论文简介
本文主要介绍CMU在2016年发表在ACL的一篇论文:Hierarchical Attention Networks for Document Classification及其代码复现。
该论文是用于文档级情感分类(document-level sentiment classification)的,其模型架构如下:

该模型称为层次注意力模型(Hierarchical Attention Network),根据作者所述,
-
层次是指:句子由单词组成,文档由句子组成,据此可以构建一个自下而上的层次结构。
-
注意力是指:组成某个句子的单词对该句子的情感倾向的贡献是不同的,通常来说,形容词的贡献(如good)就比名词(如book)更大;同理,组成文档的句子对该文档的情感倾向的贡献也不同,例如某些句子可能仅仅是陈述事实,而另一些句子则很明显地表达出了自己的观点。据此,作者提出使用注意力机制来挖掘句子和文档中对情感分类比较重要的部分(btw,注意力机制比较成熟的最早的应用是Google发表的Attention is All you Need一文中)。
对词嵌入进行编解码的方式无非是双向GRU或CNN等,此处不再赘述。需要注意的是,该模型中的注意力机制分为两个部分,分别是word attention和sentence attention,即分别在单词和句子上应用注意力机制,可视化结果如下:

可以看出注意力机制的可视化结果高亮出了情感极性比较强的单词。例如左边带delicious的评论预测结果为4分(较好),带terrible的评论的预测结果为0分(极差)。
由此也可说明注意力机制是有效的。
代码复现及重构
(显然这篇几年前的论文的代码不是我写的)
本文参考了github上对该模型的复现代码:textClassifier,源代码就不详细解释了,稍有复杂的也就是数据处理部分,源码实现将训练data设为三维的,并在词嵌入后喂给了HAN模型。
考虑到源代码结构不是很清晰,也无法自定义输入的词嵌入的维度和训练数据集,因此本文对该代码进行了重构。
首先说明Python版本和依赖的库:
Python >= 3.6
numpy
pandas
re
bs4
pickle
sklearn
gensim
nltk
keras
tensorflow
Python版本需要大于3.6,至于其他库的话,只要版本不太落后一般都没问题
下面详细介绍改动的部分。
参数选项
原文没有提供参数选项,如果要输入不同维度的词嵌入文件,则每次都要修改源代码,十分不便,为此, 我在重构时加入了参数选项,主要代码如下:
parser = argparse.ArgumentParser('HAN')
parser.add_argument('--full_data_path', '-d',
help='Full path of data', default=FULL_DATA_PATH)
parser.add_argument('--processed_pickle_data_path', '-D',
help='Full path of processed pickle data', default=PROCESSED_PICKLE_DATA_PATH)
parser.add_argument('--embedding_path', '-s',
help='The pre-trained embedding vector', default=EMBEDDING_PATH)
parser.add_argument('--model_path', '-m', help='Full path of model', default=MODEL_PATH)
parser.add_argument('--epoch', '-e', help='Epochs', type=int, default=EPOCH)
parser.add_argument('--batch_size', '-b', help='Batch size', type=int, default=BATCH)
parser.add_argument('--training_data_ready', '-t',
help='Pass when training data is ready', action='store_true')
parser.add_argument('--model_ready', '-M',
help='Pass when model is ready', action='store_true')
parser.add_argument('--verbosity', '-v',
help='verbosity, stackable. 0: Error, 1: Warning, 2: Info, 3: Debug', action='count')
parser.description = 'Implementation of HAN for Sentiment Classification task'
parser.epilog = "Larry King@https://github.com/Larry955"
相应的变量定义在han_config.py文件中。
详细参数说明如下:
- –full_data_path, 要输入的训练文件的路径,该文件必须为tsv格式
- –processed_pickle_data_path, 已经处理过的数据集的路径
- –embedding_path, 预训练词向量文件的路径
- –model_path, 保存的模型的路径
- –epoch, epoch个数
- –batch_size, batch size
- –training_data_ready, 数据集是否已被处理过,显式输入该参数时表明数据集已被处理过,否则会报错
- –model_ready, 模型是否已保存好,显式输入该参数时表明模型已被保存,否则会报错
- –verbosity, emmmm…
假设该文件为HAN. py,那么输入
python HAN.py --help
可得:
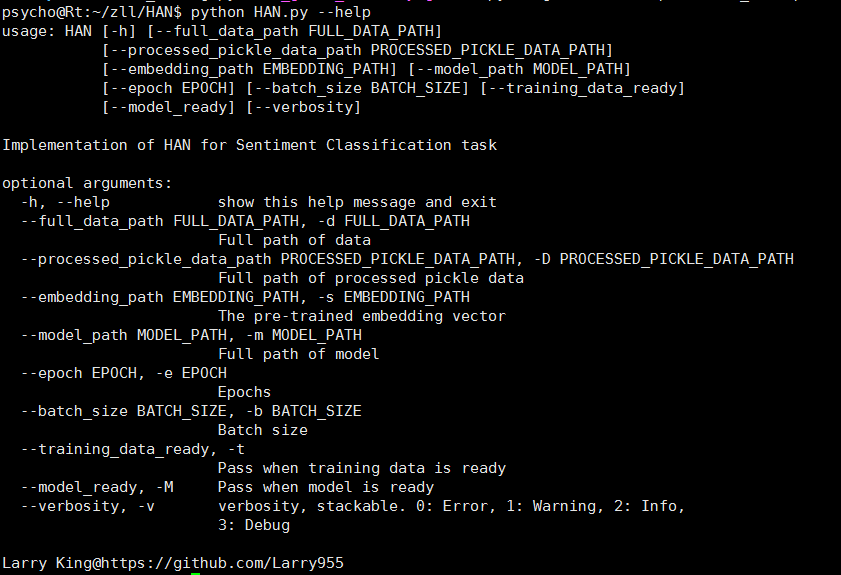
输入
python HAN.py --full_data_path=train_data.tsv --embedding_path=GoogleNews-vectors-negative300.bin --epoch=20
表示数据集的路径为train_data.tsv,预训练词嵌入文件为GoogleNews,epoch为20。
输入
python HAN.py --training_data_ready --model_ready
表示训练集和模型都已经准备好,可以直接加载。
词嵌入文件解析
原代码中只能解析glove词嵌入,并且词嵌入维度固定300维,我在重构时对词嵌入文件进行了简单的解析,使得模型可以接受不同的词嵌入文件(目前支持glove和GoogleNews两种),并能根据文件名提取出词嵌入的维度。主要代码如下:
emb_file_flag = ''
embedding_dim = 0
if embedding_path.find('glove') != -1:
emb_file_flag = 'glove' # pre-trained word vector is glove
embedding_dim = int(((embedding_path.split('/')[-1]).split('.')[2])[:-1])
elif embedding_path.find('GoogleNews-vectors-negative300.bin') !=
-1:
emb_file_flag = 'google' # pre-trained word vector is GoogleNews
embedding_dim = 300
得到词嵌入文件和维度后,再根据emb_file_flag针对不同的文件获取词向量:
embeddings_index = {}
if emb_file_flag == 'glove':
f = open(os.path.join(embedding_path), encoding='utf-8')
for line in f:
values = line.split()
word = values[0]
vec = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = vec
f.close()
elif emb_file_flag == 'google':
wv_from_bin = KeyedVectors.load_word2vec_format(emb_path,
binary=True)
for word, vector in zip(wv_from_bin.vocab, wv_from_bin.vectors):
vec = np.asarray(vector, dtype='float32')
embeddings_index[word] = vec
示例:
python HAN.py --embedding_path=GoogleNews-vectors-negative300.bin # pre-trained word vector file is GooleNews with 300d
python HAN.py --embedding_path=glove.6B.100d.txt # pre-trained file is glove with 100d
python HAN.py --embedding_path=glove.6B.200d.txt # 200d
保存已训练数据集及模型
原代码中,每次运行时都要对数据集进行处理,并且要重新训练模型,这对于百万级文档数据集而言十分耗时,为此,我在重构时设置了相应的参数选项,从而能通过直接加载保存的文件已避免多次训练,大大降低训练时间。代码如下:
if is_training_data_ready:
with open(pickle_path, 'rb') as f:
# print('data ready')
data, labels, word_index = pickle.load(f)
f.close()
else:
data, labels, word_index = process_data(data_path)
with open(pickle_path, 'wb') as f:
pickle.dump((data, labels, word_index), f) # save trained dataset
f.close()
# Generate data for training, validation and test
x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.1, random_state=1)
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.1, random_state=1)
if is_model_ready:
# print('model ready')
model = load_model(model_path, custom_objects={'AttLayer':
AttLayer})
else:
# Generate embedding matrix consists of embedding vector
embedding_matrix = create_emb_mat(embedding_path, word_index,
embedding_dim) # Create model for training
model = create_model(embedding_matrix)
model.save(model_path) # save model
需要说明的是,由于该模型中自定义了不在keras.layers中的层(AttLayer),因此直接load_model时会报错:github:keras/issues/#8612,为解决该问题,可参考我的另一篇博客:
使用keras调用load_model时报错ValueError: Unknown Layer:LayerName
添加函数和程序入口
原代码中只有一个数据预处理函数clean_str和一个类AttLayer,其余部分混杂其间,导致代码结构混乱,不易理解,为此,我在重构时将各项功能以函数形式封装,并添加主程序入口和注释,大大提升了代码的可读性。此处不再赘述。
实验结果
这是在IMDB二分类数据集上进行的实验,共25000条评论,train/val/test的划分为8/1/1,epoch为10,优化函数为rmsprop。
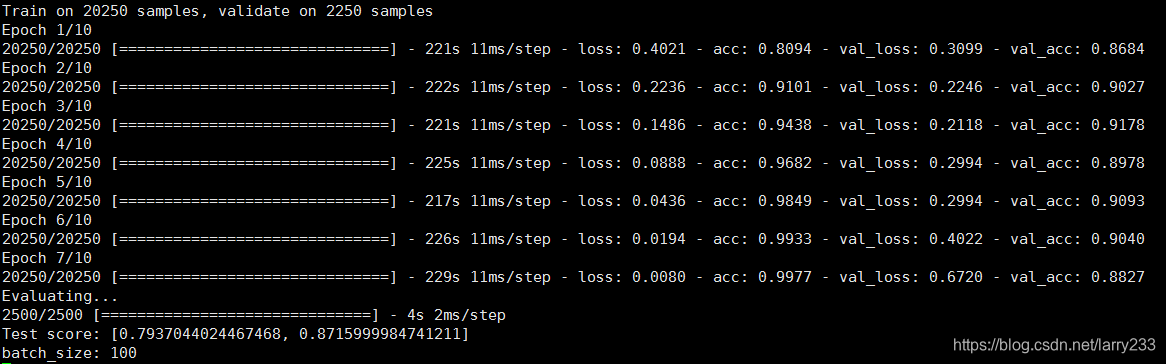
总结
这次重构基本把原代码核心功能(模型相关代码、注意力层AttLayer)以外的部分改得面目全非了,添加了上述功能后,跑模型时可以输入自己想要的信息,避免在源代码上进行修改,具有更高的弹性和可读性,和原来相比好了很多。重构后的代码见my github-HAN
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)