一个房价预测的任务,老板说你看看这个模型咋样?
我们先绘制一个坐标轴: Y 轴为房价,X 轴为年份。将过去房价数据绘制为绿色,回归模型绘制为蓝色。
关键问题是,怎么知道这个模型的好坏呢?

为了评估该模型的效果,一般会有几个指标:
一、平均绝对误差 Mean Absolute Error,MAE
平均绝对误差 MAE,也叫平均绝对离差。
这个指标在计算时,先对真实值与预测值的距离(橙色线段长度)求和,再取平均值。

用公式表示:
M
A
E
=
1
m
∑
i
=
1
m
∣
f
(
x
i
)
−
y
i
∣
MAE=\frac{1}{m}\sum_{i=1}^{m}|f(x_i)-y_i|
MAE=m1∑i=1m∣f(xi)−yi∣
其中,
-
f
(
x
i
)
f(x_i)
f(xi):预测值
-
y
i
y_i
yi:真实值
-
m
m
m:数据量
平均绝对误差可以准确地反映实际预测误差的大小,但是,MAE 有个致命的缺点。
我们现在把左边的 Y 轴缩小 1000 倍,也就是 从 1000 -> 1。
接下来,计算 MAE:
- 数据集范围大会计算获得较大的 MAE。
- 数据集范围小会计算获得较小的 MAE。

可以看到,回归模型拟合没有变化,但是MAE 会随着数据的范围有较大的变化,也就说 MAE 指标不能显示回归模型拟合是优还是劣。
二、平均绝对百分误差 Mean Absolute Percentage Error,MAPE
为了解决以上问题,**平均绝对百分误差 **对 MAE 改进后,通过计算真实值与预测的误差百分比避免了数据范围大小的影响:
M
A
P
E
=
100
m
∑
i
=
1
m
∣
y
i
−
f
(
x
i
)
y
i
∣
MAPE=\frac{100}{m}\sum_{i=1}{m}|\frac{y_i-f(x_i)}{y_i}|
MAPE=m100∑i=1m∣yiyi−f(xi)∣
该指标可以用于评估回归模型的性能优劣,常用于衡量预测准确性指标,一般 MAPE < 10 认为是较好的模型。
但是,如果真实值有 0,那么 MAPE 无法正确计算。
三、均方误差 MSE
现在对平均绝对误差求平方根,就能得到均方误差(Mean Square Error,MSE)。
这个指标在计算时,先对真实值与预测值的距离平方(橙色面积)后求和,再取平均值。

公式表示:
M
S
E
=
1
m
∑
i
=
1
m
(
f
(
x
i
)
−
y
i
)
2
MSE=\frac{1}{m}\sum_{i=1}^{m}(f(x_i)-y_i)^2
MSE=m1∑i=1m(f(xi)−yi)2
该指标避免了 MAE 的绝对值导致函数不能求导的问题,因此均方误差常用于线性回归的损失函数。
另一方面,均方误差可以通过平方来放大预测偏差较大的值,提高了检测灵敏度。
四、均方根误差 Root-Mean-Square Error,RMSE
均方根误差,也称标准误差,是在均方误差的基础上进行开方运算,常用于衡量观测值与真实值间的偏差。
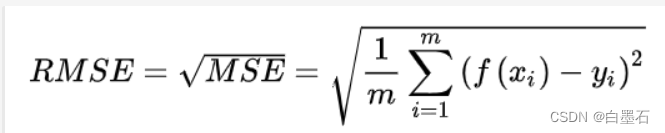
以上提到的 MAE、MSE、MAPE,RMSE 都会计算均值,它可以消除样本数量对评价指标的影响,使得评估指标的大小不会太依赖于样本数量,而是更多地反映模型的误差。
五、决定系数
R
2
S
c
o
r
e
R^2 Score
R2Score
该指标需要了解另外三个指标:
Sum of Squares of the Regression,SSR
计算预测数据与真实数据均值之差的平方和,反映的是模型数据相对真实数据均值的离散程度。
S
S
R
=
∑
i
=
1
m
(
f
(
x
i
)
−
y
‾
)
2
SSR=\sum_{i=1}^{m}(f(x_i)-\overline y)^2
SSR=∑i=1m(f(xi)−y)2
Total Sum of Squares,SST
计算真实数据和其均值之差的平方和,反映的是真实数据相对均值的离散程度。
S
S
T
=
∑
i
=
1
m
(
y
i
−
y
‾
)
2
SST=\sum_{i=1}^{m}(y_i-\overline y)^2
SST=∑i=1m(yi−y)2
Sum of Squares for Error,SSE
真实数据和预测数据之差的平方和
S
S
E
=
∑
i
=
1
m
(
f
(
x
i
)
−
y
i
)
2
SSE=\sum_{i=1}^{m}(f(x_i)-y_i)^2
SSE=∑i=1m(f(xi)−yi)2
细心的小伙伴可能注意到,SST = SSR + SSE

决定系数
R
2
R^2
R2
决定系数
R
2
R^2
R2通过计算SSR 与 SST的比值,反应因变量 y 的全部变异能通过回归模型被自变量 x 解释的比例。比如,
R
2
R^2
R2为0.9,则表示回归关系可以解释因变量 90% 的变异。
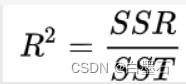
- 决定系数R2越高,越接近于1,模型的拟合效果就越好
- 决定系数R2越接近于0,回归直线拟合效果越差。
R
2
R^2
R2虽然可以评价回归模型效果,但会随着自变量数量的不断增加而改变。
六、校正决定系数
校正决定系数在决定系数R平方的基础上考虑了样本数量和特征数量的影响。自变量越多,校正决定系数就会对自变量进行处罚,所以一般校正决定系数小于决定系数。
R
‾
2
=
1
−
(
1
−
R
2
)
(
m
−
1
)
m
−
n
−
1
\overline R^2 = 1- \frac{(1-R^2)(m-1)}{m-n-1}
R2=1−m−n−1(1−R2)(m−1)
其中,
需要注意的是,决定系数和矫正决定系数都是基于均值进行计算,如果数据集中有异常点存在,会对该指标有较大的影响。也就是说,这两个指标对异常点较敏感,因此它们更适用于噪声较少的数据集。
对于噪声较多的数据集可以考虑 MAE,MAPE 来作为评估指标。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)