现在Intel已然成了CPU的代名词,但当年的Intel并没有现在这么风光。从1978年发布的8086到2013年的四代i7,整整35年,她见证了从PC到互联网、移动互联网的几次巨变;这些年的变化实在太多。本文不打算对这段历史及引领这段历史的风云人物做多少描述和评价(这些内容足够写好几本书的了),你若对这些内容更感兴趣,请移步。本文只对Intel CPU家族中几位名声显赫的人物做简要介绍,并对比他们区别。
简要历史
接下来,对Intel的几个划时代的CPU产品做简要介绍。
Intel ® 8086(16位,1978年)
这是一款1978年发布的CPU产品,算得上是Intel家族的长老了。20世纪70年代的东西了,为什么要介绍它呢?因为我和很多同学一样,大学还要学这种古老的东西。我上这门课的时候就在想为什么要学这么老的东西呢?后来查了Intel的其他CPU才知道,越往后的CPU越强大,当然也越复杂,一个学期也学不完;当然这些都是后话了。
在8086之前,还有一款小有名气8位的CPU产品——8088,但它对后来产品的影响远没有8086大,所以本文就不介绍他了。
来瞻仰一下8086的“新特性”吧:

看看几个“值得一提”的:
- 直接内存寻址能力达1MB
- 时钟频率为5M, 8M, 10MHz
- 最后一个说的是:有40引脚陶瓷和塑料两种封装
最后一段的最后一句值得注意的是:8086可以通过多个处理器来实现高性能。
IA-32系列架构发展自8086这样的16位处理器。8086有16位的寄存器,16位的外部数据总线,和20位数据总线,它提供了1M字节的寻址能力,1M=2^20。
8086将“段”的概念引入了IA-32架构。由于段的引入,一个16位的段寄存器容纳了一个指向64K字节内存的指针。20位地址可以经由一个段寄存器和一个附加的16位指针,来提供1M字节的寻址能力。
Intel ® 286 处理器 (1982)
Intel286处理器将“保护模式”引入了IA-32。保护模式使用段寄存器的内容作为选择器或指向描述符(descriptor)表格的指针指针。Descriptor提供了24位基地址,使得物理内存寻址能力提高到了16M字节(16M=2^24),并支持了基于段交换的虚拟内存管理,以及一些列的保护机制。这些机制包括:
时钟频率由6MHz到20MHz。
The Intel386™ Processor (1985)
Intel386处理器是IA-32架构家族的第一个32位处理器。它包括即可存放操作数也可用于寻址的32位寄存器。每个32位寄存器的低半截保留有此前系列的16位寄存器的功能,允许后向兼容(兼容过去的可执行代码)。该处理器同时提供了虚拟8086模式,以允许有效地执行为8086/8088创建的程序。
另外,Intel386处理器还支持:
- 32位的地址总线,最高支持4G物理内存
- 分段(segmented)内存模式和平坦(flat)内存模式
- 分页,大小固定为4k的页提供了一种“虚拟内存管理”的方法
- 支持parallel stages(应该指的是指令执行几个阶段可以并行)
时钟频率为12.5MHz
Intel ® 486™ 处理器 (1989)
Intel486处理器通过扩展386处理器的指令译码器(instruction decode)和执行单元(execution uint)为5个排队阶段(pipelined stage)提升了指令的执行能力。每个阶段的操作与其他指令的不同阶段是同时执行的。
另外,该处理器还引入了:
- 8k片上一级缓存,它提升了单位时间的指令执行数量。
- 集成的x87浮点计算单元(FPU)
- 省电模式和系统管理能力
时钟频率从25M到50M.
Intel® Pentium® 处理器 (1993)
因特尔奔腾处理器加入了第二个执行管线(pipeline),以实现更强劲的性能(两个管线,广为人知的u和v管线,可以在同一个时钟周期执行两个指令)。片上一级缓存加倍(16K),8k用来缓存代码,8k用来缓存数据。数据缓存通过Intel486处理器使用MESI协议来支持更高效的缓存回写。一个片上分支表和被加入,以提升循环的执行性能。
另外,该处理器加入了:
- 一些扩展使得虚拟8086模式更有效率,且允许4M字节或4K字节分页
- 128位和256位的内部数据路径用于提示内部的数据传递
- 可增强的外部数据总线增加到了64位
- APIC( Advanced Programmable Interrupt Controller,高级可编程中断控制器),以支持系统可以使用多核
- 双核模式,以支持无需胶合(外部控制器协调)的双核系统
另一个重要的阶段性的成果是奔腾家族引入了Intel MMX技术,Intel MMX技术使用单指令多数据(single-instruction multiple-data, SIMD)执行模式来在打包的64为寄存器上实现平行计算。
时钟频率由最初的60Mhz和66Mhz到后来的200MHz
Intel® Pentium® 4 Processor Family (2000-2006)
PS:这六年对于CPU的世界来说,变换是在太快,“日新月异”似乎已经不足以描述这几年CPU的巨变了。
Intel奔腾4处理器家族是基于Intel NetBurst 微架构的。奔腾4处理器引入了SSME2(Streaming SIMD Extension 2)。
奔腾4处理器具有3.4GHz主频,支持超线程技术(Hyper-Threading Technology)。
Intel 64架构是在奔腾4处理器 6xx和5xx系列中引入的。
Intel® Virtualization Technology (Intel® VT) 是在 Pentium 4 处理器 672 和 662 引入的.
奔4系列已经接近了CPU主频技术的极限,它让当年的“摩尔定律”不再有用。
下面的这些,我只作一些简要描述。
Intel® Xeon® Processor (2001- 2007)
Intel至强系列,该家族最初为IA32架构,后来的产品多采用Intel64了,该家族是被设计用于多核高性能的服务器和工作站的。
Intel® Core™ Duo and Intel® Core™ Solo Processors (2006-2007)
这个系列是Intel的被设计为低功耗的CPU产品,主要用于当时的笔记本电脑(当时笔记本市场增长很快,大有取代PC之势)。
Intel® Xeon® Processor 5200, 5400, 7400 Series and Intel® Core™2 Processor Family (2007)
至强的新系列产品,依旧是“高大上”的服务端路线,基于45nm的新架构。
Intel® Atom™ Processor Family (2008)
Atom架构,45nm科技,也是被设计于低功耗,最要用于移动设备(手机、平板等)。当时正是的智能机抬头的时机,虽然市场的老大是诺基亚(S60已经号称智能手机了)。
Intel® Core™i7 Processor Family (2008)
Nehalem架构,45nm。与Atom同时的产品时酷睿i系列,这也算的上是“家喻户晓”的产品了。
Intel® Xeon® Processor 7500 Series (2010)
Nehalem架构,45nm。继续高大上。
Second Generation Intel® Core™ Processor Family (2011)
Sandy Bridge架构,32nm。二代酷睿i系列,我现在用的i2410正是这个这个系列的。
Third Generation Intel® Core™ Processor Family (2012)
Ivy Bridge架构,以及有些的Ivy Bridge-EP架构。
Fourth Generation Intel® Core™ Processor Family (2013)
Haswell架构。
“三个代表”
这里需要指出三个机具代表性的CPU,他们是8086,386(IA32)和酷睿i7(Intel64)。
8086CPU架构
8086相对后来的CPU要简单得多,这也是为什么教材喜欢拿他说事的原因。来让我一睹8086的架构吧(左图)。和架构紧密相关的是它的引脚封装,没错,他和51单片机的40-pin封装长得一样(右图)。

基本执行环境
对于我等程序猿来说,架构和封装都不是我们关心的;我们只关心我们的代码。直到现在,和具体CPU相关的代码仍要用汇编语言编写;自然要关心的是寄存器了;在上面8086
的架构图(左图)中可以看到的有段寄存器(Segment register)和指令指针(instruction pointer)。
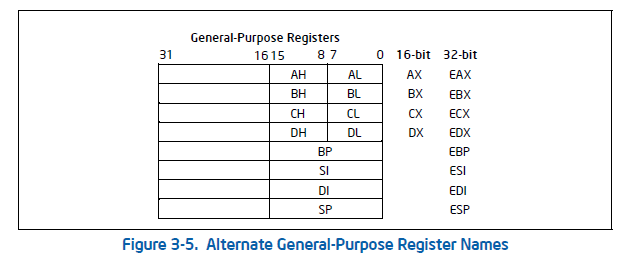
8086的寄存器很少,少到一张图就可以概括所有寄存器:

其中IP是指令指针,FLAGS为机器状态字。其中CS,DS,SS,ES为四个段寄存器;SP和BP为数据指针(data pointer),SI和DI为索引寄存器(Index register)。
IA32的寄存器则要多一些:

因为,它除了基本执行环节外,还内置了FPU(浮点计算单元),MMX(多媒体增强)和XMM(与SSE有关)。
IA32的指令指针和机器状态字分别叫做EIP和EFLAGS。
其中,
8个32为寄存器为:EAX, EBX, ECX, EDX, ESI, EDI, EBP, ESP
6个段寄存器为:CS, DS, SS, ES, FS, GS

而Intel 64执行环境则与IA32环境类似:

Intel 64的通用寄存器增加到了16个,分别为:RAX, RBX, RCX, RDX, RSI, RDI, RSP, RBP, R8~R15
兼容性
IA32可以与8086兼容,是的8086的程序能够在IA32上运行,这依赖于寄存器和指令上的兼容。这在当时为Intel赢得了很好的市场,试想,如果当时386不兼容Dos,估计也不会有今天的微软了吧。
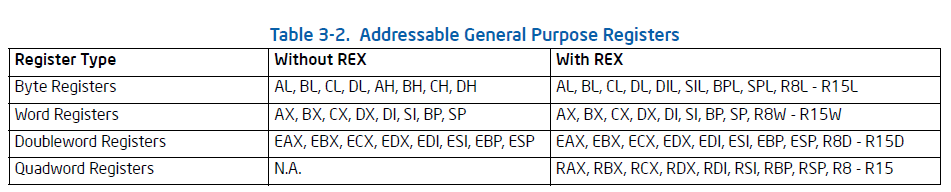
同样Intel 64也兼容IA32,下面是一个对照表:
内存模型
接下来,简要介绍8086,IA-32和Intel 64的内存模型。
8086的有20位地址总线,但寄存器是16位的,这似乎必然导致了分段内存模型。代码段寄存器(CS)和指令指针(IP)指向当前正在执行的代码;数据段寄存器(DS)或其他段寄存器与索引寄存器联合用于定位内存中的数据。
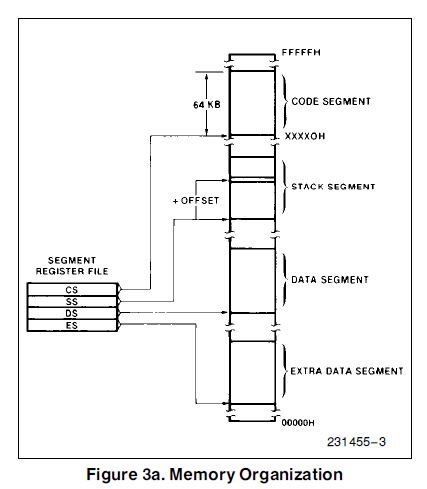
IA32 内存模型
IA32时代,虚拟内存技术已经得到了CPU的支持,这是出现了三种内存模型:
平坦内存模型, 内存表现为单一的连续的地址空间,这种地址空间也叫线性地址空间。
分段内存模型,内存表现为一系列独立的被成为段的地址空间,代码段、数据段、栈(stack)段是典型的独立的段。程序使用逻辑地址寻址一个字节。系统所有段都会被映射到处理器的线性地址空间,处理器负责逻辑地址和线性地址的互相转换。这种转换对于应用程序来说是透明的。
实地址模式,这种地址模式是用于Intel 8086处理器的。它是为了使得程序可以运行在8086处理器上。
几种模式的示意图如下所示:

分页与虚拟内存
在平坦和分段内存模型中,线性地址空间被直接(或分页)映射到处理器的物理地址空间。
当使用直接映射(关闭分页),每个先行地址都有一个一对一的物理地址与之对应。线性地址直接由处理器的地址总线送出,不需任何转换。
当使用IA-32架构的分页机制(打开分页)时,线性地址空间被划分为一系列的页并被映射为虚拟地址,随后虚拟内存的页会按照需要映射相应的物理内存。当操作系统或可执行程序使用页时,分页机制对于应用程序来说是透明的。所有的应用程序看的都是线性地址空间。
另外,IA-32的分页机制包括一些扩展功能:
- 物理地址扩展(PAE,Physical Address Extensions)用于寻址超出4G的地址
- 页面大小扩展(PSE,Page Size Extensions)用于将4M字节的线性地址页映射到物理地址。
扩展阅读
本文只是Intel系列CPU的一个概要(或简介),更多细节内容请阅读Intel的开发者手册【3】。
【1】CPU的发展历程:Intel(英特尔公司),http://web.gxmu.edu.cn/zz/Article/ShowArticle.asp?ArticleID=76
【2】Intel 8086 6-BIT HMOS MICROPROCESSOR 8086/8086-2/8086-1,http://download.csdn.net/detail/xusiwei1236/8373939
【3】Intel® 64 and IA-32 Architectures Software Developer’s Manual,http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
转载:
http://blog.csdn.net/xusiwei1236/article/details/42784539
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)