这篇文章是韩国的一个组做的,一直没中, 直到19年中了ICCV,据说是第一篇将元学习引入目标跟踪的文章,用的架构是siamese网络的架构,但是在模型在线更新的时候使用了meta-learning的思想。
Motivation
- the number of positive samples are highly limited.
- overfitting
在跟踪过程中,当目标外观发生变化时,需要对模型进行更新。而更新操作需要采用stochastic gradient descent (SGD)随机梯度下降,Lagrange multipliers , ridge regressio等方法,效率很低,通常低于20FPS,无法满足实时性需求。此外,更新通常是利用跟踪过程中等少量目标外观模型(a handful of target appearance templates obtained in the course of tracking)来进行的,由于正样本不足,所以模型很容易陷入过拟合(overfitting)而失去泛化能力。
Introduction
本文基于以上背景和动机,提出了一种 end to end visual tracking network structure,主要包括了两个部分
- Siamese matching network for target search
- meta-learning network for adaptive feature space.
在跟踪算法SiameseFc基础上,这里简称matching network,添加了meta-learner network,在运行时动态产生部分matching network的参数。利用meta-learner network,能够使matching network适应目标外形变化,而且对matching network动态新增的参数,也只需要计算forward-pass就可以,因此,实时效果好,达到了48fps,整体流程如下图如所示:
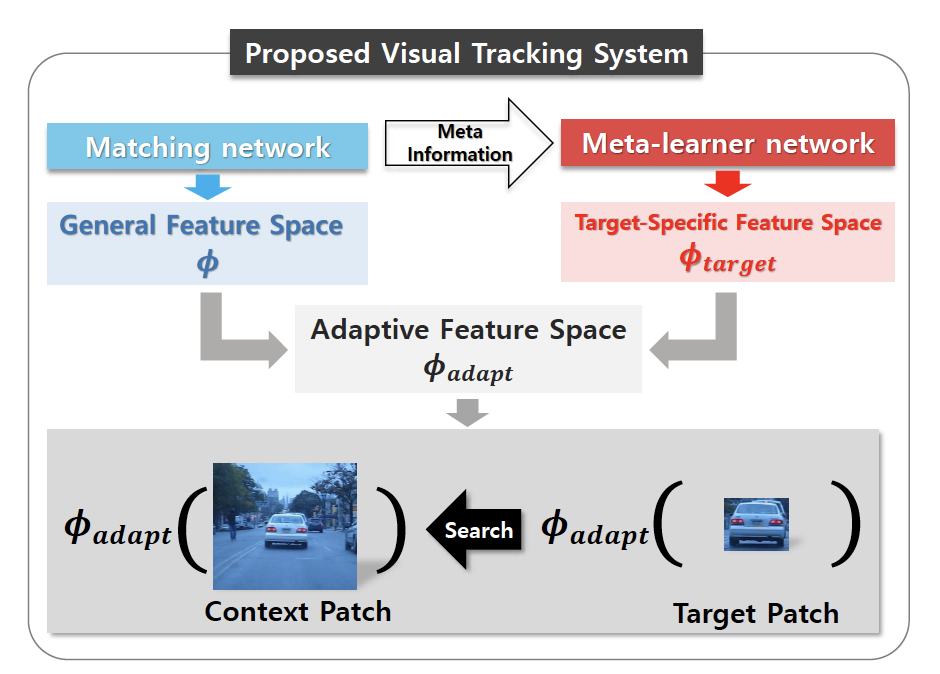
训练后的元学习网络为matching network(本文中就是SiameseFC网络)提供了额外的卷积核和channel attention information,从而让特征空间(feature space)可以根据追踪过程中获得的新的外观模版(new appearance templates obtained in the course of tracking)进行自适应修改,而不会产生过拟合情况。
Meta-learning
简单来说就是像人一样在学习了很多个task之后,但面对新的task时能够借助以往的学习知识以及少量的新样本快速地适应到新的任务上,就像我们玩lol玩的很好,那么上手王者荣耀是一个道理。
其实meta-learning这个概念很早就提出,只是目前将其应用于深度学习和强化学习领域做出了一些效果,或提高性能,或提高训练效率。目前对meta-learning的理解,可以简单理解为learning to learn,换句话解释就是要去学习超参,那对超参的定义可以理解为设计算法时不是由data-driven的部分,可以是模型结构,可以是训练参数,也可以是根据情况动态修改模型结构等。总之,meta-learning就是要学习并替代设计算法时人的工作。
本文中的meta-learning其实应用主要是应用了meta-learning的思想,使用meta-learning来更新最后一层卷积层(conv5)的weight。使之产生一个可以根据现有追踪模版自适应更新的权值,然后把原始的权重和meta-learning网络生成的权值合并,生成最后的W adapt。
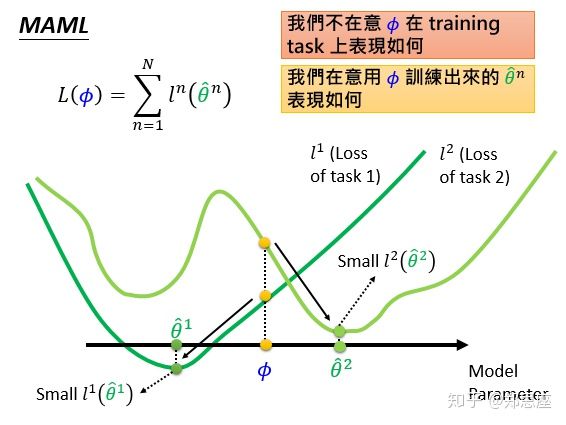
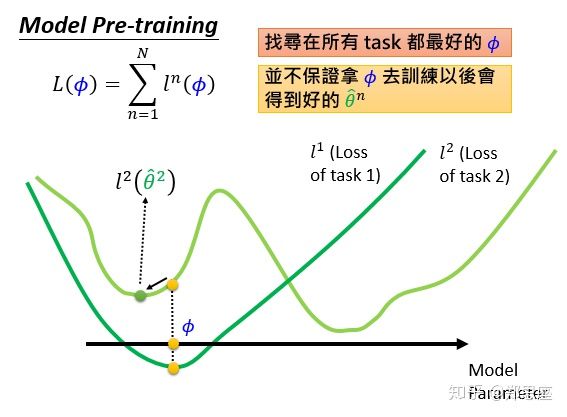
这里分享一下我看的李宏毅老师的机器学习讲meta-learning相关的一些小知识,就是在meta-learning网络训练的时候,并不追求单一任务上的最优,而是去寻找可以让所有task都能下降到分别的全局最优。就像下面这两张图。
SiameseFc
SiameseFc跟踪算法,没有采用更新model或者维护template,而是使用两个全卷积cnn组成Simaese network,提取卷积层特征做相关,产生heatmap来预测目标位置,如下图所示。两个网络中,一个输入是起始帧的目标模板,另一个输入是目标附近更大范围的区域(一般可以设为4倍,相当于搜索区域)。
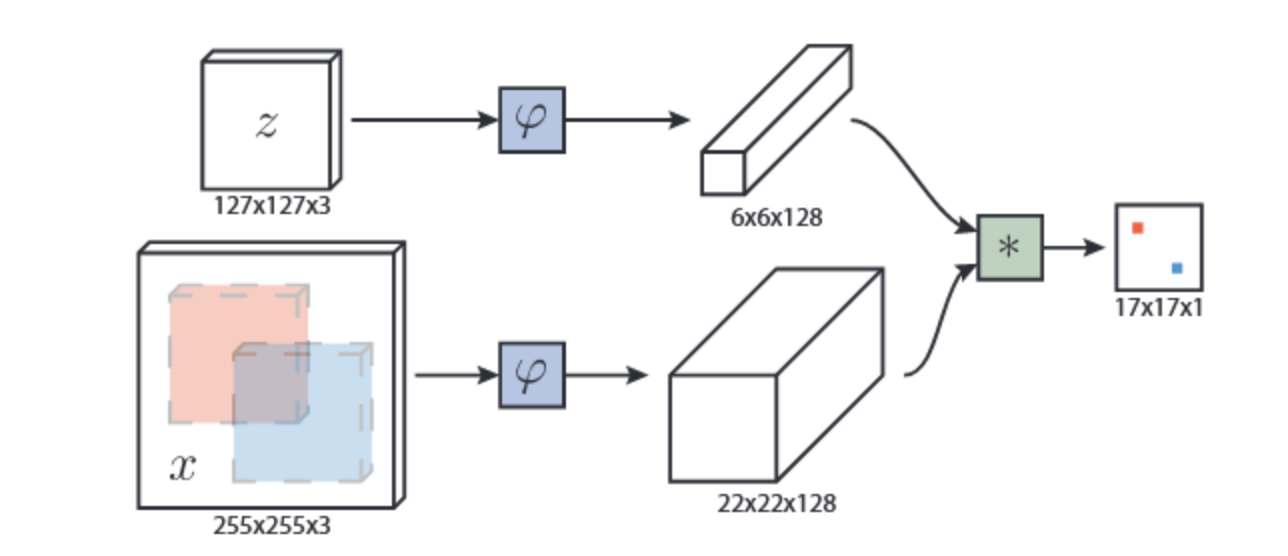
上图中可以看出其核心计算公式:
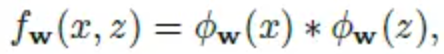
网络的损失函数如下式所示,y[u]表示真实标签,其定位目标框内为1,框外为-1:
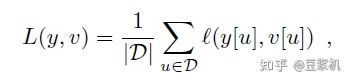
好了 让我们开始正文吧!
Algorithm
文章的网络结构如下:
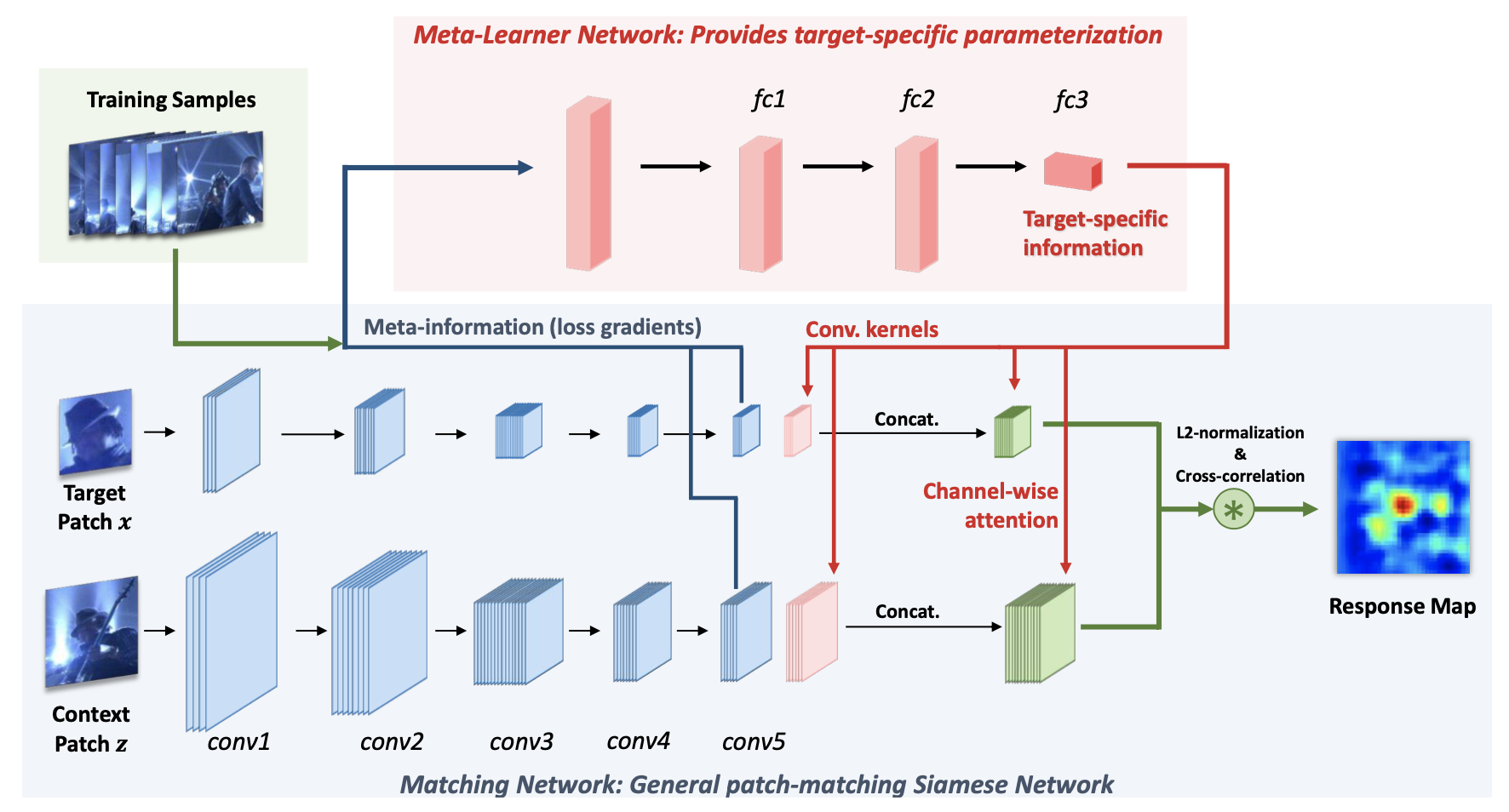
蓝色的就是SiamFC的结构, 文章是提特征, 然后用conv5的特征算一个loss, 然后把梯度给Meta-learner这个网络, 去算一个权重出来, 还算了一个attention, 再把权重concate到原始conv5的weight上面, 然后用这个新的weight来计算最终的features, 在这两个feature上做互相关.
Components
首先我们来看蓝色的部分,实际上就是一个SiameseFc网络,使用具有5个卷积层的CNN,并在前两个卷积层之后应用2个内核大小为3和步幅为2的池化层。在每个卷积层之后插入批处理归一化层(Batch normalization layer)。
CNN的每层的内核大小和输入/输出尺寸为w1:11×11×3×128,w2:5×5×128×256,w3:3×3 ×256×384,w4:3×3×384×256,w5:1×1×256×192。对于输入,为x使用大小为127×127×3的RGB图像,为z使用大小为255×255×3的RGB图像,匹配网络生成大小为17×17的响应图。
实际上就是先做卷积,然后再求互相关:
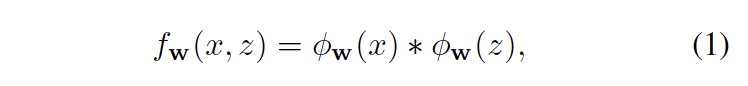
式中 x为模版,z为搜索区域,w = {w1,w2, …,wN}表示每一层的一组权重,ϕw(⋅)表示整个网络权重为 w 时的使用Nlayer 特征提取器提取出的特征。
meta-learner network根据matching network在之前追踪过程中产生的M个context patches z = {z1, …, zM}以及target x,来计算能够使追踪模版自适应更新的新增参数。
首先使用matching network最后一层conv5来计算平均负梯度:
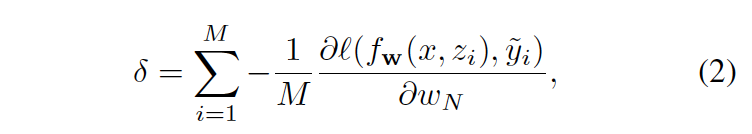
其中 yi表示根据ground-truth来计算出针对zi的二值标签图,也就是响应图(response map。meta-leaner设计的依据是目标发生变化,那么δ也发生变化(the characteristic of δ is empirically different according to a target)
然后,以δ作为输入,meta-learner 网络 g(·)可以生成与输入对应的目标特定权重(target-specific weights),如下:
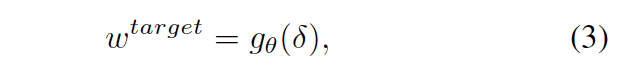
然后将两个权重拼接起来就来更新matching network原始的权重
这里插一嘴,上面所说的拼接是真的拼接,就是简单相加,这一点可以在后文中介绍meta-learner网络中得到印证
[w5,wtarget] of size 1×1×256×(192+32).
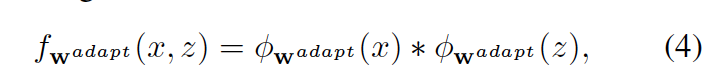
论文还说这里同时生成了一个channel-wise sig- moid attention weights这样的权重,文中也没有讲具体实现,同时我在后文中也没有看到如何使用
Tracking algorithm
对于跟踪过程,首先保存K个context images as zmem = {z1 , …, zK },以及对应的响应图 yˆ = {yˆ ,…,yˆK}.保存的原则是, 当在每一帧找出target之后, 会判断当前这个target的响应是否大于一个阈值 τ , 若是大于 τ , 便把这个patch加入到template的池中:
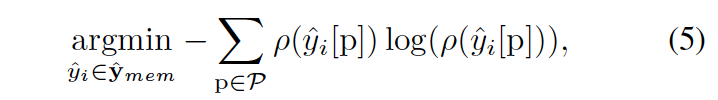
式子中的p对应于响应图中所有可能位置P的集合中的位置,而ρ(·)是归一化函数。
而在接下来计算要输入meta-learner网络的δ时,从template池中选择熵最小的,其实就是找响应比较大, 比较靠谱那M个template用来更新网络。
文章中提到,这里提出了一个新的响应图yˆ ⊗ h,加入了一个余弦窗函数,这个h就是余弦窗函数,用来惩罚大位移,保证目标大小平滑变化。
整个跟踪流程如下:

Implementation and Training
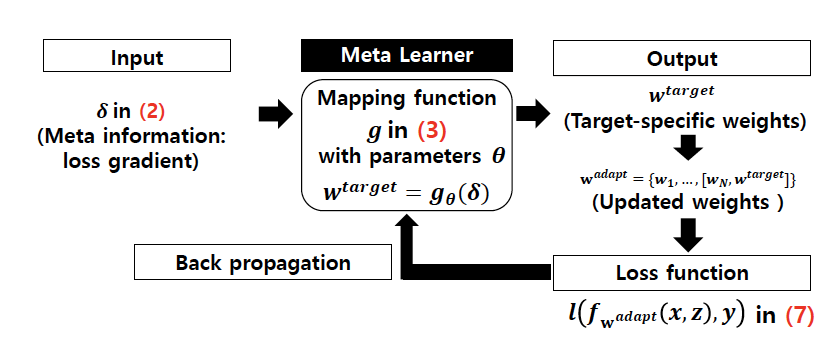
meta-learner网络使用(2)中的损失梯度δ作为输入,该信息是从matching network中获得的,它解释了其在当前特征空间中的状态。然后,meta-learner 网络中的g(·)学习从该损失梯度到自适应权重Wtarget的映射,该权重描述目标特定的特征空间,也就是所谓的目标特定权重(target-specific weights)。可以通过损失函数来训练元学习器网络,该函数可以衡量自适应权重Wtarget在正确拟合新示例{z1,…,zM’}时的准确度。
Matching Network
Network
5 convolutional layers
2 pooling layers of kernel size 3 and stride 2 are applied after the first two convolutional layers.
w1 : 11×11×3×128,
w2 : 5×5×128×256,
w3 : 3×3×256×384,
w4 : 3×3×384×256,
w5 : 1×1×256×192.
Inputs,
27×127×3 for x
255×255×3 for z
response map
17 × 17
Train
在训练时,对(x,z)从选定的视频序列中的目标轨迹中随机采样。然后,生成ground-truth响应映射y∈{−1,+1}17×17,其中值在目标位置为+1,否则为- 1。对于损失函数l(fw(x, z), y),文章使用logistic损失函数定义为:
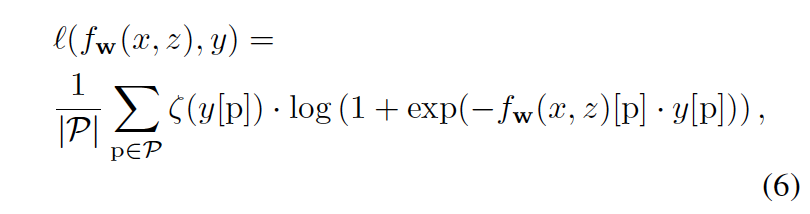
式中,p表示响应图中每个可能位置P的集合中的一个位置,而ζ(y [p])是减轻标签不平衡的加权函数。
损失函数使用Adam优化器进行了优化,使用批处理大小为8的学习率为10−4,并运行95000次迭代。
Meta-learner Network
Network
3 fully-connected layers
Each intermediate layer is followed by a dropout layer with the keep probability of 0.7 when training.
For input, gradient δ of size
1×1×256×192
output Wtarget of size
1×1×256×32
合并之后的权重 [w5,wtarget]
1×1×256×(192+32)
Train
训练的时候从一个训练序列中随机抽取M′个(M′≥M)context patch,也就是Zreg ={z1,…,zM′}然后从中取M个来计算梯度δ。接着利用公式2,来计算响应二值图。注意,这里的计算二值图,是在假定目标位于中心来进行计算的(assuming the target is located at the center i
of zi)。这样做的目的就是在于我前面提到的,训练meta-learner network并不追求单一任务上的最优,而是去寻找可以让所有task都能下降到分别的全局最优,所以这里假设目标在context patch的中心,这样不管目标去哪里,我们的x都能很快的响应。
meta-learner network的损失函数,针对meta-learne network进行最优化,matching network固定不变,如下式所示,
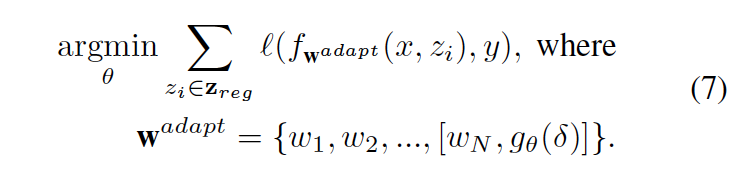
Experimental Results
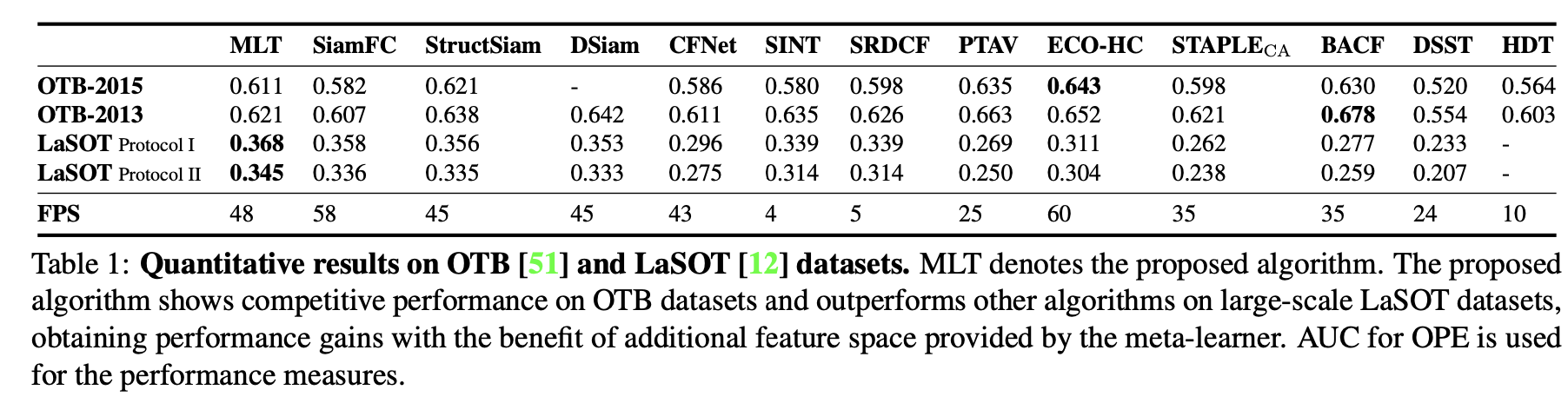
OTB[51]和LaSOT[12]数据集的定量结果。MLT为提出的算法。该算法在OTB数据集上表现出了较好的性能,在大规模LaSOT数据集上表现优于其他算法,并利用元学习器提供的额外特征空间获得了性能提升。
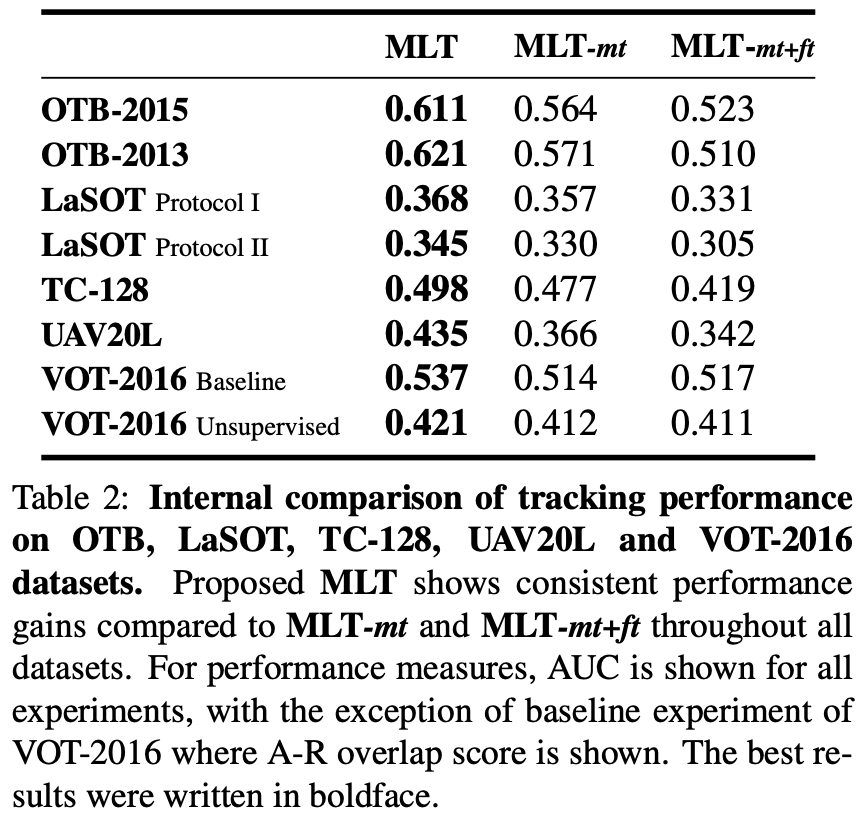
MLT-mt 只加入了meta-learner
MLT-mt-ft 加入了Adam优化器进行finetuning
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)