欢迎转载,但请务必注明原文出处及作者信息。
@author: huangyongye
@creat_date: 2017-03-09
前言: 根据我本人学习 TensorFlow 实现 LSTM 的经历,发现网上虽然也有不少教程,其中很多都是根据官方给出的例子,用多层 LSTM 来实现 PTBModel 语言模型,比如:
tensorflow笔记:多层LSTM代码分析
但是感觉这些例子还是太复杂了,所以这里写了个比较简单的版本,虽然不优雅,但是还是比较容易理解。
如果你想了解 LSTM 的原理的话(前提是你已经理解了普通 RNN 的原理),可以参考我前面翻译的博客:
(译)理解 LSTM 网络 (Understanding LSTM Networks by colah)
如果你想了解 RNN 原理的话,可以参考 AK 的博客:
The Unreasonable Effectiveness of Recurrent Neural Networks
很多朋友提到多层怎么理解,所以自己做了一个示意图,希望帮助初学者更好地理解 多层RNN.
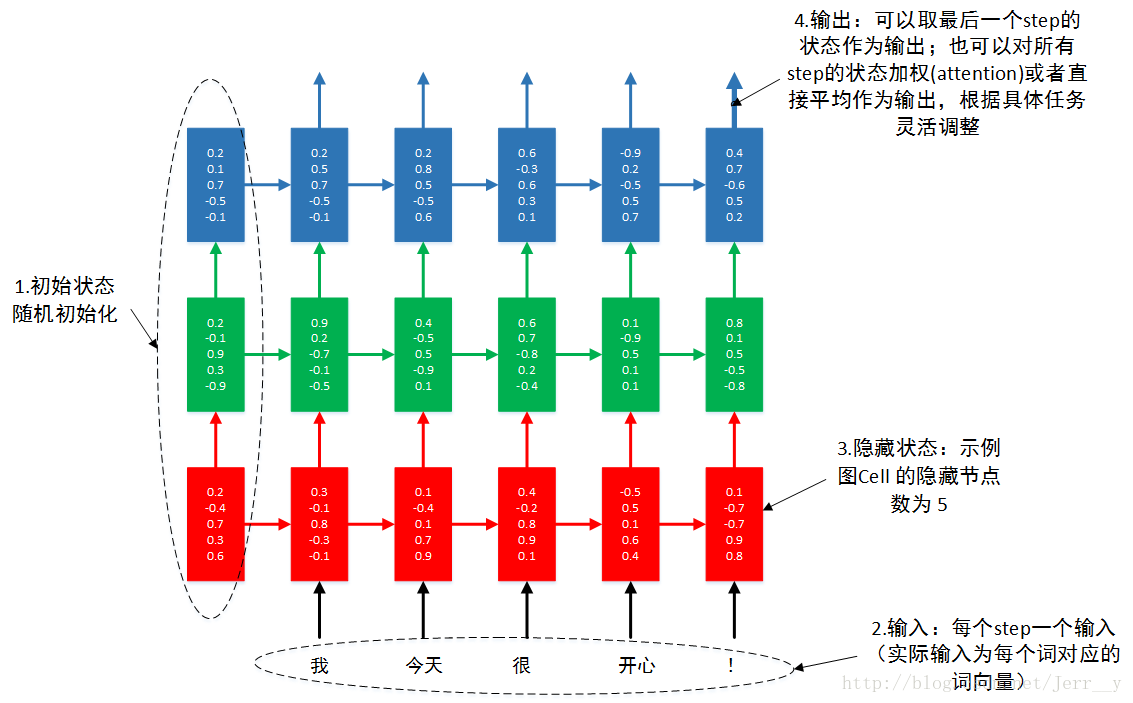
图1 3层RNN按时间步展开
本例不讲原理。通过本例,你可以了解到单层 LSTM 的实现,多层 LSTM 的实现。输入输出数据的格式。 RNN 的 dropout layer 的实现。
import tensorflow as tf
import numpy as np
from tensorflow.contrib import rnn
from tensorflow.examples.tutorials.mnist import input_data
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
print mnist.train.images.shape
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
(55000, 784)
1. 首先设置好模型用到的各个超参数
lr = 1e-3
batch_size = tf.placeholder(tf.int32)
input_size = 28
timestep_size = 28
hidden_size = 256
layer_num = 2
class_num = 10
_X = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, class_num])
keep_prob = tf.placeholder(tf.float32)
2. 开始搭建 LSTM 模型,其实普通 RNNs 模型也一样
X = tf.reshape(_X, [-1, 28, 28])
lstm_cell = rnn.BasicLSTMCell(num_units=hidden_size, forget_bias=1.0, state_is_tuple=True)
lstm_cell = rnn.DropoutWrapper(cell=lstm_cell, input_keep_prob=1.0, output_keep_prob=keep_prob)
mlstm_cell = rnn.MultiRNNCell([lstm_cell] * layer_num, state_is_tuple=True)
init_state = mlstm_cell.zero_state(batch_size, dtype=tf.float32)
outputs = list()
state = init_state
with tf.variable_scope('RNN'):
for timestep in range(timestep_size):
if timestep > 0:
tf.get_variable_scope().reuse_variables()
(cell_output, state) = mlstm_cell(X[:, timestep, :], state)
outputs.append(cell_output)
h_state = outputs[-1]
3. 设置 loss function 和 优化器,展开训练并完成测试
- 以下部分其实和之前写的 TensorFlow入门(三)多层 CNNs 实现 mnist分类 的对应部分是一样的。
W = tf.Variable(tf.truncated_normal([hidden_size, class_num], stddev=0.1), dtype=tf.float32)
bias = tf.Variable(tf.constant(0.1,shape=[class_num]), dtype=tf.float32)
y_pre = tf.nn.softmax(tf.matmul(h_state, W) + bias)
cross_entropy = -tf.reduce_mean(y * tf.log(y_pre))
train_op = tf.train.AdamOptimizer(lr).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess.run(tf.global_variables_initializer())
for i in range(2000):
_batch_size = 128
batch = mnist.train.next_batch(_batch_size)
if (i+1)%200 == 0:
train_accuracy = sess.run(accuracy, feed_dict={
_X:batch[0], y: batch[1], keep_prob: 1.0, batch_size: _batch_size})
print "Iter%d, step %d, training accuracy %g" % ( mnist.train.epochs_completed, (i+1), train_accuracy)
sess.run(train_op, feed_dict={_X: batch[0], y: batch[1], keep_prob: 0.5, batch_size: _batch_size})
print "test accuracy %g"% sess.run(accuracy, feed_dict={
_X: mnist.test.images, y: mnist.test.labels, keep_prob: 1.0, batch_size:mnist.test.images.shape[0]})
Iter0, step 200, training accuracy 0.851562
Iter0, step 400, training accuracy 0.960938
Iter1, step 600, training accuracy 0.984375
Iter1, step 800, training accuracy 0.960938
Iter2, step 1000, training accuracy 0.984375
Iter2, step 1200, training accuracy 0.9375
Iter3, step 1400, training accuracy 0.96875
Iter3, step 1600, training accuracy 0.984375
Iter4, step 1800, training accuracy 0.992188
Iter4, step 2000, training accuracy 0.984375
test accuracy 0.9858
我们一共只迭代不到5个epoch,在测试集上就已经达到了0.9825的准确率,可以看出来 LSTM 在做这个字符分类的任务上还是比较有效的,而且我们最后一次性对 10000 张测试图片进行预测,才占了 725 MiB 的显存。而我们在之前的两层 CNNs 网络中,预测 10000 张图片一共用了 8721 MiB 的显存,差了整整 12 倍呀!! 这主要是因为 RNN/LSTM 网络中,每个时间步所用的权值矩阵都是共享的,可以通过前面介绍的 LSTM 的网络结构分析一下,整个网络的参数非常少。
4. 可视化看看 LSTM 的是怎么做分类的
毕竟 LSTM 更多的是用来做时序相关的问题,要么是文本,要么是序列预测之类的,所以很难像 CNNs 一样非常直观地看到每一层中特征的变化。在这里,我想通过可视化的方式来帮助大家理解 LSTM 是怎么样一步一步地把图片正确的给分类。
import matplotlib.pyplot as plt
看下面我找了一个字符 3
print mnist.train.labels[4]
[ 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
我们先来看看这个字符样子,上半部分还挺像 2 来的
X3 = mnist.train.images[4]
img3 = X3.reshape([28, 28])
plt.imshow(img3, cmap='gray')
plt.show()

我们看看在分类的时候,一行一行地输入,分为各个类别的概率会是什么样子的。
X3.shape = [-1, 784]
y_batch = mnist.train.labels[0]
y_batch.shape = [-1, class_num]
X3_outputs = np.array(sess.run(outputs, feed_dict={
_X: X3, y: y_batch, keep_prob: 1.0, batch_size: 1}))
print X3_outputs.shape
X3_outputs.shape = [28, hidden_size]
print X3_outputs.shape
(28, 1, 256)
(28, 256)
h_W = sess.run(W, feed_dict={
_X:X3, y: y_batch, keep_prob: 1.0, batch_size: 1})
h_bias = sess.run(bias, feed_dict={
_X:X3, y: y_batch, keep_prob: 1.0, batch_size: 1})
h_bias.shape = [-1, 10]
bar_index = range(class_num)
for i in xrange(X3_outputs.shape[0]):
plt.subplot(7, 4, i+1)
X3_h_shate = X3_outputs[i, :].reshape([-1, hidden_size])
pro = sess.run(tf.nn.softmax(tf.matmul(X3_h_shate, h_W) + h_bias))
plt.bar(bar_index, pro[0], width=0.2 , align='center')
plt.axis('off')
plt.show()

在上面的图中,为了更清楚地看到线条的变化,我把坐标都去了,每一行显示了 4 个图,共有 7 行,表示了一行一行读取过程中,模型对字符的识别。可以看到,在只看到前面的几行像素时,模型根本认不出来是什么字符,随着看到的像素越来越多,最后就基本确定了它是字符 3.
好了,本次就到这里。有机会再写个优雅一点的例子,哈哈。其实学这个 LSTM 还是比较困难的,当时写 多层 CNNs 也就半天到一天的时间基本上就没啥问题了,但是这个花了我大概整整三四天,而且是在我对原理已经很了解(我自己觉得而已。。。)的情况下,所以学会了感觉还是有点小高兴的~
17-04-19补充几个资料:
- recurrent_network.py 一个简单的 tensorflow LSTM 例子。
- Tensorflow下构建LSTM模型进行序列化标注 介绍非常好的一个 NLP 开源项目。(例子中有些函数可能在新版的 tensorflow 中已经更新了,但并不影响理解)
5. 附:BASICLSTM.__call__()
'''code: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/rnn/python/ops/core_rnn_cell_impl.py'''
def __call__(self, inputs, state, scope=None):
"""Long short-term memory cell (LSTM)."""
with vs.variable_scope(scope or "basic_lstm_cell"):
if self._state_is_tuple:
c, h = state
else:
c, h = array_ops.split(value=state, num_or_size_splits=2, axis=1)
concat = _linear([inputs, h], 4 * self._num_units, True, scope=scope)
i, j, f, o = array_ops.split(value=concat, num_or_size_splits=4, axis=1)
new_c = (c * sigmoid(f + self._forget_bias) + sigmoid(i) *
self._activation(j))
new_h = self._activation(new_c) * sigmoid(o)
if self._state_is_tuple:
new_state = LSTMStateTuple(new_c, new_h)
else:
new_state = array_ops.concat([new_c, new_h], 1)
return new_h, new_state
本文代码:https://github.com/yongyehuang/Tensorflow-Tutorial
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)