用于RGBD人脸反欺骗的交叉模式焦损
摘要:自动检测呈现攻击的方法对于确保面部识别技术的可靠使用至关重要。文献中提供的大多数用于呈现攻击检测(PAD)的方法都无法将其推广到看不见的攻击。近年来,人们提出了多通道方法来提高PAD系统的鲁棒性。通常,只有有限数量的数据可用于附加通道,这限制了这些方法的有效性。在这项工作中,我们提出了一种新的PAD框架,它使用了RGB和深度通道,并引入了一种新的损耗函数。新的架构使用了来自两种模式的互补信息,同时减少了过度拟合的影响。本质上,提出了一种跨模式焦点损失函数,将每个信道的损失贡献作为各个信道的置信度的函数进行调制。在两个公开可用的数据集中进行了广泛的评估,证明了所提出的方法的有效性。
1引言
虽然人脸识别技术已经成为一种无处不在的生物识别认证方法,但在安全场景中使用时,易受呈现攻击presentation attacks(也称为“欺骗攻击”spoofing attacks)是一个主要问题[9]、[12]。这些攻击既可以是冒充攻击impersonation,也可以是混淆攻击obfuscation attacks。模拟攻击试图通过伪装成其他人来获取访问权限,而模糊攻击则试图逃避人脸识别系统。虽然在文献中已经提出了许多方法来解决这个问题,但是这些方法中的大多数都不能推广到看不见的攻击[10]。在实际场景中,不可能在训练PAD模型时预测所有类型的攻击。此外,PAD系统有望检测到新型的复杂攻击。因此,在PAD模型中具有看不见的攻击健壮性是很重要的。
大多数文献涉及使用RGB摄像机检测这些攻击。多年来,许多基于特征的方法被提出,使用颜色、纹理、运动、活体信息、直方图特征、局部二值模式和运动模式来执行PAD演示攻击检测。最近还提出了几种基于CNN的方法,包括3D-CNN、基于部分的模型等等。最近一些研究表明,使用二进制和深度监督形式的辅助信息可以提高性能。然而,这些方法大多数是专门针对2D攻击设计的,并且这些这些方法对具有挑战的3D和部分攻击的性能较差,此外,这些方法存在对为职工及的健壮性差的问题。
仅RGB模型的性能会因3D掩码和部分攻击等复杂攻击而恶化。由于可见光谱本身的局限性,文献中已经提出了几种用于PAD的多通道方法,如[30]、[12]、[31]、[11]、[2]、[6]、[5]、[15-18]。本质上,当多通道PAD系统捕获来自不同通道的互补信息时,欺骗多通道PAD系统变得更加困难。同时欺骗不同的渠道需要付出相当大的努力。多渠道方法已被证明是有效的,但这是以定制和昂贵的硬件为代价的。这可能会使这些系统难以广泛部署,即使它们很健壮。PAD有多种通道可以选择,例如RGB、深度、热成像、近红外光谱、SWIR(短波红外光谱)、紫外线、光场图像等。在这些不同的通道中,我们发现RGB-D设备在商业上是可用的,而且价格相当实惠,这使得在现实世界的场景中部署它们成为可能。英特尔RealSense系列设备、Microsoft Kinect和OpenCV AI Kit(OAKD)[1]都是无需任何额外工作即可获得多通道图像的标准设备。由于这些通道广泛地集成在一个封装中,我们选择RGB和Depth作为这项工作中使用的两个通道。然而,建议的框架可以简单地扩展到任何信道组合。
即使在使用多个通道的情况下,模型也往往会过度适应训练集中出现的攻击。这些模型在训练集中已知攻击中可以发挥完美的作用,但是在现实场景中面对未知攻击模型的性能会退化。这是大多数机器学习算法的普遍现象,在训练数据量有限的情况下,这个问题会变得更加严重。在缺乏强有力的先验的情况下,这些模型可能会过度拟合它所训练的特定数据集的统计偏差,并且可能无法推广到看不见的样本。由于多通道方法由于额外的通道而增加了参数的数量,因此过拟合的可能性也增加了。
在这项工作中,我们从两个不同的方向解决这个问题。首先,我们使用多头架构,遵循后期融合策略来组合不同的信息通道。我们没有将表示连接到一个联合最终节点中,而是分别为单个分支和联合分支保留了三个不同的头部,这可以被视为一种体系结构规则化的形式。建议的体系结构可以在图1中找到。这使我们能够监督单独的渠道和联合代表,确保稳健的代表将在个人和联合分支机构中学习。其次,我们提出了一种跨模式焦点损失函数来监督单独的信道,这些信道在考虑到当前信道的置信度的情况下调制了该损失函数。
主要贡献:1、提出了一种基于同步采集的RGB-D样本的帧级RGB-D人脸PAD方法。
2、提出了一种新的损失函数,称为跨模式焦点损失(CMFL),该函数可用于多流结构中的单个通道的监督。
3、虽然该模型是针对多通道场景进行训练的,但是它也可以通过仅使用与可用通道对应的头部的分数来部署到单个通道。
4、我们在两个公开可用的数据集中展示了该框架的有效性,该数据集中包含了各种具有挑战性的不可见攻击。
2提出的方法
2.1预处理
PAD管道作用于裁剪后的面部图像。对于RGB图像,预处理阶段包括使用MTCNN[32]框架的人脸检测和地标定位,然后是对齐。通过使眼睛中心水平,然后将它们的大小调整到224×224的分辨率来对齐检测到的人脸。对于深度图像,使用中值绝对偏差(MAD)[27]的归一化方法来将面部图像归一化到8位范围。来自RGB和深度通道的原始图像已经在空间上配准,因此可以使用相同的变换来对齐深度图像中的面部。
2.2网络架构和损失函数
2.2.1架构
从主流文献中已经观察到,多通道方法对大范围的攻击是健壮的[15-18]。一般而言,有四种不同的策略来融合来自多个通道的信息,它们是:1)早期融合,即通道在输入级堆叠(例如,MC-PixBiS[18])。第二种策略是后期融合,这意味着来自不同网络的表示在类似于特征融合的较晚阶段被组合(例如MCCNN[17]),第三种策略是分数级融合,其中针对不同通道分别训练单个网络,并对每个通道的标量分数执行分数级融合。第四种策略是一种混合方法,将来自多个层次的信息组合在一起,如[28]所示。
虽然多个通道可以很好地应对各种各样的攻击,但它们往往会对已知攻击过拟合,因为所有通道都一起使用,并作为二进制分类器进行训练。为了避免这种情况,我们提出了一种遵循后期融合策略的多头架构。所提出的网络的体系结构如图1所示。本质上,该体系结构由双流网络组成,该网络具有用于组件(RGB和深度)通道的单独分支。来自两个通道的嵌入被组合以形成第三分支。完全连接的层被添加到这些分支中的每一个以形成最终的分类头。这三个头部由损失函数共同监督,该损失函数迫使网络从各个通道以及联合表示中学习判别信息,从而减少了过度拟合的可能性。即使在测试时通道丢失,多头结构也可以进行评分,这意味着即使网络接受了训练,我们也可以单独使用RGB分支(仅使用RGB头的分数)进行评分。
该分支由Huanget等[19]提出的DenseNet体系结构(densenet161)的前八个区块组成。在DenseNet架构中,每层都连接到每一层,减少了消失的梯度问题,同时减少了参数的数量。我们使用来自Image-Net数据集的预训练权重来初始化各个分支。对于RGB和深度通道,RGB和深度通道的输入通道数量分别修改为3和1。对于深度分支,使用三通道权重的平均值来初始化第一层中修改的卷积核的权重。在每个分支中,在密集层之后添加全局平均池化(间隙)层以获得384维嵌入。RGB和深度嵌入连接形成联合嵌入层。在每个嵌入的顶部添加一个完全连接的层,然后进行S形(sigmoid函数)激活,以在框架中形成不同的头部。在训练时,这些头部中的每一个都由单独的损失功能监督。在测试时,RGB-D分支的分数用作PAD分数。
2.2.2跨模态焦点损失函数CMFL
使用单独的头部可以训练具有在测试时处理丢失通道的能力的多通道模型。现在,监督这个网络的一个简单的方法是用二进制交叉熵(BCE)来监督各个分支。
然而,单个信道的BCE(二进制交叉熵)的使用可能并不理想。问题如下所示:我们可以将不同的通道视为同一样本的不同视图,对于某些攻击,可能无法仅从一个视图中区分出来。有可能某些攻击的图片在单通道的情况下看起来像真实的样本。例如,在深度通道中查看面部化妆时,看起来与真实样本的深度贴图完全相同。在这种情况下,用BCE来监督深度分支的天真方式可能会导致过度拟合。然而,在相同的情况下,区别化妆在RGB和联合表示中会更加明显。从这个例子可以看出,单独监督各个分支机构可能不会产生稳健的决策边界。解决这个问题的一种新方法是使用当前分支和另一个分支的预测概率来改变每个分支中样本的损失贡献。我们提出了一种跨模式的焦点损失函数来监督各个通道,该函数基于当前和备用通道的置信度来调整该损失函数。
对于每个分支,能够正确分类的样本应该在得分空间中被很好地分开。同时,我们鼓励每个分支在没有足够的歧视性信息时产生不确定的分数,而不是过度拟合训练数据中的某些统计偏差。然而,只有当另一个分支机构能够自信地正确地对样本进行分类时,这一点才适用。
更正式地,考虑其中样本是多模式的二进制分类问题,即,每个样本是捕捉具有互补信息的不同视图的一对图像或特征。现在假设分类问题不能仅用单个通道来完成(或者是一个非常困难的问题)。组合来自两个通道的特征并使用使用联合特征的学习策略可以为此提供解决方案。但是,这可能会导致过度拟合,并且无法在测试时处理丢失的通道。
如果我们在个别分支机构使用BCE,损失将对无法与特定渠道提供的信息进行分类的样品造成沉重的惩罚。在这种情况下,模型可能会开始过度拟合数据集中的偏差,以最小化损失函数,从而导致过度拟合的模型。
为了避免这种情况,我们提出了跨模态焦点损失(CMFL)来监督单个通道。其核心思想是,当其中一个通道能够以较高的置信度正确地对样本进行正确分类时,则可以降低另一个分支中的样本的损失贡献。如果一个渠道能够自信地正确地对样本进行分类,那么我们就不希望另一个分支对模型进行更多的惩罚。CMFL迫使每个分支学习单个信道的稳健表示,然后可以与联合分支一起使用,从而有效地充当辅助损失函数。
放松正确分类样本的损失贡献的思想类似于目标检测问题中使用的焦点损失[23]。在焦点损失中,使用一个调制因子来减少由高置信度正确分类的样本造成的损失。我们使用这一想法,通过调制损失因子,将样本在当前分支和交替分支中的置信度考虑在内。
考虑二进制分类问题中交叉熵(CE)的表达式:

其中y∈{0,1}表示类别标签(y:0攻击,y:1真诚),p∈[0,1]表示类别的概率。我们遵循与[23]中类似的记号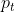 ,即目标类别的概率:
,即目标类别的概率:

写
在α平衡形式中,CE损耗可以写成:

标准的α平衡焦损(FL)[23]将调制因子(1−pt)γ添加到交叉熵损耗,具有可调聚焦参数γ≥0,使得损耗公式为。

考虑图3中的两流多分支多头模型。Xp和Xq表示来自不同模态的图像输入,Ep、Eq和Er表示单个和联合表示的相应嵌入。在每个分支中,在嵌入层之后,存在提供分类概率的完全连通层(紧随其后的是S型层)。变量p,q和r表示这些概率。
两流多头模态图,显示了单个和联合分支的嵌入和概率。这也可以扩展到多个头部。

提出的跨模态损耗函数(CMFL)如下:

函数w(pt,qt)取决于来自两个单独分支的信道给出的概率。这种调节因子应该随着另一个分支的概率增加而增加,同时应该能够防止非常自信的错误。因此,在本研究中,我们使用两个分支的调和平均值来加权另一个分支的概率。当另一家分支机构给出有信心的预测时,这可以减少损失贡献。该函数的表达式如下所示:
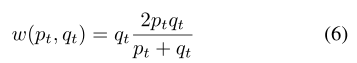
注意,函数w是不对称的,即w(qt,pt)的表达式为:

这意味着加权函数取决于另一个分支的概率。现在我们使用所提出的损失函数作为辅助监督,最小化总损失函数给出如下:

在本研究中,我们非最佳地将λ的值设置为0.5。交叉熵和建议损耗的损耗曲线如图2所示。当其他分支的概率为零时,损失等价于标准交叉。当另一个分支能够正确地对样本进行分类时,损失贡献减少。也就是说,当一个攻击实例被网络CNNp错误分类时,除非模型CNNq能够高置信度地对攻击样本进行分类,否则网络CNNp将受到惩罚。当w(p,q)→1时,调制因子变为零,这意味着如果一个通道能够完美地进行分类,则另一个分支就会受到较少的惩罚。此外,焦点参数γ可以调整以改变损耗曲线的行为。我们在所有实验中都使用了经验值γ=3。
在不损失通用性的前提下,该框架也可以推广到其他多通道分类问题。
2.2.3实施细节
我们在训练阶段用概率为0.5的随机水平翻转来执行数据增强。使用ADAM优化器使组合损失函数最小化[21]。学习速率为1×10−4,权值衰减参数为1×10−5。我们使用64个小批量,网络在GPU网格上训练了25个周期。在模型的评估过程中,使用RGB-D头部的分数来计算最终的PAD分数。提出的架构大约有639M个参数和大约9.16GFLOPS。整个架构和训练网络是使用PyTorch[29]库实现的。
3实验和结果
3.1使用的数据集
我们使用了两个公开可用的数据集进行实验,分别名为WMCA和HQ-WMCA,它们包含了各种各样的2D、3D和部分攻击。
3.3.1 WMCA数据集
Wide Multi-Channel Presentation Attack(WMCA)[17]数据库包含各种各样的2D和3D演示攻击,共有来自72个受试者的1679个视频样本。使用两种消费级设备英特尔®RealSense™SR300(用于颜色、深度和红外)和Seek热压缩PRO(用于热通道)可以同步收集多个通道,即颜色、深度、红外和热通道。虽然此数据库中提供了四个不同的通道,但在此工作中,我们重点关注从英特尔®RealSense™SR300设备获得的RGB和深度数据。
3.1.2 HQ-WMCA数据集
高质量宽多通道攻击(HQ-WMCA)[18,26]数据集由2904个真实攻击和呈现攻击的短多模式视频记录组成。这个数据库同样由各种各样的攻击组成,包括混淆攻击和模仿攻击。具体地说,考虑的攻击包括打印、重放、刚性面具、纸质面具、弹性面具、人体模型、眼镜、化妆、纹身和假发(图4)。该数据库包括51个不同主题的记录,包括颜色、深度、温度、红外(光谱)和短波红外(光谱)等多个通道。在这项工作中,我们考虑了用Basler acA1921-150uc相机拍摄的RGB通道和用Intel RealSense D415拍摄的深度图像。

3.2方案 (实验方案的设计,包括训练集和测试集等的如何构建)
由于这两个数据集都包含各种各样的攻击,因此我们分别为这两个数据集创建了留一(LOO)攻击方案。具体地说,在训练和开发集合中遗漏了一个攻击,评估集合由善意攻击和在训练和开发集合中遗漏的攻击组成。这就构成了未知攻击方案或零射击攻击方案。在这些协议中,PAD方法的性能给出了在现实世界场景中对其抵抗不可见攻击的健壮性的更现实的估计。此外,对于跨数据集实验,我们在两个数据集中创建了更大的测试协议,这些协议包括分布在训练集、开发集和测试集中的攻击(跨文件夹的身份互不相交)。
3.3指标 (方法性能评价指标)
为了对算法进行评估,我们使用了国际标准化组织/国际电工委员会30107-3标准[20]、攻击呈现分类错误率(APCER)和安全呈现分类错误率(BPCER)以及评估集合中的平均分类错误率(ACER)。我们在devset中计算BPCER值为1%的阈值。

对于跨数据库测试,按照[16]中的约定采用一半总错误率(HTER),该约定计算错误拒绝率(FRR)和错误接受率(FAR)的平均值。使用相等错误率准则(EER)在DEV集中计算的阈值在E值中计算HTER。
3.4基准方法
为了与现有技术进行公平的比较,我们从文献中为RGB-D通道实现了3种不同的多通道PAD方法。此外,我们还介绍了提出的仅由BCE监督的多头体系结构,作为比较的另一个基准。实施的基线如下所示。
MC-PixBiS:这是一个基于CNN的系统[14],扩展到多通道场景,如[18]中所述,使用二进制和像素二进制损失函数进行训练。该模型使用在输入级别堆叠在一起的RGB和深度通道。
MCCNN-OCCL-GMM:此模型是多通道CNN系统,建议使用一类对比损失(OCCL)和高斯混合模型,如文献[16]所述。该模型适用于接受RGB-D通道作为输入。
MC-ResNetDLAS:这是[28]中的架构的重新实现,该架构在“CASIA-SURF”挑战中获得一等奖,基于开源实现将其扩展到RGB-D频道*。我们使用[28]中建议的最佳预训练模型的初始化,然后使用RGB-D信道在当前协议中进行再训练。
RGBD-MH-BCE:它使用图1所示的新提出的多头体系结构,其中所有分支都由二进制交叉熵(BCE)进行监督。本质上,这等同于在跨模式损失函数的表达式中设置γ=0的值。这是一个基准,展示了新的多头架构单独带来的改进,并与新的损耗功能的性能变化进行了对比。
本文方法:这是我们最终提议的框架,它使用我们提议的多头架构,如图1所示,以及新提议的损失函数。更具体地说,各个通道分支由新提出的跨模态焦损函数(CMFL)来监督。基线方法参数的详细信息可以在我们的开源实现†中找到。
3.5实验
我们已经在WMCA和HQWMCA数据集中进行了实验,特别是留一法LOO,以评估其对不可见攻击的健壮性。结果将在以下各节中介绍。
3.5.1 在WMCA数据集中的结果

3.5.2 在HQ-WMCA数据集中的结果
 与WMCA相比,HQ-WMCA数据集包含更具挑战性的攻击。具体地说,有不同类型的面部纹身和局部攻击,这些纹身只占据了面部的一部分。当这些攻击没有出现在训练集中时,它们很难被检测出来,因为它们看起来与真正的样本非常相似。HQ-WMCA的实验结果如表2所示。与WMCA数据库类似,基线MCCNN-OCCL-GM和MC-ResNetDLA在HQ-WMCA数据库的LOO协议中表现不佳。另外,在WMCA中取得较好性能的MC-PixBiS方法在HQ-WMCA数据集上表现较差。这可能是因为数据库中的攻击具有挑战性。可以看出,提出的新的多头架构RGBD-MH-BCE已经改善了所有基线的结果,平均ACER达13.3±16.5。此外,随着CMFL损失的增加,ACER进一步提高到11.6±14.8%。实验结果表明,提出的体系结构已经提高了挑战攻击的性能,并且提出的损失进一步提高了HQ-WMCAdataSet中达到最先进水平的结果。
与WMCA相比,HQ-WMCA数据集包含更具挑战性的攻击。具体地说,有不同类型的面部纹身和局部攻击,这些纹身只占据了面部的一部分。当这些攻击没有出现在训练集中时,它们很难被检测出来,因为它们看起来与真正的样本非常相似。HQ-WMCA的实验结果如表2所示。与WMCA数据库类似,基线MCCNN-OCCL-GM和MC-ResNetDLA在HQ-WMCA数据库的LOO协议中表现不佳。另外,在WMCA中取得较好性能的MC-PixBiS方法在HQ-WMCA数据集上表现较差。这可能是因为数据库中的攻击具有挑战性。可以看出,提出的新的多头架构RGBD-MH-BCE已经改善了所有基线的结果,平均ACER达13.3±16.5。此外,随着CMFL损失的增加,ACER进一步提高到11.6±14.8%。实验结果表明,提出的体系结构已经提高了挑战攻击的性能,并且提出的损失进一步提高了HQ-WMCAdataSet中达到最先进水平的结果。
总而言之,新提出的多头架构本身比其他基线提高了性能。CMFLoss的添加进一步提高了WMCA和HQ-WMCA数据集中的性能。
3.6消融研究
为了进一步分析性能,我们使用所提出的方法进行了各种消融研究。我们在HQ-WMCA数据集中进行了这些实验,因为它包含了更具挑战性的攻击。
3.6.1 参数γ的影响
首先,我们使用不同的γ值进行实验,我们报告了HQ-WMCA数据集中所有攻击的平均值(值),以便进行比较。不同γ值的结果如表所示。可以看出,γ=3的最佳值。当γ=0时,模型相当于每个分支上的BCE损失。

3.6.2缺少通道的性能
其次,我们评估了在测试时仅用单通道评估模型的性能。考虑这样一个场景,其中模型使用RGB和深度进行训练,并且在测试时,只有一个通道可用。我们与HQ-WMCA数据集中的平均性能进行了比较,测试时仅使用RGB和深度。结果如表4所示。对于基线RGBD-MH-BCE,在测试时单独使用RGB的错误率为15.4±16.1,而对于所提出的方法,错误率提高到12.0±13.9。深度通道的性能也有所提高。
从表4可以清楚地看到,与使用BCE相比,即使在部署时使用单个通道,性能也有所提高。这表明当不可能通过该模态分类的样本的损失贡献减少时,系统的性能会改善。强迫单个网络学习决策边界会导致过度拟合,导致泛化能力较差。在所提出的方法中,网络还可以学习单个信道的鲁棒分类器。这种观察打开了在训练时使用多通道数据集以及仅为RGB通道部署模型的可能性。如果在部署时使用额外的硬件是令人望而却步的,需要使用传统的RGB摄像机来部署PAD系统,那么这可能具有实际意义。

3.6.3 对分数的详细分析
在此我们分析了所提出的模型在HQ-WMCA数据集上的grandtest-c协议中分数的分布。与LOO协议相反 ,grandtest-c协议由不同类型的攻击组成,这些攻击大致平均分布在训练、开发和评估的各个阶段。多头模型提供每个分支的三个不同分数,即RGB、深度和RGB-D分支。这里我们显示了不同类型攻击在HQ-WMCA数据集的评估集中的得分分布。

从图 5 可以看出,与深度通道相比,RGB 头部的攻击更加紧凑。在深度通道中,分类攻击更难,真实分布向左移动。这也可以从深度通道中攻击的分数分布中看出,即虽然攻击分数没有我们希望的那么低,但它远非真实,损失并没有推动深度分支对所有攻击进行正确分类,并且它在深度通道包含歧视性信息的攻击中表现良好。查看最后的“RGB-D”部分,可以看出所提出的损失函数使使用来自各个通道的联合表示的分类变得稳健。总而言之,所提出的框架鼓励各个分支为其他分支自信地分类的攻击产生不可信的分数。以这种方式学习的来自联合分支的判别式表示产生了强大的 PAD 系统。
3.6.4 跨数据集评估
为了评估跨数据库场景的鲁棒性,我们在 WMCA 和 HQ-WMCA 训练的模型之间进行了跨数据库实验。该评估同时涉及交叉传感器和看不见的攻击,这比典型的跨数据库评估更具挑战性。WMCA 数据库使用英特尔实感 SR300 摄像头,它返回 RGB 和深度流。 IntelRealsense SR300 使用点阵投影进行深度计算。而在 HQ-WMCA 中,RGB 通道是使用高质量的 Basler acA1921150uc 相机获取的,深度图像是使用 Intel RealSense D415(使用立体声计算深度)捕获的。
传感器之间的不匹配以及这些数据集中使用的传感器之间的质量会导致性能下降。跨数据集测试的结果列于表 5 中。模型在每个数据集的 Grandtest 协议上进行训练,并在另一个数据集的 dev和 eval数据集上进行评估。为了完整起见,我们报告了数据库内和跨数据库的性能。可以看出,在数据集内评估中,所提出的方法在两个数据集中都取得了良好的性能。但是,在跨数据库评估中,性能会下降。传感器之间的不匹配可能是性能下降的原因之一。当在 HQ-WMCA 中训练的模型在 WMCA 上进行评估时,性能略好,这可能是由于训练集中存在的攻击种类更多。此外,可以看出,在目标数据集中性能更好的方法在源数据集中性能更差。

3.7 讨论
从 WMCA 和 HQ-WMCA 的实验可以看出,所提出的方法优于最先进的方法。我们还表明,在训练时有多个通道可用以及需要部署单个通道的情况下,所提出的方法很有用。尽管所提出的方法在数据集内场景中运行良好,但跨数据库性能需要进一步改进。作为未来的工作,可以开发更多的预处理和数据增强策略来减轻数据集之间的差异,从而提高跨数据库性能。虽然我们为这项研究选择了 RGB 和深度通道,主要是因为由这些通道组成的现成设备的可用性,但将这项研究扩展到其他通道组合也是微不足道的,例如,RGB-红外,和RGB-热。
4 结论
在这项工作中,我们提出了一种新的RGBD表示攻击检测体系结构,该体系结构同样适用于其他多通道分类问题。此外,我们还提出了一种新的跨模式焦损函数,该函数可用于双流网络。提出的跨模式焦点损失函数基于单个通道的置信度来调整样本的损失贡献。所提出的框架可以简单地扩展到多个通道和不同的分类问题,其中仅来自一个通道的信息不足以用于分类。这种损失迫使网络学习分量信道的互补性、区别性和健壮性表示。该框架的结构使得使用所有可用通道训练模型以及使用通道子集进行部署成为可能。在两个公开可用的数据集中进行了广泛的评估,证明了所提出的方法的有效性。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)