文章目录
- 思维导图
- 疑问
-
- 概念区分
- 主流方法
- 损失函数
- Softmax loss
- 基于欧式距离的损失函数
- 对比损失(Contrastive Loss)
- 三元组损失(Triplet Loss)
- angular/cosine-margin-based loss
-
- 里程碑的论文
- DeepFace
- DeepID
- DeepID2
- FaceNet
- 参考
思维导图

在线的导图浏览:人脸识别思维导图
疑问
用softmax分类做人脸识别,怎么应用呀
在闭集上人数是定的,然后用softmax按照分类来训练模型。
在开集上用softmax之前的作为特征,用来比较特征向量之间的距离来确定是否为同一个人。
概念区分
人脸检测:是目标检测领域,给一张那个图片,框出里面人脸的位置
人脸对齐:是关键点检测,由人脸检测得到的人脸区域,进行关键点回归,得到描述五官的若干个关键点。
人脸识别:又包括人脸验证(一对一验证是否是同一个人)和人脸辨识(一对多,从一个数据库里搜索是否有这个人)
主流方法
人脸识别的流程:

首先,人脸检测器用于定位人脸,然后利用人脸对齐得到一个规范化的人脸,再经过活体检测,最后是人脸识别的方法。训练时选择一种网络结构和损失函数得到一个判别性强的模型,然后用于测试。
主要的思路:
在人脸识别领域,CNN网络结构主要用做表示学习,提取人脸的一个特征向量表示。随着新的backbone的出现而更新。关键的核心是怎么样得到一个具有判别性的向量表示,也就是说怎么让同一个人的不同图片的向量表示尽可能接近,而不同人的图片之间的向量表示尽可能远。所以人脸识别最重要的就是如何设计损失函数。目前,人脸识别已经超过人类水平,接近饱和了。
LFW数据集上的方法性能&架构&损失函数

损失函数
Softmax loss
softmax loss实际上就是softmax + 交叉熵损失
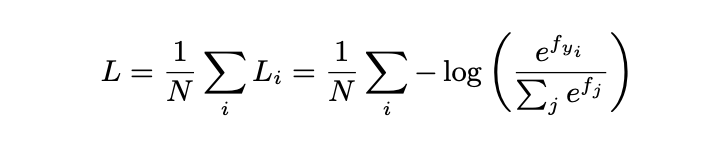
其中
f
f
f一般是最后的全连接层的输出
f
=
W
T
x
f=W^Tx
f=WTx,把它展开成模和角度的形式就是下面这种形式:
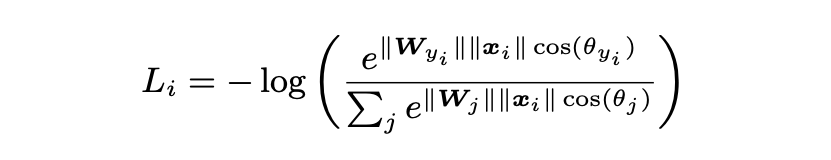
基于softmax loss用于人脸识别,是最初的方法。这种方法只能保证让组间具有区分性,对组内的约束很弱。
基于欧式距离的损失函数
对比损失(Contrastive Loss)
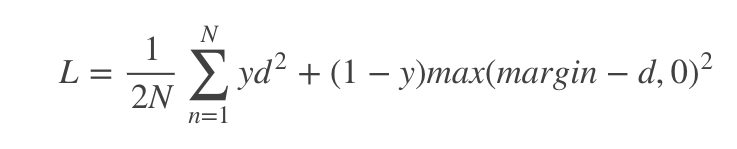
其中
d
=
∣
∣
a
n
−
b
n
∣
∣
2
d=||a_n−b_n||^2
d=∣∣an−bn∣∣2,代表两个样本特征的欧氏距离,y为两个样本是否匹配的标签,y=1代表两个样本相似或者匹配,y=0则代表不匹配,margin为设定的阈值。这样就能达到我们的扩大组间、距离缩小组内距离的目标。
三元组损失(Triplet Loss)
训练的三元组包括(A,P,N): Anchor, positive and negative. 训练的目的就是让Anchor和positive(属于同一个人)尽可能的近,而让Anchor和negative(不属于同一个人)尽可能的远。

angular/cosine-margin-based loss
L-softmax
基于上面的softmax loss的缺点,L-softmax增加了一个超参数m(代表分类的间隔):

当
m
=
1
m=1
m=1时,公式退化为softmax loss,随着
m
m
m越大,那么公式约束的margin就越大。达到增大组间距离的目的,进而使组内距离压缩。如下图所示:

里程碑的论文
DeepFace
DeepFace是CNN用于人脸识别的开山之作,主要在人脸对齐和人脸表示方面提出了新方法。
人脸对齐
论文使用的方法是基于基准点的3D建模方法,把人脸转为3D的正脸。这一步的作用就是使用3D模型来将人脸对齐,从而使CNN发挥最大的效果。
人脸表示
网络结构用了AlexNet的架构,loss是softmax,最终输出当前人脸属于哪个人的标签信息。

全连接层将上一层的每个单元和本层的所有单元相连,用来捕捉人脸图像不同位置的特征之间的相关性。其中,第7层(4096-d)被用来表示人脸。最后4030-d的输出是针对特定的SFC数据集的(有4030个人脸)。
DeepFace在LFW数据集上可以达到97.35%。
DeepFace与之后的方法的最大的不同点在于,DeepFace在训练神经网络前,使用了对齐方法。论文认为神经网络能够work的原因在于一旦人脸经过对齐后,人脸区域的特征就固定在某些像素上了,此时,可以用卷积神经网络来学习特征。
针对同样的问题,DeepID和FaceNet并没有对齐,DeepID的解决方案是将一个人脸切成很多部分,每个部分都训练一个模型,然后模型聚合。FaceNet则是没有考虑这一点,直接以数据量大和特殊的目标函数取胜。
DeepID
人脸表示
对一张人脸图像提取五官的patch加上不同的尺度和颜色总共得到60个不同的patch,送到60个如下图所示的卷积网络中(60个网络分别训练)得到60个2160维的向量(每个patch得到一个160维的向量,水平反转之后再得到一个160维的向量)。把这602*160的向量连接起来就是人脸的向量表示。

人脸验证
该部分的神经网络的输入是60组(前面60个ConvNets的输出),每一组640维,(人脸验证,需要输入两张人脸图片,来判定这两张人脸图片是不是来自同一个人),每一张face patch包括做侧面和右侧面,320维,故每一组共640维。采用Joint Bayesian 来进行人脸的验证。

缺点
DeepID2
DeepID2的创新点在于在学习特征的时候,该网络不仅考虑分类准确率,还考虑类间差距。具体的做法就是在目标函数中添加一项类间差距。该添加的创新就在于类间差距是在两个样本间进行衡量的,因而添加类间差距后,训练过程需要变化。
网络模型:

学习算法:

用人脸辩识(face identification)使模型学习到强的组间信息,尽可能区分不同的人。用人脸验证(face verification )尽可能缩小组内距离,让同一个人的表示更接近。
人脸辩识(face identification)的交叉熵损失:
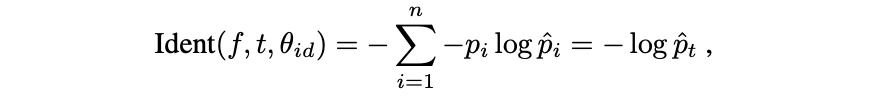
人脸验证(face verification )的对比损失(Contrastive Loss):
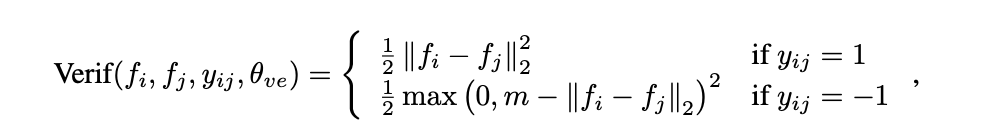
在LFW数据集上达到了 **99.15%**的性能。
优点:
- 组合使用了交叉熵损失和对比损失,使组内距离尽可能的小
FaceNet
网络模型用了ZFNet或GoogLeNet,训练的时候用三元组的损失函数。测试的时候输出最终的向量表示,用来计算和其他图片的距离。

主要才用了triple loss,选择一个图片Anchor,Positive和Anchor来自同一个人的不同图片,Negative和Anchor来自不同的人。模型训练的目标就是让A和P之间尽可能的小,而A和N之间尽可能的大

关键的细节
三元组的选择对模型的收敛非常重要,怎么选择三元组?每次都应该挑选hard positive(同一个人中与Anchor最不相似的图片)和 hard negative(不同人中和Anchor最相似的图片),实际上每次都是挑选的semi-hard example(以防止在训练中很快地陷入局部最优)。
优点:
- 该模型的优点是只需要对图片进行很少量的处理(只需要裁剪脸部区域,而不需要额外预处理,比如3d对齐等),即可作为模型输入。同时,该模型在数据集上准确率非常高。
- FaceNet并没有像DeepFace和DeepID那样需要对齐。
- FaceNet得到最终表示后不用像DeepID那样需要再训练模型进行分类,直接计算距离就好了,简单而有效。
- 采用了三元组损失函数
参考
https://zhuanlan.zhihu.com/p/34404607
Deep Face Recognition: A Survey
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)