在一组平行测定中,若有个别数据与平均值差别较大,则把此数据视为可疑值,也称离群值。 如果统计学上认为应该舍弃的数据留用了,势必会影响其平均值的可靠性。相反,本应该留用的数 据被舍弃,虽然精密度提高,但却夸大了平均值的可靠性。
1 离群值检验方法简介
设有一组正态样本的观测值,按其大小顺序排列为x1,x2,x3,……,xn。其中最小值x1或最大值xn为离群值(xout)。对于离群值的统计检验,大都是建立在被检测的总体服从正态分布。基于此,在给定的检出水平或显著水平α (通常取值为0.05和0.01)和样本容量n条件下,可查表获得临界值,再通过计算统计量后与临界值比较,若统计量大于临界值就判为异常。临界值表通常给出的是置信度P,对双侧检验而言,P = 1 - α/2;对单侧检验而言,P = 1 - α。
1.1 标准偏差已知情况
采用奈尔检验法(样本容量3 ≤ n ≤ 100),根据下式计算统计量Rn。

1.2 标准偏差未知情况(离群值数量为1时)
更多情况下,数据的标准偏差是未知的,此时可采用的检验离群值的方法较多,本文仅给出较为常用的几种方法。
1.2.1 拉依达法

其中s表示标准偏差。当所要检测的离群值满足上述条件时,判定为异常值,否则未发现异常值。
1.2.2 4d检验法

其中x¯和d¯分别表示去掉离群值后其余数据的平均值和平均偏差。当所要检测的离群值满足上述条件时,判定为异常值,否则未发现异常值。
1.2.3 肖维勒(Chauvenet)法

按上式计算出统计量ωn,根据测定次数n查肖维勒系数表值ω(n)。当ωn > ω(n),判定为异常值,否则未发现异常值。
1.2.4 t检验法

其中s和x¯都是由不包括离群值的n - 1个数据计算所得。查t检验的临界值表值kP(n),当kn > kP(n),判定为异常值,否则未发现异常值。
1.2.5 格鲁布斯(Grubbs)检验法

查格鲁布斯检验的临界值表值GP(n),当Gn > GP(n),判定为异常值,否则未发现异常值。
1.2.6 狄克逊(Dixon)检验法(样本容量3 ≤ n ≤ 30)
此法由Dixon [8]在1950年提出,它的原理是通过离群值与临近值的差值与极差的比值(ratios of ranges and subranges)这一统计量rij来判断是否存在异常值。由于样本容量大小的不同会影响检验法的准确度,因此根据样本容量的不同,统计量的计算公式不同,具体见表1。

判断离群值是最大值还是最小值,再根据样本容量n代入对应的统计量计算公式,求出统计值rij (或rij')。确定检出水平α,查狄克逊检验的临界值表值DP(n)。当rij (或rij') > DP(n),判定为异常值,否则未发现异常值。
1.2.7 Q检验法
Dixon在提出了1.2.6的检验方法之后,于1951年与Dean合作提出了一种针对样本容量较小(n < 10)的简化的离群值检验方法[9],即为著名的Q检验法(Dixon’s Q test)。此法为国内外分析化学教材普遍长期采用。统计量Q值的计算极为简单,即用可疑值与其最邻近值之差(xn - xn-1)或(x2 - x1),除以极差(xn - x1):

根据测定的次数和给定的置信度查临界值表值QP(n),若Q1 (或Qn) > QP(n)则为异常值,否则未发现异常值。由此可见,Q检验法类似r10时的狄克逊检验法。
1.3 标准偏差未知情况(离群值数量大于1时)
1.3.1 偏度-峰度检验法
偏度检验法适用于离群值出现在单侧的情形。
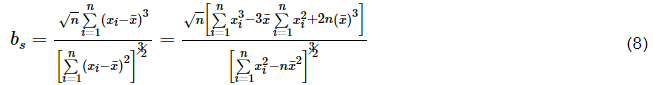
式中样本从小到大排列后的第i个数据称之为xi。
确定检出水平α,查偏度检验的临界值表值bP(n),当bs > bP(n),判定为异常值,否则未发现异常值。当存在有多个离群值时,先选择最内侧的离群值进行检验。例如,当存在有两个上侧离群值xn、xn-1,暂时去除xn,测量次数减1,检验xn-1是否为异常值。若不为异常值,测量次数为n,再检测xn是否为异常值。若xn-1为异常值,xn自然也就舍弃了。
峰度检验法适用于双侧情形。

确定检出水平α,查峰度检验的临界值表值bp'(n)。当bk > bp'(n),判定离均值x¯x¯最远的值为异常值,去除异常值后,重复峰度检验法检验是否仍然存在异常值,否则未发现异常值。
1.3.2 狄克逊(Dixon)检验法
原理见1.2.6,离群值在同一侧时,同偏度检验法的原理。离群值在不同侧时,先检验偏离更远的离群值。例如,存在两个位于不同侧的离群值时,计算两个离群值的rij (或rij'),先检验rij (或rij')数值较大的离群值,若未判定为异常值,那么另一离群值也自然被保留。若判定为异常值,测定次数相应减1,检验rij(或rij')更小的离群值。
1.3.3 格鲁布斯(Grubbs)检验法
原理见1.2.5,离群值在同一侧时,同偏度检验法的原理。离群值在不同侧时,先检验Gn较大的离群值。例如,存在两个位于不同侧的离群值时,检验Gn较大的离群值,若未判定为异常值,另一离群值也自然被保留。若判定为异常值,测定次数相应减1,检验Gn更小的离群值。
1.4 方法对比
为了比较上述列举的几种方法的差别,以便更好地说明各种方法的优缺点,我们将上述列举的几种方法从是否考虑了平均值、标准偏差、平均偏差、极差、测定次数、置信度这几个方面进行了比较(表2)。

根据正态分布规律,偏差超过3σ的概率小于0.3%,当测定次数不多时,这样的数据可认为异常而舍去。对于实际工作中样本的有限次测量,由于无法得到总体标准偏差σ,因此拉依达法用s代替σ;而统计学证明d¯d¯,即4d¯d¯≈8σ,此为4d法的依据。两种方法都进行了一定的近似处理,且依据的关系式在测定次数大于20时才能够比较好的成立,用来判断样本容量不大的可疑值取舍时存在较大误差。由于方法简单,不需要查表,因此它们在某些场合仍有所应用。另外,拉依达法相对4d法有更高的灵敏度,因为相较于平均偏差,标准偏差能够更灵敏地反映出较大偏差数据的存在,但是也有可能造成前者对于非异常极值的错误舍弃。
对于肖维勒法、t检验法和格鲁布斯法,其统计量的计算公式形式相同,但是肖维勒法的根据是将出现概率小于1/2n的数据点判定为异常值,故样本容量对置信区间的选择有一定的限制,而另外两种方法中的置信度都可以自由选择和查表。相对于肖维勒法和格鲁布斯法中采用所有数据进行计算x¯x¯和s,在t检验法中计算x¯x¯和s时要除去离群值。除去离群值的做法可以提高s的正确性和独立性,从而提高方法的精确度和灵敏度,但是也有可能造成s偏小而剔除非异常极值。
表2最后两种方法中Q检验法可认为是狄克逊检验法在样本容量n < 10时的简化处理。狄克逊检验法的处理则较为繁琐,不仅统计量的计算公式因样本容量的大小而异,且对单侧和双侧检验,其临界值表也各不相同。
2 数据误判讨论
在实际处理过程中,误判问题是不可避免的,我们只能通过选择恰当的方法尽量降低误判发生的几率。误判问题存在有两种,一种为以假当真,一种以真当假。以假为真是将异常值错误地保留下来,以假当真的例子:Q检验法的判断公式受离群值的影响较大,可能将异常值判断成非异常值。另外,离群值的数量超过1时,会使得计算的标准偏差、平均值都受到影响,可能将离群值判定为非异常值。以真为假是将非异常值错误地剔除,以真当假的例子:在t检验法中处理数据时,预先“剔除”了被检验的离群值,这可能导致计算出来的标准偏差较小,从而使得一些位于界限处的离群值被错误地判断为异常值。为了更好说明以上内容,笔者将对以下三个实例进行分析。
例1
不同的离群值检验方法可能会有不同的结果,我们通过一个实例来分析一下几种方法之间的差异。选用了三种方法,分别是格鲁布斯法、狄克逊法、拉依达法,选用这三种方法比较的原因是格鲁布斯法和狄克逊法是检验离群值数量等于1时较优的方法,拉依达法具有计算操作简便的优势。
我们从文献[10]中选取了一个例子,对某种砖的抗压测试10个试样,其数据经排列后为(单位为MPa):4.7,5.4,6.0,6.5,7.3,7.7,8.2,9.0,10.1,14.0。检验是否存在上侧异常值。
已经检验出该数据服从正态分布。
题解
样品量n = 10,平均值x¯x¯= 7.9,标准差s = 2.7。
方法一(格鲁布斯法):
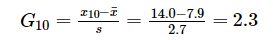
确定检出水平α = 0.05,查表得到G0.95(10) = 2.176,因为G10 > G0.95(10),所以判定14.0为上侧的异常值。
方法二(狄克逊法):

确定检出水平α = 0.05,查表得到D0.95(10) = 0.477,因为r11 < D0.95(10),所以不能判定14.0为上侧的异常值。
方法三(拉依达法)
因为|x10−x¯|=|14.0−7.9|=6.1<3s=3×2.7=8.1|x10−x¯|=|14.0−7.9|=6.1<3s=3×2.7=8.1,所以不能判定14.0为上侧的异常值。
三种方法检验离群值时,只有格鲁布斯法判定14.0为上侧的异常值,狄克逊法和拉依达法不能判定14.0为异常值。但是格鲁布斯法保留的数据范围窄,这一个例子并不能说明使用格鲁布斯法一定比狄克逊法或者拉依达法更为准确。存在不一样结果的原因可以从这三方面考虑:第一,格鲁布斯法和狄克逊法都根据样本容量和检出水平来确定置信区间,这种考虑应是更为严谨的做法;第二,狄克逊法通过极差比来判断是否存在异常值,当数据本身较为分散,极差比反映离群值的灵敏度就可能会下降,可能存在以假当真的情况;第三,所给的样本容量较小,在使用拉依达法判定离群值时,无法发现混在样品中的异常值。
例2
我们通过这个例子想要说明Q检验法存在以假为真的误判问题,其中以格鲁布斯法作为参考标准。
某工厂对原料进行例行检验,10次重复测量,将得到的数据按从小到大的顺序排列,91,96,99,101,104,108,111,114,119,138。检验是否存在上侧异常值。
已经检验出该数据服从正态分布。
题解
样品量n = 10,平均值x¯x¯= 108,标准差s = 13.5。
方法一(格鲁布斯法):
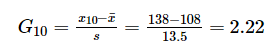
确定检出水平α = 0.05,查表得到G0.95(10) = 2.176,因为G10 > G0.95(10),所以判定138为上侧的异常值。
方法二(Q检验法):

确定检出水平α = 0.05,查表得到Q0.95(10) = 0.466,因为Q10 < Q0.95(10),所以不能判定138为异常值。
因为Q检验法容易受极端值的影响,当数据中存在极端值时,使得Q检验法对于异常值的判断灵敏性不够,所以发生以假为真的误判问题。
例3
我们通过这个例子想要说明t检验法存在以真为假的误判问题,其中以格鲁布斯法作为参考标准。
实验室一次对同一物质同一特性的重复观测14次,得到的观测值排列后为-0.44,-0.30,-0.24,-0.22,-0.13,-0.05,0.06,0.10,0.18,0.20,0.39,0.48,0.63,1.01。检验是否存在上侧异常值。
已经检验出该数据服从正态分布。
题解
方法一(格鲁布斯法):
样本容量n = 14,平均值x¯x¯= 0.12,标准差s = 0.40。
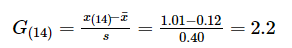
确定检出水平α = 0.05,查表得到G0.95(14) = 2.371,因为G(14) < G0.95(14),所以不能判定1.01为上侧的异常值。
方法二(t检验法):
样本容量n = 14,平均值x′¯ = 0.051,s' = 0.32,

确定检出水平α = 0.05,查表得到k0.95(14) = 2.160,因为k(14) > k0.95(14),所以判定1.01为上侧的异常值。
因为t检验法预先剔除了离群值进行计算标准偏差,使得所得标准偏差偏小,从而处理临界的极值被误判成异常值。所以发生了以真为假的误判问题。
采用恰当的方法以及多种判别法同时使用可以在一定程度上降低误判发生的几率,但是当多种判别法得出的结果不一样时,我们应该如何取舍呢?以笔者的观点,采用不同方法的目的就是判断数据是否为异常值。那么在多种方法都适用,或者说多种方法的准确度相当的情况下,判断结果是与之后处理方法相对应,也就是跟实际情况相联系。这种情况下方法的选择和后续处理方法的考虑因素是相统一的。
3 离群值处理方法讨论
Andersen [11]在一篇关于分析质量保证的论文中对离群值的处理提出了自己的看法。他以不同标准实验室对某标准值进行测定导致不确定度增大引出“在统计学中大量数据必定趋向真值,而在实验中高度重复的数据却不一定趋向真值”的观点,从而说明用统计学方法舍弃离群值是不合理的。舍弃离群值的做法不仅会改变均值和不确定度,还会降低实验的可重复度。而邓勃[12]教授对于离群值的处理主张“技术异常造成的异常值舍弃,无法找出技术异常的高度离群值亦要舍弃”“离群值在标准物质误差范围内或仪器精度范围内都不应舍弃”“以估计总体参数为目的时一般需舍弃离群值”。对于不同的观点进行了解和分析后,笔者也在下面给出一点个人的看法。
在各教材以及国标中介绍的离群值判定法都是基于正态分布而构建的模型,但是事实上除去正态分布,还有重尾分布、偏态分布等类型。虽然这些分布类型在化学分析中出现得较少,但是盲目运用基于正态分布的方法对数据进行判定并舍弃离群值,在某种程度上会增大误判的风险。在对数据分布情况进行分析之后,若是非正态分布,离群值的保留就显得尤为重要。
即使是确定了数据符合正态分布,也并不意味着可以直接舍弃离群值。为此,国标[13]对于已经判定为异常值的数据给出了三种不同的处理方法。
在上文中我们提到对于离群值判定需要从实际需要出发,对于离群值的处理也应该遵循这种原则。对于科研中出现的离群值,很可能代表着一些未知的因素。在这种情况下,对于离群值的保留和深入分析就有可能带来新的发现。在制药行业中,由于药品关系到人的生命安全,对于检测中的离群值的舍弃可能造成安全隐患。而在工业生产中对于原料的指标要求较为宽松,除去离群值可以对整体情况做出较好的估计,即使是有少量异常原料也不会造成严重后果。
还有一点值得注意的是,虽然均值和标准偏差可以很灵敏地反映出样品的变化,但是这种高灵敏度同时也具有缺点,就是导致检验方法很容易受极端值的影响从而产生误判的问题,即均值和标准偏差所具有的耐抗性低的缺点。故对于例行检验,笔者更加偏向邓勃[12]教授“以估计总体参数为目的时一般需舍弃离群值”的观点。而Andersen [11]在文中提及的不同标准实验室对同一标准物质进行测定所得结果偏差较大,笔者认为与各实验室之间的实验条件差异有关。虽然实验室强调控制变量,标准实验室尤甚,但是无关变量种类繁多,在不同时间地点进行测定,误差是很难避免的。在这种情况下,若仍然保留离群值进行分析,对于标准值的估计就可能出现一定的偏差。
4 总结与讨论
当离群值数量仅为1时,格鲁布斯法综合犯错的可能性最低,国际标准化组织(International Standards Organization)和美国材料试验协会(The American Society for Testing and Materials)均推荐适用格鲁布斯法[7]。在国标[13]中,离群值的个数为1时,选用的方法是格鲁布斯法和狄克逊法。当限定检出离群值的个数大于1时,格鲁布斯法检验的结果不是最优的,一般采用偏度-峰度检验法或者狄克逊检验法。但是偏度-峰度检验法由于计算工作量大,进行异常值的连续检验的时候还有可能发生“判多为少”或“判有为无”错误的可能,并未能广泛应用。
文中列举了一些离群值的判定和处理方法,针对其的分析仅为笔者个人作出的概括性观点,可能与实际情况有一定偏差。另外需要说明的是,本文所介绍的各种方法都是基于正态分布的假设,当碰到不符合正态分布的样本时,使用上述方法的误差较大,对此情况许多统计软件采用箱线图法对离群值进行判断。但是由于箱线图是基于经验所形成的方法,且不同软件对于四分点和上下限的定义有本质上的区别,所以没有被列为一种标准方法[14]。
采用恰当的方法以及多种判别法同时使用可以在一定程度上降低误判发生的几率,但是不同方法的原理和侧重点不同,难免会出现不同判别法所得结果不一样的情况。此时,应从实际需求出发以得到最优的结论。对于离群值的处理并非只有舍弃,而是需要对其产生的原因进行分析后再结合实际进行处理。
来自文献:
- 朱嘉欣,,数据离群值的检验及处理方法讨论
- http://www.dxhx.pku.edu.cn/article/2018/1000-8438/20180812.shtml
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)