目录
摘要
训练数据
1、下载Pytoch版的EfficientDet。
2、制作数据集。
3、下载EfficientNets预训练模型。
4、安装模型需要的包
5、放置数据集
6、修改train.py中的参数
测试
注意
摘要
谷歌大脑团队 Quoc V. Le 等人系统研究了多种目标检测神经网络架构设计,提出了能够提升模型效率的几项关键优化。首先,他们提出加权双向特征金字塔网络(weighted bi-directional feature pyramid network,BiFPN),从而轻松、快速地实现多尺度特征融合;其次,他们提出一种复合缩放(compound scaling)方法,同时对所有主干网络、特征网络和边界框/类别预测网络的分辨率、深度和宽度执行统一缩放。基于这些优化,研究者开发了新型目标检测器 EfficientDet。模型结构如下:

EfficientDet的特点:
- 使用EfficientNet网格作为主干网络。
- 提出BiFPN,使模型实现高效的双向跨尺度连接和加权特征融合。下图是集中常见的FPN结构图:

a)FPN 使用自上而下的路径来融合多尺度特征 level 3-7(P3 - P7);b)PANet 在 FPN 的基础上额外添加了自下而上的路径;c)NAS-FPN 使用神经架构搜索找出不规则特征网络拓扑;(d)-(f) 展示了该论文研究的三种替代方法。d 在所有输入特征和输出特征之间添加成本高昂的连接;e 移除只有一个输入边的节点,从而简化 PANet;f 是兼顾准确和效率的 BiFPN。
- 模型缩放。提出一种目标检测器复合缩放方法,即统一扩大所有主干网络、特征网络、边界框/类别预测网络的分辨率/深度/宽度。
基于以上的特点,EfficientDet-D7 在 COCO 数据集上实现了当前最优的 51.0 mAP,准确率超越之前最优检测器(+0.3% mAP),其规模仅为之前最优检测器的 1/4,而后者的 FLOPS 更是 EfficientDet-D7 的 9.3 倍。
论文地址:https://arxiv.org/abs/1911.09070
训练数据
1、下载Pytoch版的EfficientDet。
https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch
2、制作数据集。
将标注好的:Labelme数据集转为COCO数据集。
参照https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/106255087。
本例用的数据集:https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/14003627
3、下载EfficientNets预训练模型。
b0: https://github.com/lukemelas/EfficientNet-PyTorch/releases/download/1.0/efficientnet-b0-355c32eb.pth
b1: https://github.com/lukemelas/EfficientNet-PyTorch/releases/download/1.0/efficientnet-b1-f1951068.pth
b2: https://github.com/lukemelas/EfficientNet-PyTorch/releases/download/1.0/efficientnet-b2-8bb594d6.pth
b3: https://github.com/lukemelas/EfficientNet-PyTorch/releases/download/1.0/efficientnet-b3-5fb5a3c3.pth
b4: https://github.com/lukemelas/EfficientNet-PyTorch/releases/download/1.0/efficientnet-b4-6ed6700e.pth
b5: https://github.com/lukemelas/EfficientNet-PyTorch/releases/download/1.0/efficientnet-b5-b6417697.pth
b6: https://github.com/lukemelas/EfficientNet-PyTorch/releases/download/1.0/efficientnet-b6-c76e70fd.pth
b7: https://github.com/lukemelas/EfficientNet-PyTorch/releases/download/1.0/efficientnet-b7-dcc49843.pth
将预训练模型放到指定的目录下面:

如果可以连接外网可以忽略这个步骤,运行时会自动下载预训练模型。
4、安装模型需要的包
- pycocotools
- pytorch1.2版本以上(模型用了pytorch的nms,在1.2以上的版本中才包含)
- python-opencv(pip install opencv-python)
- tensorboardX(pip install tensorboardx)
- webcolors(pip install webcolors)
结合本地环境,如果还有缺少的自行下载,唯一要注意的就是pytorch的版本。
- 修改coco.yml参数。
project_name: coco # also the folder name of the dataset that under data_path folder
train_set: train2017#注意和COCO转化时,选择的年份一致。
val_set: val2017
num_gpus: 1
# mean and std in RGB order, actually this part should remain unchanged as long as your dataset is similar to coco.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
# this is coco anchors, change it if necessary
anchors_scales: '[2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)]'
anchors_ratios: '[(1.0, 1.0), (1.4, 0.7), (0.7, 1.4)]'
# must match your dataset's category_id.
# category_id is one_indexed,
# for example, index of 'car' here is 2, while category_id of is 3
obj_list: ['aircraft', 'oiltank'] #类别顺序和转化COCO时候的类别顺序一致。COCO中设置'aircraft':1, 'oiltank':2
5、放置数据集
将数据集放到datasets目录下,如下图:

6、修改train.py中的参数
主要需要修改的参数有compound_coef、batch_size、num_epochs、save_interval、lr
、data_path、load_weights
compound_coef:0-7,选择EfficientDet的模型,对应d0-d7,同时对应EfficientNet网络的b0-b7。
batch_size:根据显卡显存的大小和类别的多少定义。
epochs:默认为500,一般情况300即可。
save_interval:迭代多少次保存一个模型。
lr:学习率,默认为10-4,这个模型不要用太大的学习率,经测试,学习率太大不收敛。
data_path:数据集的路径,本例放在datasets路径下面,就设置为datasets。
load_weights:加载模型的路径,如果没有一次训练完,再次训练就要用到此参数。
参数配置如下:
def get_args():
parser = argparse.ArgumentParser('Yet Another EfficientDet Pytorch: SOTA object detection network - Zylo117')
parser.add_argument('-p', '--project', type=str, default='coco', help='project file that contains parameters')
parser.add_argument('-c', '--compound_coef', type=int, default=4, help='coefficients of efficientdet')
parser.add_argument('-n', '--num_workers', type=int, default=2, help='num_workers of dataloader')
parser.add_argument('--batch_size', type=int, default=2, help='The number of images per batch among all devices')
parser.add_argument('--head_only', type=boolean_string, default=False,
help='whether finetunes only the regressor and the classifier, '
'useful in early stage convergence or small/easy dataset')
parser.add_argument('--lr', type=float, default=1e-4)
parser.add_argument('--optim', type=str, default='adamw', help='select optimizer for training, '
'suggest using \'admaw\' until the'
' very final stage then switch to \'sgd\'')
parser.add_argument('--num_epochs', type=int, default=300)
parser.add_argument('--val_interval', type=int, default=1, help='Number of epoches between valing phases')
parser.add_argument('--save_interval', type=int, default=11970, help='Number of steps between saving')
parser.add_argument('--es_min_delta', type=float, default=0.0,
help='Early stopping\'s parameter: minimum change loss to qualify as an improvement')
parser.add_argument('--es_patience', type=int, default=0,
help='Early stopping\'s parameter: number of epochs with no improvement after which training will be stopped. Set to 0 to disable this technique.')
parser.add_argument('--data_path', type=str, default='datasets', help='the root folder of dataset')
parser.add_argument('--log_path', type=str, default='logs/')
parser.add_argument('-w', '--load_weights', type=str, default=None,
help='whether to load weights from a checkpoint, set None to initialize, set \'last\' to load last checkpoint')
parser.add_argument('--saved_path', type=str, default='logs/')
parser.add_argument('--debug', type=boolean_string, default=False, help='whether visualize the predicted boxes of trainging, '
'the output images will be in test/')
运行效果如下:
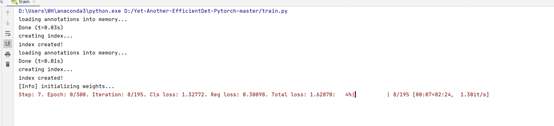
测试
修改efficientdet_test.py参数:
- compound_coef和训练时设置的参数相对应,比如训练时设置的是0,测试的时候也设置为0
- img_path:测试图片的路径。
- threshod = 0.2,iou_threshod = 0.35。这两个参数在物体检测中常见,一个过滤分数,一个设置重叠度。
- obj_ist =['aircraft', 'oitank']:类别,和训练时的类别顺序一致。
修改完成后运行efficientdet_test.py文件
会在test文件夹下面保存结果的图片,结果如下:

运行coco_eval.py,会生成,测试模型得分。在这里注意numpy的版本。如果太高会报一个不兼容的错误,需要降到17版本。我用的版本是1.17.4,结果如下:
注意
1、这个模型使用时,compound_coef在训练集和测试集相对应,如果不仔细容易出现错乱。
2、在使用COCO数据集时,注意类别的顺序,如果出现错乱会导致得分很低甚至为零。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)