作者:潘星宇 (清华大学)
Stata 连享会:知乎 | 简书 | 码云 | CSDN
 连享会-内生性专题现场班-2019.11.14-17
连享会-内生性专题现场班-2019.11.14-17

特别说明
文中包含的链接在微信中无法生效。请点击本文底部左下角的【原文链接】。
空间计量方法已经成为了时下最为热门和常用的计量方法之一,而空间权重矩阵的构建则是运用空间计量方法时必不可少的“标准动作”。但在实际研究过程中,我们往往会遇到很多问题。例如,目前网络上能获取到的矩阵与我研究的样本不匹配;例如,做回归时时需要剔除一些样本单位,但如何构建与之对应的空间权重矩阵;再例如,如何构建一些广义上的“空间”权重矩阵,等等。本期我们就来和大家一起了解一下权重矩阵的构建。
1. 空间权重矩阵原理简介
通常定义一个二元对称空间权重矩阵来表达 n 个位置的空间个体(例如区域)的邻近关系:
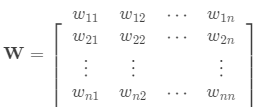
理论上讲,不存在最优的空间矩阵,即无法找到一个完全描述空间相关结构的空间矩阵。空间矩阵的构造必须满足 「空间相关性随着 ‘距离’ 的增加而减少」的原则。
需要注意的是。在空间计量中,“距离(counterfacutal) ” 的定义可以是广义的,包含但不限于地理上的相邻或者欧氏距离,也可以是经济意义上合作关系的远近,甚至可以是社会学意义上的人际关系的亲疏。
1.1 简单空间权重矩阵
最简单的空间权重矩阵是所谓的「二进制空间权重矩阵」,使用 0 和 1 来标记个体之间的空间相邻情况,属于 定性 界定。
简单二进制邻接矩阵
简单的二进制邻接矩阵的第 i 行第 j 列元素为:
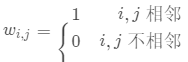
基于距离的二进制空间权重矩阵
这类空间权重矩阵的第 i 行第 j 列元素为:

广义「相邻」概念的二进制空间权重矩阵
如前文所述 “相邻” 可以有不同的定义。一般来说从最基本的空间概念出发,有 Rook 相邻 、Queen 相邻 等。Rook 相邻指的有一段共同的边即认为两个单位相邻,Queen 相邻认为只要存在顶点相接,就认为两地区为 "邻居" 关系。此外还可以定义成二者 是否有相同方言 、是否同属于一个城市群 ,等等。

1.2 基于距离的空间权重矩阵形式
若考虑距离的相对大小,想要从「定量」角度刻画空间相邻性,可以使用如下权重定义方法:
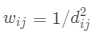
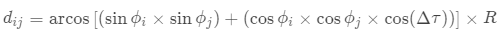
其中: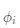 和
和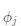 分别表示某个省份(比如地理几何中心,省会(首府)) 的纬度和经度;
分别表示某个省份(比如地理几何中心,省会(首府)) 的纬度和经度;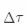 为两个省份间经度之差;R 为地球半径,等于 3958.761 英里。在实际应用中,常对空间权重矩阵进行行标准化,空间权重矩阵的对角元素设为 0。
为两个省份间经度之差;R 为地球半径,等于 3958.761 英里。在实际应用中,常对空间权重矩阵进行行标准化,空间权重矩阵的对角元素设为 0。
2. 空间权重矩阵构建的准备工作
要构建自己 “定制的” 空间权重矩阵,首先需要获得所研究空间单元的地理位置信息文件,以便于 Stata 判断相对或者绝对地理位置。这些信息通常来自于对研究单元对象的 ESRI Shapefile 文件(也就是 Stata 绘制地图时需要的所谓 “底图” 文件)。中国的 shapefile 文件包括省级,市级和县级等各个层面的数据,可以在国家基础信息中心申请下载,或者从一些公开的网络资源获取。
本文采用中国省级行政区 shapefile 作为演示数据。
一个完整的 shapefile 文件由以下几个文件组成:
省级行政区.dbf
省级行政区.shp
省级行政区.shx
省级行政区.prj
省级行政区.shx
2.1 编辑 shapefile 文件
目前,Stata 中还没有能对 shapefile 文件进行编辑的命令。这一步骤一般采用 ArcGIS 或 arcview 等软件来进行。由于这一步非常重要,因此我们以 ArcGIS 软件为例,做一个简单的演示。
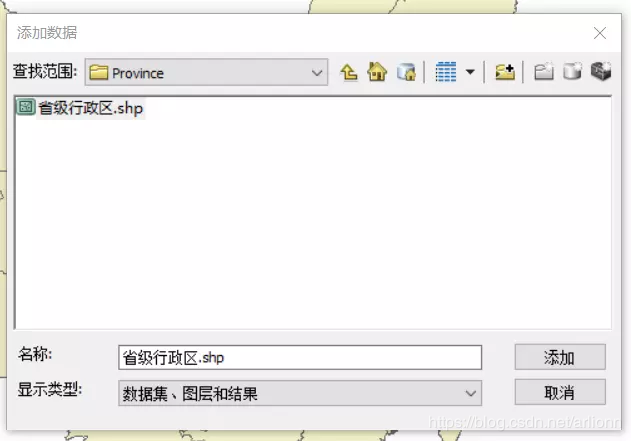
第一步:导入 shpefile 文件
在 ArcGIS 主界面中,点击下图中红圈所示的图标,然后按提示选择硬盘上存储的 shpefile 文件,即可将其导入 ArcGIS。
第二步:编辑 shpefile 文件
这里假设我们的研究对象不含西藏自治区、香港特别行政区、澳门特别行政区以及台湾省,我们就需要在编辑器当中把这四个要素删除。
首先选中图层,右键菜单中选择 “开始编辑”,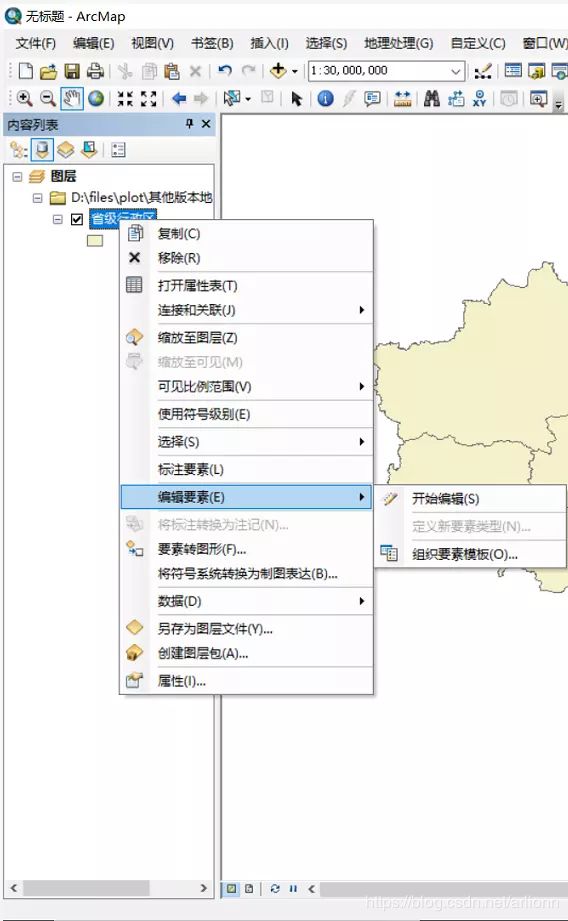
右键图层打开属性表,删除上面提到的四个要素:
第三步:导出 shapefile 文件
再右键图层,选择 导出数据 :
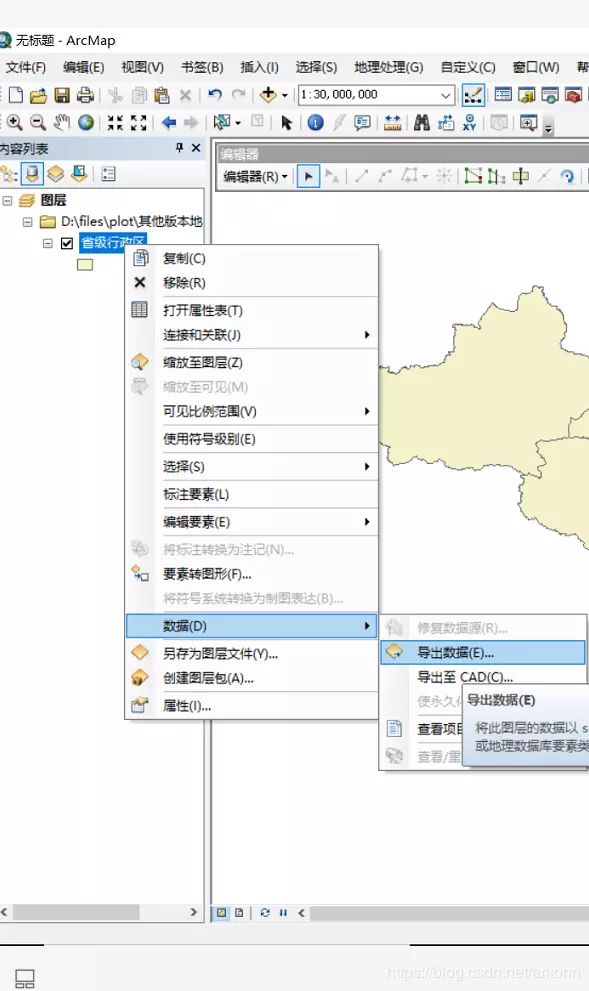
这样,我们就有了符合我们需要的空间权重矩阵构建的 shapefile 文件,下面就需要将其导入 Stata 以便做后续分析了。
2.2 在 Stata 中导入 shapefile 文件
若采用空间面板数据模型进行建模,则还需要找出这些省份的经纬度等地理信息。前文已经说明了如何下载 shapefile 文件,该文件中即包含了各个国家的地理信息。那么可以将研究单元数据和 shapefile 进行合并。这里需要用到 mif2dta 或 shp2dta 命令来读取 shapefile 文件。该命令为外部命令,安装方式参考「 Stata: 外部命令的搜索、安装与使用」 。需要注意的是, 只有经纬度信息的数据集不能用于二项式空间权重矩阵的构建 ,关于这一点我们将在下文中说明。
这一过程主要是将 .shp 格式的文件编译成stata可以读取的文件,主要采用 shp2dta 命令完成。
我们来看看 shp2dta 命令的基本语法:
. shp2dta using shpfilename, ///
database(filename) coordinates(filename) ///
genid(newvarname) gencentroids(stub)
其中,
coordinates(filename) 指定包含 .shp 文件数据的新 Stata 数据集的名称。
database(filename) 指定包含 .dbf 文件数据的新 Stata 数据集的名称。
genid(newvarname) 指定新数值变量的名称,该数字变量在文件 database.dta 中将唯一标识感兴趣的不同地理区域。newvarname 采用的值将对应于文件 coordinates.dta 中变量 _ID 所采用的值。
gencentroids(stub) 选项可以计算出地理区域的质心的坐标,存储在变量 x_stub 和 y_stub 中,并添加到文件 database.dta 中。但我们还必须指定 genid(newvarname) 选项。
. shp2dta using "C:\Users\xypan\Desktop\连享会推文\空间权重矩阵的构建\空间权重矩阵底图\30个省市自治区.shp", ///
database(data_db) coordinates(data_xy) ///
genid(weightid) gencentroids(stub) replace
. use data_db, clear
. rename NAME province
. list province x_stub y_stub in 1/10
+------------------------------+
| province x_stub y_stub |
|------------------------------|
1. | 黑龙江 47.8418 127.725 |
2. | 新疆 41.112 85.2009 |
3. | 山西 37.5698 112.263 |
4. | 宁夏 37.2681 106.158 |
5. | 山东 36.3217 118.107 |
6. | 河南 33.8743 113.581 |
7. | 江苏 32.9807 119.42 |
8. | 安徽 31.8229 117.197 |
9. | 湖北 30.9677 112.239 |
10. | 浙江 29.1659 120.023 |
+------------------------------+
读取 shapefile 文件后,可以发现有 x_stub 和 y_stub 两个变量,分别代表了对应省份的的地理坐标。
接下来将带有地理坐标的 data_db.dta 文件和我们的数据文件匹配起来,命名为 spatialweight_province.dta:
merge 1:m province using "C:\Users\xypan\Desktop\连享会推文\空间权重矩阵的构建\省级数据.dta"
keep if _merge==3
drop _merge
save "C:\Users\xypan\Desktop\连享会推文\空间权重矩阵的构建\spatialdata_province.dta", replace
到此我们完成了几乎所有的准备工作,下一步开始正式构建空间权重矩阵。
3 空间权重矩阵的构建
3.1 命令说明
生成距离空间权重矩阵的命令语法为
spwmatrix gecon varlist [if] [in], ///
wname(wght_name) [wtype(inv) cart r(#) ///
dband(numlist) alpha(#) knn(#) ///
econvar(varname1) beta(#) Other_options]
主要选项的含义如下:
wname(wght_name) 表示要生成的空间权重矩阵的名称
wtype(bin | inv | econ | invecon | socnet | socecon) 分别代表二进制,距离衰减,经济距离,逆经济距离,社会网络或社会经济空间权重
dta 选择该选项以从 .dta 文件导入空间权重
text 选择该选项以从逗号或制表符分隔的文本文件导入空间权重
swm(idvar_name) 导入 ArcGIS 中生成的空间权重
knn(#) 请求最近邻空间权重
econvar(varname1) 可用此选项构建经济或逆经济距离空间权重
beta(#) 指定指数函数的系数 β; 默认测试版 (1)
cart 表示纬度和经度采用笛卡尔坐标,这是默认选项 (一般我们也使用的是这个);如果采用球面坐标则只能选择 r(#),此时不能同时选择 cart,并且需要指定地球半径距离(英里),一般默认填写 r(3958.761);
dband(numlist) 表示最大的权重矩阵边界,其中的 numlist 表示确定边界的变量,一般是各省份代码的最大值;
alpha(#) 表示参数限制范围,默认为 alpha(1) ;
3.2 反距离空间权重矩阵
use spatialdata_province.dta,clear
spwmatrix gecon x_stub y_stub , wn(spatialweight_province) wtype(inv) cart alpha(1)
xport(spatialweight_province,txt) row replace \\生成名为 spatialweight_province 的权重矩阵
spmat import spatialweight_province using spatialdata_province.txt,replace \\导入 spatialweight_province 权重矩阵
spmat save spatialweight_province using spatialweight_pro.spmat,replace //将生成的 spmat 权重文件存储为spatialweight_pro
spmat use spatialweight_pro using spatialweight_pro.spmat,replace //打开 spmat 权重文件
matrix list spatialweight_pro //查看 spatialweight_pro 权重矩阵
这样,反距离空间权重矩阵就生成了,由于矩阵展开太大,囿于篇幅限制这里不做展示。
3.3 经济距离空间权重矩阵
经济距离矩阵的计算公式为
use spatialdata_province.dta,clear
spwmatrix gecon x_c y_c, wn(province) wtype(invecon) cart econvar(GDP_2000) rowstand xport(spatialdata_province,txt) replace\\由于选择的是 invecon(经济反距离矩阵)因此需要声明相应的经济变量
spmat import spatialweight_province using spatialdata_province.txt,replace //生成以spatialweight_province 为名称的 spmat 权重文件
其他导入、存储和查看方法同上,不再赘述。
3.4 地理相邻空间权重矩阵
构建地理相邻空间权重矩阵时,之前计算的含有地理坐标的 spatialdata_province.dta 文件将不再适用,需要将我们编辑好的 .shp 文件导入 Geoda 软件,再导出 .gal 文件,再使用 spwmatrix 命令进行编译即可使用。导入过程非常简单,故在此略过。
use spatialdata_province.dta,clear
spwmatrix import using C:\连享会推文\空间权重矩阵的构建\空间权重矩阵底图\spatialdata_province.gal,wname(wcontig) xport(spatialdata_province, dat) \\.gal 只能导出 .dat (不是 .dta,.dat 是 R 语言中一种通用的文件格式)格式的文件
spmat import spatialweight_province using spatialdata_province.dat,replace
其他导入、存储和查看方法同上。
3.5 广义的 “相邻” 空间权重矩阵
这里我们采用文章开头提到过的二者是否有相同方言,我们采用徐现祥老师公布的方言数据,将方言赋值(因为 spmatrix 命令无法识别字符型变量),官话赋值为1,吴语赋值为2,以此类推。同属于一个方言区的省份我们赋值为1,不同的我们赋值为0.
use fangyan.dta, clear
spwmatrix socio fangyan_id, wname(fangyan) wtype(socnet) idvar(provinceid) xport(spatialdata_province,txt) \\fangyan_id代表我们的方言代理哑变量
其他导入、存储和查看方法同上。
4. 结语
在完成了权重矩阵的构建后,就可以用它进行空间计量回归了,具体的操作可以参考我们的推文「Stata: 空间面板数据模型及Stata实现」 。
另外需要注意的是 ArcView 、 ArcGIS软件 和 MATLAB 软件也可以进行空间权重矩阵的构建,我们也看到了甚至一些关键步骤也必须经过这些个软件的操作(也有其他软件,在此不一一列举)。对这方面有兴趣的同学可以选择性地学习一下。其中 ArcView 相对更加轻量,不像后两种软件动辄 10G 大小。
目前 Stata 15.x 版本中发布的 xsmle 等命令可以也支持多个空间权重矩阵的回归。
参考文献
Jeanty, P.W., 2010. spwmatrix: Stata module to generate, import, and export spatial weights. Available from.
相关推文
游万海,连玉君. Stata: 外部命令的搜索、安装与使用.
游万海,连玉君. Stata: Stata: 空间面板数据模型及Stata实现.
Stata:空间计量之用 spmap 绘制地图
Stata: 空间计量溢出效应的动态GIF演示
Stata:空间计量之 SP 系列命令
往期精彩推文集锦
Stata连享会推文集锦
连享会推文:Stata资源汇总
连享会推文:数据处理与程序
连享会推文:回归分析-模型设定-内生性
连享会推文:时间序列+面板数据
连享会推文:绘图

关于我们
Stata连享会 由中山大学连玉君老师团队创办,定期分享实证分析经验。
公众号推文同步发布于 CSDN 、简书 和 知乎Stata专栏。可在百度中搜索关键词 「Stata连享会」查看往期推文。
欢迎赐稿: 欢迎赐稿。录用稿件达 三篇 以上,即可 免费 获得一期 Stata 现场培训资格。
E-mail: StataChina@163.com
计量专题:因为专注,所以专业
往期精彩推文:一网打尽
