可以线性增加集群能力。
在p2p服务集群的基础上,我们可以增加许多客户端接入到集群中,这样就形成了集群的C/S模式,提供服务集群视作S端,接入的客户端视作C端。这些客户端不会分担集群的性能,但是会使用集群的各种资源。下图的结构就是客户端接入集群的情况。
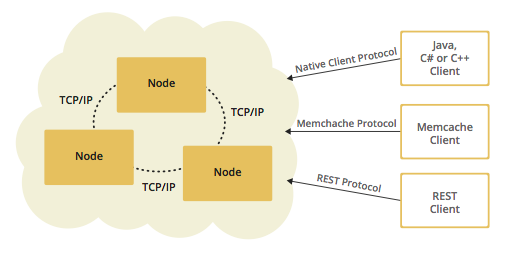
可以为客户端提供特别的缓存功能,告知集群让那些它经常要使用的数存放在“离它最近”的节点。
Hazelcast分片概念与原理
Hazelcast通过分片来存储和管理所有进入集群的数据,采用分片的方案目标是保证数据可以快速被读写、通过冗余保证数据不会因节点退出而丢失、节点可线性扩展存储能力。下面将从理论上说明Hazelcast是如何进行分片管理的。
分片
Hazelcast的每个数据分片(shards)被称为一个分区(Partitions)。分区是一些内存段,根据系统内存容量的不同,每个这样的内存段都包含了几百到几千项数据条目,默认情况下,Hazelcast会把数据划分为271个分区,并且每个分区都有一个备份副本。当启动一个集群成员时,这271个分区将会一起被启动。
下图展示了集群只有一个节点时的分区情况。
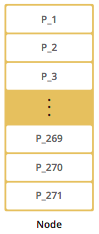
从一个节点的分区情况可以看出,当只启动一个节点时,所有的271个分区都存放在一个节点中。然后我们启动第二个节点。会出现下面这样的分区方式。
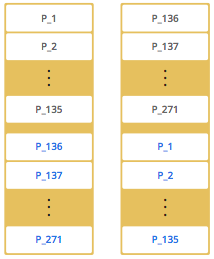
二个节点的图中,用黑色文字标记的表示主分区,用蓝色文字标记的表示复制分区(备份分区)。第一个成员有135个主分区(黑色部分),所有的这些分区都会在第二个成员中有一个副本(蓝色部分),同样的,第一个成员也会有第二个成员的数据副本。
当增加更多的成员时,Hazelcast会将主数据和备份数据一个接一个的迁移到新成员上,最终达成成员之间数据均衡且相互备份。当Hazelcast发生扩展的时候,只有最小数量的分区被移动。下图呈现了4个成员节点的分区分布情况。
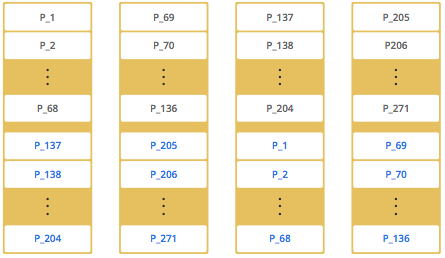
上面的几个图说明了的Hazelcast是如何执行分区的。通常情况下,分区的分布情况是无序的,他们会随机分布在集群中的各个节点中。最重要的是,Hazelcast会平均分配成员之前的分区,并均匀在的成员之间创建备份。
在Hazelcast 3.6版本中,新增了一种集群成员:“精简成员”(lite members),他的特点是不拥有任何分区。“精简成员”的目标是用于“高密度运算”任务(computationally-heavy task executions。估计是指CPU密集型运算)或者注册监听(listener) 。虽然“精简成员”没有自己的分区,但是他们同样可以访问集群中其他成员的分区。
总的来说,当集群中的节点发送变动时(进入或退出),都会导致分区在节点中移动并再平衡,以确保数据均匀存储。但若是“精简节点”的进入或退出,并不会出现重新划分分区情况,因为精简节点并不会保存任何分区。
数据分区管理
创建了分区以后,Hazelcast会将所有的数据存放到每个分区中。它通过哈希运算将数据分布到每个分区中。获取存储数据Key值(例如map)或value值(例如topic、list),然后进行以下处理:
- 将设定的key或value转换成byte[];
- 对转换后的byte[]进行哈希计算;
- 将哈希计算的结果和分区的数量(271)进行模运算(同余运算、mod运算、%运算)。
因为byte[]是和271进行同模运算,因此计算结果一定会在0~270之间,根据这个值可以指定到用于存放数据的分区。
分区表
当创建分区以后,集群中的所有成员必须知道每个分区被存储到了什么节点。因此集群还需要维护一个分区表来追踪这些信息。
当启动第一个节点时,一个分区表将随之创建。表中包含分区的ID和标记了他所属的集群节点。分区表的目标就是让集群中所有节点(包括“精简节点”)都能获取到数据存储信息,确保每个节点都知道数据在哪。集群中最老的节点(通常情况下是第一个启动的成员)定期发送分区表给所有的节点。以这种方式,当分区的所有权发生变动时,集群中的所有节点都会被通知到。分区的所有权发生变动有很多种情况,比如,新加入一个节点、或节点离开集群等。如果集群中最早启动的节点被关闭,那么随后启动的节点将会继承发送分区表的任务,继续将分区表发送给所有成员。
原文地址:https://my.oschina.net/chkui/blog/729698
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)