前言
中断分为硬件中断,软件中断。中断的处理原则主要有两个:一个是不能嵌套,另外一个是越快越好。在Linux中,分为中断处理采用“上半部”和“下半部”处理机制。
一、中断处理“下半部”机制
中断服务程序一般都是在中断请求关闭的条件下执行的,以避免嵌套而使中断控制复杂化。但是,中断是一个随机事件,它随时会到来,如果关中断的时间太长,CPU就不能及时响应其他的中断请求,从而造成中断的丢失。
因此,Linux内核的目标就是尽可能快的处理完中断请求,尽其所能把更多的处理向后推迟。例如,假设一个数据块已经达到了网线,当中断控制器接受到这个中断请求信号时,Linux内核只是简单地标志数据到来了,然后让处理器恢复到它以前运行的状态,其余的处理稍后再进行(如把数据移入一个缓冲区,接受数据的进程就可以在缓冲区找到数据)。
因此,内核把中断处理分为两部分:上半部(top-half)和下半部(bottom-half),上半部 (就是中断服务程序)内核立即执行,而下半部(就是一些内核函数)留着稍后处理。
首先:一个快速的“上半部”来处理硬件发出的请求,它必须在一个新的中断产生之前终止。通常,除了在设备和一些内存缓冲区(如果你的设备用到了DMA,就不止这些)之间移动或传送数据,确定硬件是否处于健全的状态之外,这一部分做的工作很少。
第二:“下半部”运行时是允许中断请求的,而上半部运行时是关中断的,这是二者之间的主要区别。
内核到底什么时候执行下半部,以何种方式组织下半部?
这就是我们要讨论的下半部实现机制,这种机制在内核的演变过程中不断得到改进,在以前的内核中,这个机制叫做bottom-half(以下简称BH)。但是,Linux的这种bottom-half机制有两个缺点:
- 在任意一时刻,系统只能有一个CPU可以执行BH代码,以防止两个或多个CPU同时来执行BH函数而相互干扰。因此BH代码的执行是严格“串行化”的。
- BH函数不允许嵌套。
这两个缺点在单CPU系统中是无关紧要的,但在SMP系统中却是非常致命的。因为BH机制的严格串行化执行显然没有充分利用SMP系统的多CPU特点。为此,在2.4以后的版本中有了新的发展和改进,改进的目标使下半部可以在多处理机上并行执行,并有助于驱动程序的开发者进行驱动程序的开发。下面主要介绍3种5.4内核中的“下半部”处理机制:
- 软中断请求(softirq)机制
- 小任务(tasklet)机制
- 工作队列机制
- threaded_irq机制
以上三种机制的比较如下图所示
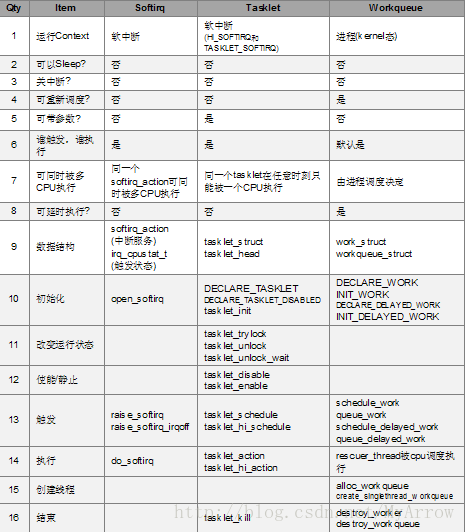
二、软中断请求(softirq)机制
Linux的softirq机制是与SMP紧密不可分的。为此,整个softirq机制的设计与实现中自始自终都贯彻了一个思想:“谁触发,谁执行”(Who marks,Who runs),也即触发软中断的那个CPU负责执行它所触发的软中断,而且每个CPU都有它自己的软中断触发与控制机制。这个设计思想也使得softirq机制充分利用了SMP系统的性能和特点。
2.1 软中断描述符
Linux在include/linux/interrupt.h头文件中定义了数据结构softirq_action,来描述一个软中断请求,如下所示:
enum
{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
BLOCK_SOFTIRQ,
IRQ_POLL_SOFTIRQ,
TASKLET_SOFTIRQ,
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ,
NR_SOFTIRQS
};
extern const char * const softirq_to_name[NR_SOFTIRQS];
struct softirq_action
{
void (*action)(struct softirq_action *);
};
asmlinkage void do_softirq(void);
asmlinkage void __do_softirq(void);
其中,函数指针action指向软中断请求的服务函数。基于上述软中断描述符,Linux在kernel/softirq.c文件中定义了一个全局的softirq_vec数组:
static struct softirq_action softirq_vec[NR_SOFTIRQS] __cacheline_aligned_in_smp;
在这里系统一共定义了10个软中断请求描述符。软中断向量i(0≤i≤9)所对应的软中断请求描述符就是softirq_vec[i]。这个数组是个系统全局数组,即它被所有的CPU所共享。这里需要注意的一点是:每个CPU虽然都有它自己的触发和控制机制,并且只执行他自己所触发的软中断请求,但是各个CPU所执行的软中断服务例程却是相同的,也即都是执行softirq_vec[ ]数组中定义的软中断服务函数。Linux在kernel/softirq.c中的相关代码如下:
#ifndef __ARCH_IRQ_STAT
DEFINE_PER_CPU_ALIGNED(irq_cpustat_t, irq_stat);
EXPORT_PER_CPU_SYMBOL(irq_stat);
#endif
static struct softirq_action softirq_vec[NR_SOFTIRQS] __cacheline_aligned_in_smp;
DEFINE_PER_CPU(struct task_struct *, ksoftirqd);
const char * const softirq_to_name[NR_SOFTIRQS] = {
"HI", "TIMER", "NET_TX", "NET_RX", "BLOCK", "IRQ_POLL",
"TASKLET", "SCHED", "HRTIMER", "RCU"
};
2.2 软中断触发机制
要实现“谁触发,谁执行”的思想,就必须为每个CPU都定义它自己的触发和控制变量。为此,Linux在\Linux-5.4\arch\arm\include\asm\hardirq.h头文件中定义了数据结构irq_cpustat_t来描述一个CPU的中断统计信息,其中就有用于触发和控制软中断的成员变量。数据结构irq_cpustat_t的定义如下:
IPI: 处理器间的中断(Inter-Processor Interrupts)
#define NR_IPI 7
typedef struct {
unsigned int __softirq_pending;
#ifdef CONFIG_SMP
unsigned int ipi_irqs[NR_IPI];
#endif
} ____cacheline_aligned irq_cpustat_t;
#define __inc_irq_stat(cpu, member) __IRQ_STAT(cpu, member)++
#define __get_irq_stat(cpu, member) __IRQ_STAT(cpu, member)
#define __IRQ_STAT(cpu, member) (irq_stat[cpu].member)
DECLARE_PER_CPU_ALIGNED(irq_cpustat_t, irq_stat);
#define __IRQ_STAT(cpu, member) (per_cpu(irq_stat.member, cpu))
#define DECLARE_PER_CPU_SECTION(type, name, sec) \
extern __PCPU_ATTRS(sec) __typeof__(type) name
#define DECLARE_PER_CPU_ALIGNED(type, name) \
DECLARE_PER_CPU_SECTION(type, name, PER_CPU_ALIGNED_SECTION) \
____cacheline_aligned
展开可得到以下定义:
irq_cpustat_t irq_stat[NR_CPUS] ____cacheline_aligned;
其中:
- NR_CPUS,为系统中CPU个数。
- 这样,每个CPU都只操作它自己的中断统计信息结构。假设有一个编号为id的CPU,那么它只能操作它自己的中断统计信息结构irq_stat[id](0≤id≤NR_CPUS-1),从而使各CPU之间互不影响。
使用open_softirq()函数可以注册软中断对应的处理函数,而raise_softirq()函数可以出发一个软件中断。
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
softirq_vec[nr].action = action;
}
void raise_softirq(unsigned int nr)
{
unsigned long flags;
local_irq_save(flags);
raise_softirq_irqoff(nr);
local_irq_restore(flags);
}
raise_softirq_irqoff函数:
inline void raise_softirq_irqoff(unsigned int nr)
{
__raise_softirq_irqoff(nr);
if (!in_interrupt())
wakeup_softirqd();
}
通过in_interrupt判断现在是否在中断上下文中,或者软中断是否被禁止,如果都不成立,我们必须要调用wakeup_softirqd函数用来唤醒本CPU上的softirqd这个内核线程。
2.3 初始化软中断
void __init softirq_init(void)
{
int cpu;
for_each_possible_cpu(cpu) {
per_cpu(tasklet_vec, cpu).tail =
&per_cpu(tasklet_vec, cpu).head;
per_cpu(tasklet_hi_vec, cpu).tail =
&per_cpu(tasklet_hi_vec, cpu).head;
}
open_softirq(TASKLET_SOFTIRQ, tasklet_action);
open_softirq(HI_SOFTIRQ, tasklet_hi_action);
}
2.4 软中断服务的执行及处理
2.4.1 在中断返回现场调度__do_softirq
在中断处理程序中触发软中断是最常见的形式,一个硬件中断处理完成之后。下面的函数在处理完硬件中断之后退出中断处理函数,在irq_exit中会触发软件中断的处理。
中断处理模型:
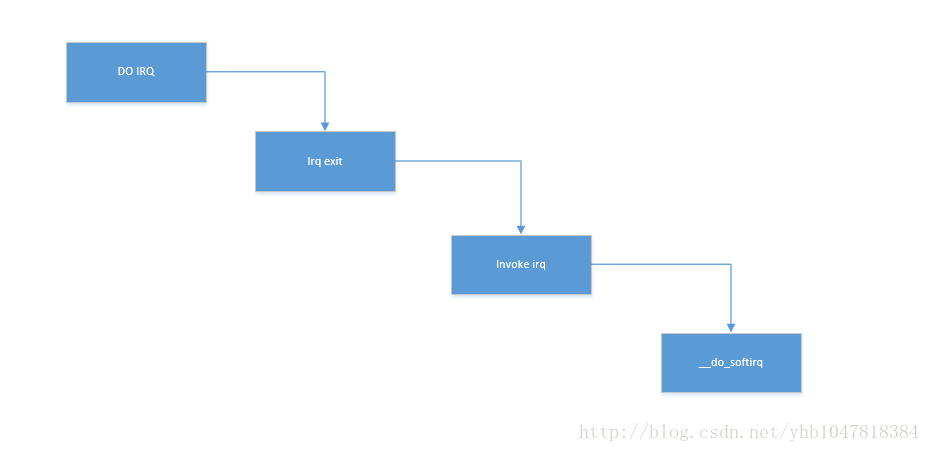
硬中断处理过程:
fastcall unsigned int do_IRQ(struct pt_regs *regs)
{
...
irq_enter();
...
irq_exit();
return 1;
}
硬中断处理完毕后会执行irq_exit()函数
void irq_exit(void)
{
#ifndef __ARCH_IRQ_EXIT_IRQS_DISABLED
local_irq_disable();
#else
lockdep_assert_irqs_disabled();
#endif
account_irq_exit_time(current);
preempt_count_sub(HARDIRQ_OFFSET);
if (!in_interrupt() && local_softirq_pending())
invoke_softirq();
tick_irq_exit();
rcu_irq_exit();
trace_hardirq_exit();
}
在irq_exit()函数中会调用invoke_softirq函数
static inline void invoke_softirq(void)
{
if (ksoftirqd_running(local_softirq_pending()))
return;
if (!force_irqthreads) {
#ifdef CONFIG_HAVE_IRQ_EXIT_ON_IRQ_STACK
__do_softirq();
#else
do_softirq_own_stack();
#endif
} else {
wakeup_softirqd();
}
}
函数do_softirq()负责执行数组softirq_vec[i]中设置的软中断服务函数。每个CPU都是通过执行这个函数来执行软中断服务的。由于同一个CPU上的软中断服务例程不允许嵌套,因此,do_softirq()函数一开始就检查当前CPU是否已经正出在中断服务中,如果是则do_softirq()函数立即返回。举个例子,假设CPU0正在执行do_softirq()函数,执行过程产生了一个高优先级的硬件中断,于是CPU0转去执行这个高优先级中断所对应的中断服务程序。众所周知,所有的中断服务程序最后都要跳转到do_IRQ()函数并由它来依次执行中断服务队列中的ISR,这里我们假定这个高优先级中断的ISR请求触发了一次软中断,于是do_IRQ()函数在退出之前看到有软中断请求,从而调用do_softirq()函数来服务软中断请求。因此,CPU0再次进入do_softirq()函数(也即do_softirq()函数在CPU0上被重入了)。但是在这一次进入do_softirq()函数时,它马上发现CPU0此前已经处在中断服务状态中了,因此这一次do_softirq()函数立即返回。于是,CPU0回到该开始时的do_softirq()函数继续执行,并为高优先级中断的ISR所触发的软中断请求补上一次服务。从这里可以看出,do_softirq()函数在同一个CPU上的执行是串行的。
do_softirq函数:
asmlinkage __visible void do_softirq(void)
{
__u32 pending;
unsigned long flags;
if (in_interrupt())
return;
local_irq_save(flags);
pending = local_softirq_pending();
if (pending && !ksoftirqd_running(pending))
do_softirq_own_stack();
local_irq_restore(flags);
}
__do_softirq函数:
asmlinkage __visible void __softirq_entry __do_softirq(void)
{
unsigned long end = jiffies + MAX_SOFTIRQ_TIME;
unsigned long old_flags = current->flags;
int max_restart = MAX_SOFTIRQ_RESTART;
struct softirq_action *h;
bool in_hardirq;
__u32 pending;
int softirq_bit;
current->flags &= ~PF_MEMALLOC;
pending = local_softirq_pending();
account_irq_enter_time(current);
__local_bh_disable_ip(_RET_IP_, SOFTIRQ_OFFSET);
in_hardirq = lockdep_softirq_start();
restart:
set_softirq_pending(0);
local_irq_enable();
h = softirq_vec;
while ((softirq_bit = ffs(pending))) {
unsigned int vec_nr;
int prev_count;
h += softirq_bit - 1;
vec_nr = h - softirq_vec;
prev_count = preempt_count();
kstat_incr_softirqs_this_cpu(vec_nr);
trace_softirq_entry(vec_nr);
h->action(h);
trace_softirq_exit(vec_nr);
if (unlikely(prev_count != preempt_count())) {
pr_err("huh, entered softirq %u %s %p with preempt_count %08x, exited with %08x?\n",
vec_nr, softirq_to_name[vec_nr], h->action,
prev_count, preempt_count());
preempt_count_set(prev_count);
}
h++;
pending >>= softirq_bit;
}
if (__this_cpu_read(ksoftirqd) == current)
rcu_softirq_qs();
local_irq_disable();
pending = local_softirq_pending();
if (pending) {
if (time_before(jiffies, end) && !need_resched() &&
--max_restart)
goto restart;
wakeup_softirqd();
}
lockdep_softirq_end(in_hardirq);
account_irq_exit_time(current);
__local_bh_enable(SOFTIRQ_OFFSET);
WARN_ON_ONCE(in_interrupt());
current_restore_flags(old_flags, PF_MEMALLOC);
}
2.4.2 在守护线程ksoftirq中执行
虽然大部分的softirq是在中断退出的情况下执行,但是有几种情况会在ksoftirq中执行。
- 从上文看出,raise_softirq主动触发,而此时正好不是在中断上下文中,ksoftirq进程将被唤醒。
- 在irq_exit中执行软中断,但是在经过MAX_SOFTIRQ_RESTART次循环后,软中断还未处理完,这种情况,ksoftirq进程也会被唤醒。
所以加入守护线程这一机制,主要是担心一旦有大量的软中断等待执行,会使得内核过长地留在中断上下文中。
static void wakeup_softirqd(void)
{
struct task_struct *tsk = __this_cpu_read(ksoftirqd);
if (tsk && tsk->state != TASK_RUNNING)
wake_up_process(tsk);
}
softirq_threads线程函数为run_ksoftirqd:
static struct smp_hotplug_thread softirq_threads = {
.store = &ksoftirqd,
.thread_should_run = ksoftirqd_should_run,
.thread_fn = run_ksoftirqd,
.thread_comm = "ksoftirqd/%u",
};
run_ksoftirqd函数:
static void run_ksoftirqd(unsigned int cpu)
{
local_irq_disable();
if (local_softirq_pending()) {
__do_softirq();
local_irq_enable();
cond_resched();
return;
}
local_irq_enable();
}
三、小任务机制
tasklet机制是一种较为特殊的软中断。
tasklet一词的原意是“小片任务”的意思,这里是指一小段可执行的代码,且通常以函数的形式出现。软中断向量HI_SOFTIRQ和TASKLET_SOFTIRQ均是用tasklet机制来实现的。
从某种程度上讲,tasklet机制是Linux内核对BH机制的一种扩展。在2.4内核引入了softirq机制后,原有的BH机制正是通过tasklet机制这个桥梁来将softirq机制纳入整体框架中的。正是由于这种历史的延伸关系,使得tasklet机制与一般意义上的软中断有所不同,而呈现出以下两个显著的特点:
- 与一般的软中断不同,某一段tasklet代码在某个时刻只能在一个CPU上运行,而不像一般的软中断服务函数(即softirq_action结构中的action函数指针)那样——在同一时刻可以被多个CPU并发地执行。
- 与BH机制不同,不同的tasklet代码在同一时刻可以在多个CPU上并发地执行,而不像BH机制那样必须严格地串行化执行(也即在同一时刻系统中只能有一个CPU执行BH函数)。
3.1 tasklet描述符
Linux用数据结构tasklet_struct来描述一个tasklet,每个结构代表一个独立的小任务。该数据结构定义在include/linux/interrupt.h头文件中。如下所示:
struct tasklet_struct
{
struct tasklet_struct *next;
unsigned long state;
atomic_t count;
void (*func)(unsigned long);
unsigned long data;
};
其中:
对这两个状态位的宏定义如下所示(interrupt.h):
enum
{
TASKLET_STATE_SCHED,
TASKLET_STATE_RUN
};
- count: 子计数count,对这个tasklet的引用计数值。
注:只有当count等于0时,tasklet代码段才能执行,也即此时tasklet是被使能的;如果count非零,则这个tasklet是被禁止的。任何想要执行一个tasklet代码段的人都首先必须先检查其count成员是否为0。
- func:指向以函数形式表现的可执行tasklet代码段。
- data:函数func的参数。这是一个32位的无符号整数,其具体含义可供func函数自行解释,比如将其解释成一个指向某个用户自定义数据结构的地址值。
Linux在interrupt.h头文件中又定义了两个用来定义tasklet_struct结构变量的辅助宏:
#define DECLARE_TASKLET(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
#define DECLARE_TASKLET_DISABLED(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data }
显然,从上述源代码可以看出,用DECLARE_TASKLET宏定义的tasklet在初始化时是被使能的(enabled),因为其count成员为0。而用DECLARE_TASKLET_DISABLED宏定义的tasklet在初始时是被禁止的(disabled),因为其count等于1。
3.2 改变一个tasklet状态的操作
在这里,tasklet状态指两个方面:
- state:成员所表示的运行状态;
- count:成员决定的使能/禁止状态。
3.2.1 改变一个tasklet的运行状态
state成员中的bit[0]表示一个tasklet是否已被调度去等待执行,bit[1]表示一个tasklet是否正在某个CPU上执行。对于state变量中某位的改变必须是一个原子操作,因此可以用定义在include/asm/bitops.h头文件中的位操作来进行。
由于bit[1]这一位(即TASKLET_STATE_RUN)仅仅对于SMP系统才有意义,因此Linux在Interrupt.h头文件中显示地定义了对TASKLET_STATE_RUN位的操作。如下所示:
#ifdef CONFIG_SMP
static inline int tasklet_trylock(struct tasklet_struct *t)
{
return !test_and_set_bit(TASKLET_STATE_RUN, &(t)->state);
}
static inline void tasklet_unlock(struct tasklet_struct *t)
{
smp_mb__before_clear_bit();
clear_bit(TASKLET_STATE_RUN, &(t)->state);
}
static inline void tasklet_unlock_wait(struct tasklet_struct *t)
{
while (test_bit(TASKLET_STATE_RUN, &(t)->state)) { barrier(); }
}
#else
#define tasklet_trylock(t) 1
#define tasklet_unlock_wait(t) do { } while (0)
#define tasklet_unlock(t) do { } while (0)
#endif
显然,在SMP系统同,tasklet_trylock()宏将把一个tasklet_struct结构变量中的state成员中的bit[1]位设置成1,同时还返回bit[1]位的非。因此,如果bit[1]位原有值为1(表示另外一个CPU正在执行这个tasklet代码),那么tasklet_trylock()宏将返回值0,也就表示上锁不成功。如果bit[1]位的原有值为0,那么tasklet_trylock()宏将返回值1,表示加锁成功。而在单CPU系统中,tasklet_trylock()宏总是返回为1。
任何想要执行某个tasklet代码的程序都必须首先调用宏tasklet_trylock()来试图对这个tasklet进行上锁(即设置TASKLET_STATE_RUN位),且只能在上锁成功的情况下才能执行这个tasklet。建议!即使你的程序只在CPU系统上运行,你也要在执行tasklet之前调用tasklet_trylock()宏,以便使你的代码获得良好可移植性。
在SMP系统中,tasklet_unlock_wait()宏将一直不停地测试TASKLET_STATE_RUN位的值,直到该位的值变为0(即一直等待到解锁),假如:CPU0正在执行tasklet A的代码,在此期间,CPU1也想执行tasklet A的代码,但CPU1发现tasklet A的TASKLET_STATE_RUN位为1,于是它就可以通过tasklet_unlock_wait()宏等待tasklet A被解锁(也即TASKLET_STATE_RUN位被清零)。在单CPU系统中,这是一个空操作。
宏tasklet_unlock()用来对一个tasklet进行解锁操作,也即将TASKLET_STATE_RUN位清零。在单CPU系统中,这是一个空操作。
3.2.2 使能/禁止一个tasklet
使能与禁止操作往往总是成对地被调用的,tasklet_disable()函数如下(interrupt.h):
static inline void tasklet_disable(struct tasklet_struct *t)
{
tasklet_disable_nosync(t);
tasklet_unlock_wait(t);
smp_mb();
}
函数tasklet_disable_nosync()也是一个静态inline函数,它简单地通过原子操作将count成员变量的值加1。如下所示(interrupt.h):
static inline void tasklet_disable_nosync(struct tasklet_struct *t)
{
atomic_inc(&t->count);
smp_mb__after_atomic_inc();
}
函数tasklet_enable()用于使能一个tasklet,如下所示(interrupt.h):
static inline void tasklet_enable(struct tasklet_struct *t)
{
smp_mb__before_atomic_dec();
atomic_dec(&t->count);
}
3.3 tasklet描述符的初始化与杀死
函数tasklet_init()用来初始化一个指定的tasklet描述符,其源码如下所示(kernel/softirq.c):
void tasklet_init(struct tasklet_struct *t,
void (*func)(unsigned long), unsigned long data)
{
t->next = NULL;
t->state = 0;
atomic_set(&t->count, 0);
t->func = func;
t->data = data;
}
函数tasklet_kill()用来将一个已经被调度了的tasklet杀死,即将其恢复到未调度的状态。其源码如下所示(kernel/softirq.c):
void tasklet_kill(struct tasklet_struct *t)
{
if (in_interrupt())
pr_notice("Attempt to kill tasklet from interrupt\n");
while (test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) {
do {
yield();
} while (test_bit(TASKLET_STATE_SCHED, &t->state));
}
tasklet_unlock_wait(t);
clear_bit(TASKLET_STATE_SCHED, &t->state);
}
3.4 tasklet对列
多个tasklet可以通过tasklet描述符中的next成员指针链接成一个单向对列。为此,Linux专门在头文件include/linux/interrupt.h中定义了数据结构tasklet_head来描述一个tasklet对列的头部指针。如下所示:
struct tasklet_head
{
struct tasklet_struct *head;
struct tasklet_struct **tail;
};
尽管tasklet机制是特定于软中断向量HI_SOFTIRQ和TASKLET_SOFTIRQ的一种实现,但是tasklet机制仍然属于softirq机制的整体框架范围内的,因此,它的设计与实现仍然必须坚持“谁触发,谁执行”的思想。为此,Linux为系统中的每一个CPU都定义了一个tasklet对列头部,来表示应该有各个CPU负责执行的tasklet对列。如下所示(kernel/softirq.c):
#define DECLARE_PER_CPU(type, name) \
DECLARE_PER_CPU_SECTION(type, name, "")
#define DEFINE_PER_CPU(type, name) \
DEFINE_PER_CPU_SECTION(type, name, "")
static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec);
static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec);
上面展开,可得:
struct tasklet_head tasklet_vec[NR_CPUS] __cacheline_aligned;
struct tasklet_head tasklet_hi_vec[NR_CPUS] __cacheline_aligned;
其中,tasklet_vec[]数组用于软中断向量TASKLET_SOFTIRQ,而tasklet_hi_vec[]数组则用于软中断向量HI_SOFTIRQ。也即,如果CPUi(0≤i≤NR_CPUS-1)触发了软中断向量TASKLET_SOFTIRQ,那么对列tasklet_vec[i]中的每一个tasklet都将在CPUi服务于软中断向量TASKLET_SOFTIRQ时被CPUi所执行。同样地,如果CPUi(0≤i≤NR_CPUS-1)触发了软中断向量HI_SOFTIRQ,那么队列tasklet_hi_vec[i]中的每一个tasklet都将CPUi在对软中断向量HI_SOFTIRQ进行服务时被CPUi所执行。
队列tasklet_vec[I]和tasklet_hi_vec[I]中的各个tasklet是怎样被所CPUi所执行的呢?其关键就是软中断向量TASKLET_SOFTIRQ和HI_SOFTIRQ的软中断服务程序——tasklet_action()函数和tasklet_hi_action()函数。下面我们就来分析这两个函数。
3.5 软中断向量TASKLET_SOFTIRQ和HI_SOFTIRQ
Linux为软中断向量TASKLET_SOFTIRQ和HI_SOFTIRQ实现了专用的触发函数和软中断服务函数。
tasklet_schedule()函数和tasklet_hi_schedule()函数分别用来在当前CPU上触发软中断向量TASKLET_SOFTIRQ和HI_SOFTIRQ,并把指定的tasklet加入当前CPU所对应的tasklet队列中去等待执行。
tasklet_action()函数和tasklet_hi_action()函数则分别是软中断向量TASKLET_SOFTIRQ和HI_SOFTIRQ的软中断服务函数。在初始化函数softirq_init()中,这两个软中断向量对应的描述符softirq_vec[0]和softirq_vec[6]中的action函数指针就被分别初始化成指向函数tasklet_hi_action()和函数tasklet_action()。
3.5.1软中断向量TASKLET_SOFTIRQ的触发函数tasklet_schedule
该函数实现在include/linux/interrupt.h头文件中,是一个inline函数。其源码如下所示:
static inline void tasklet_schedule(struct tasklet_struct *t)
{
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_schedule(t);
}
void __tasklet_schedule(struct tasklet_struct *t)
{
__tasklet_schedule_common(t, &tasklet_vec,
TASKLET_SOFTIRQ);
}
static void __tasklet_schedule_common(struct tasklet_struct *t,
struct tasklet_head __percpu *headp,
unsigned int softirq_nr)
{
struct tasklet_head *head;
unsigned long flags;
local_irq_save(flags);
head = this_cpu_ptr(headp);
t->next = NULL;
*head->tail = t;
head->tail = &(t->next);
raise_softirq_irqoff(softirq_nr);
local_irq_restore(flags);
}
-
调用test_and_set_bit()函数将待调度的tasklet的state成员变量的bit[0]位(也即TASKLET_STATE_SCHED位)设置为1,该函数同时还返回TASKLET_STATE_SCHED位的原有值。因此如果bit[0]为的原有值已经为1,那就说明这个tasklet已经被调度到另一个CPU上去等待执行了。由于一个tasklet在某一个时刻只能由一个CPU来执行,因此tasklet_schedule()函数什么也不做就直接返回了。否则,就继续下面的调度操作。
-
首先,调用local_irq_save()函数来关闭当前CPU的中断,以保证下面的步骤在当前CPU上原子地被执行。
-
然后,将待调度的tasklet添加到当前CPU对应的tasklet队列的尾部。
-
接着,调用raise_softirq_irqoff函数在当前CPU上触发软中断请求TASKLET_SOFTIRQ。
-
最后,调用local_irq_restore()函数来开当前CPU的中断。
3.5.2软中断向量TASKLET_SOFTIRQ的服务程序tasklet_action
函数tasklet_action()是tasklet机制与软中断向量TASKLET_SOFTIRQ的联系纽带。正是该函数将当前CPU的tasklet队列中的各个tasklet放到当前CPU上来执行的。该函数实现在kernel/softirq.c文件中,其源代码如下:
static __latent_entropy void tasklet_action(struct softirq_action *a)
{
tasklet_action_common(a, this_cpu_ptr(&tasklet_vec), TASKLET_SOFTIRQ);
}
static void tasklet_action_common(struct softirq_action *a,
struct tasklet_head *tl_head,
unsigned int softirq_nr)
{
struct tasklet_struct *list;
local_irq_disable();
list = tl_head->head;
tl_head->head = NULL;
tl_head->tail = &tl_head->head;
local_irq_enable();
while (list) {
struct tasklet_struct *t = list;
list = list->next;
if (tasklet_trylock(t)) {
if (!atomic_read(&t->count)) {
if (!test_and_clear_bit(TASKLET_STATE_SCHED,
&t->state))
BUG();
t->func(t->data);
tasklet_unlock(t);
continue;
}
tasklet_unlock(t);
}
local_irq_disable();
t->next = NULL;
*tl_head->tail = t;
tl_head->tail = &t->next;
__raise_softirq_irqoff(softirq_nr);
local_irq_enable();
}
}
- 首先,在当前CPU关中断的情况下,“原子”地读取当前CPU的tasklet队列头部指针,将其保存到局部变量list指针中,然后将当前CPU的tasklet队列头部指针设置为NULL,以表示理论上当前CPU将不再有tasklet需要执行(但最后的实际结果却并不一定如此,下面将会看到)。
- 然后,用一个while{}循环来遍历由list所指向的tasklet队列,队列中的各个元素就是将在当前CPU上执行的tasklet。循环体的执行步骤如下:
- 用指针t来表示当前队列元素,即当前需要执行的tasklet。
- 更新list指针为list->next,使它指向下一个要执行的tasklet。
- 用tasklet_trylock()宏试图对当前要执行的tasklet(由指针t所指向)进行加锁,如果加锁成功(当前没有任何其他CPU正在执行这个tasklet),则用原子读函数atomic_read()进一步判断count成员的值。如果count为0,说明这个tasklet是允许执行的,于是:
- 先清除TASKLET_STATE_SCHED位;
- 然后,调用这个tasklet的可执行函数func;
- 调用宏tasklet_unlock()来清除TASKLET_STATE_RUN位 ;
- 最后,执行continue语句跳过下面的步骤,回到while循环继续遍历队列中的下一个元素。如果count不为0,说明这个tasklet是禁止运行的,于是调用tasklet_unlock()清除前面用tasklet_trylock()设置的TASKLET_STATE_RUN位。
3.6 tasklet使用总结
1、声明和使用小任务大多数情况下,为了控制一个常用的硬件设备,小任务机制是实现下半部的最佳选择。小任务可以动态创建,使用方便,执行起来也比较快。我们既可以静态地创建小任务,也可以动态地创建它。选择那种方式取决于到底是想要对小任务进行直接引用还是一个间接引用。如果准备静态地创建一个小任务(也就是对它直接引用),使用下面两个宏中的一个:
DECLARE_TASKLET(name,func, data)
DECLARE_TASKLET_DISABLED(name,func, data)
这两个宏都能根据给定的名字静态地创建一个tasklet_struct结构。当该小任务被调度以后,给定的函数func会被执行,它的参数由data给出。这两个宏之间的区别在于引用计数器的初始值设置不同。第一个宏把创建的小任务的引用计数器设置为0,因此,该小任务处于激活状态。另一个把引用计数器设置为1,所以该小任务处于禁止状态。例如:
DECLARE_TASKLET(my_tasklet,my_tasklet_handler, dev);
这行代码其实等价于
struct tasklet_struct my_tasklet = { NULL, 0, ATOMIC_INIT(0),tasklet_handler,dev};
这样就创建了一个名为my_tasklet的小任务,其处理程序为tasklet_handler,并且已被激活。当处理程序被调用的时候,dev就会被传递给它。
2、编写自己的小任务处理程序小任务处理程序必须符合如下的函数类型:
void tasklet_handler(unsigned long data)
由于小任务不能睡眠,因此不能在小任务中使用信号量或者其它产生阻塞的函数。但是小任务运行时可以响应中断。
3、调度自己的小任务通过调用tasklet_schedule()函数并传递给它相应的tasklt_struct指针,该小任务就会被调度以便适当的时候执行:
tasklet_schedule(&my_tasklet); /*把my_tasklet标记为挂起 */
在小任务被调度以后,只要有机会它就会尽可能早的运行。在它还没有得到运行机会之前,如果一个相同的小任务又被调度了,那么它仍然只会运行一次。
可以调用tasklet_disable()函数来禁止某个指定的小任务。如果该小任务当前正在执行,这个函数会等到它执行完毕再返回。调用tasklet_enable()函数可以激活一个小任务,如果希望把以DECLARE_TASKLET_DISABLED()创建的小任务激活,也得调用这个函数,如:
tasklet_disable(&my_tasklet); /小任务现在被禁止,这个小任务不能运行/
tasklet_enable(&my_tasklet); /* 小任务现在被激活*/
也可以调用tasklet_kill()函数从挂起的队列中去掉一个小任务。该函数的参数是一个指向某个小任务的tasklet_struct的长指针。在小任务重新调度它自身的时候,从挂起的队列中移去已调度的小任务会很有用。这个函数首先等待该小任务执行完毕,然后再将它移去。
4、tasklet的简单用法
下面是tasklet的一个简单应用,以模块的形成加载。
#include <linux/module.h>
#include <linux/init.h>
#include <linux/fs.h>
#include <linux/kdev_t.h>
#include <linux/cdev.h>
#include <linux/kernel.h>
#include <linux/interrupt.h>
static struct t asklet_struct my_tasklet;
static void tasklet_handler (unsigned long d ata)
{
printk(KERN_ALERT,"tasklet_handler is running./n");
}
static int __init test_init(void)
{
tasklet_init(&my_tasklet,tasklet_handler,0);
tasklet_schedule(&my_tasklet);
return0;
}
static void __exit test_exit(void)
{
tasklet_kill(&tasklet);
printk(KERN_ALERT,"test_exit is running./n");
}
MODULE_LICENSE("GPL");
module_init(test_init);
module_exit(test_exit);
从这个例子可以看出,所谓的小任务机制是为下半部函数的执行提供了一种执行机制,也就是说,推迟处理的事情是由tasklet_handler实现,何时执行,经由小任务机制封装后交给内核去处理。
四、中断处理的工作队列机制
工作队列(work queue)是另外一种将工作推后执行的形式,它和前面讨论的tasklet有所不同。工作队列可以把工作推后,交由一个内核线程去执行,也就是说,这个下半部分可以在进程上下文中执行。这样,通过工作队列执行的代码能占尽进程上下文的所有优势。最重要的就是工作队列允许被重新调度甚至是睡眠。
那么,什么情况下使用工作队列,什么情况下使用tasklet。如果推后执行的任务需要睡眠,那么就选择工作队列;如果推后执行的任务不需要睡眠,那么就选择tasklet。另外,如果需要用一个可以重新调度的实体来执行你的下半部处理,也应该使用工作队列。它是唯一能在进程上下文运行的下半部实现的机制,也只有它才可以睡眠。这意味着在需要获得大量的内存时、在需要获取信号量时,在需要执行阻塞式的I/O操作时,它都会非常有用。如果不需要用一个内核线程来推后执行工作,那么就考虑使用tasklet。
4.1 工作、工作队列
如前所述,我们把推后执行的任务叫做工作(work),描述它的数据结构为work_struct,这些工作以队列结构组织成工作队列(workqueue),其数据结构为workqueue_struct,而工作线程就是负责执行工作队列中的工作。系统默认的工作者线程为events,自己也可以创建自己的工作者线程。表示工作的数据结构用<linux/workqueue.h>中定义的work_struct结构表示:
struct work_struct {
atomic_long_t data;
struct list_head entry;
work_func_t func;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
typedef void (*work_func_t)(struct work_struct *work);
这些结构被连接成链表。当一个工作者线程被唤醒时,它会执行它的链表上的所有工作。工作被执行完毕,它就将相应的work_struct对象从链表上移去。当链表上不再有对象的时候,它就会继续休眠。表示工作队列的数据结构用<kernel/workqueue.c>中定义的workqueue_struct:
struct workqueue_struct {
struct list_head pwqs;
struct list_head list;
struct mutex mutex;
int work_color;
int flush_color;
atomic_t nr_pwqs_to_flush;
struct wq_flusher *first_flusher;
struct list_head flusher_queue;
struct list_head flusher_overflow;
struct list_head maydays;
struct worker *rescuer;
int nr_drainers;
int saved_max_active;
struct workqueue_attrs *unbound_attrs;
struct pool_workqueue *dfl_pwq;
#ifdef CONFIG_SYSFS
struct wq_device *wq_dev;
#endif
#ifdef CONFIG_LOCKDEP
char *lock_name;
struct lock_class_key key;
struct lockdep_map lockdep_map;
#endif
char name[WQ_NAME_LEN];
struct rcu_head rcu;
unsigned int flags ____cacheline_aligned;
struct pool_workqueue __percpu *cpu_pwqs;
struct pool_workqueue __rcu *numa_pwq_tbl[];
};
4.2 创建推后的工作
4.2.1 静态地创建工作(work_struct)
要使用工作队列,首先要做的是创建一些需要推后完成的工作。可以通过DECLARE_WORK在编译时静态地建该结构:
DECLARE_WORK(name, func); 或者INIT_WORK(_work, _func)
其定义如下:
#define DECLARE_WORK(n, f) \
struct work_struct n = __WORK_INITIALIZER(n, f)
举例如下:
static void do_poweroff(struct work_struct *dummy)
{
kernel_power_off();
}
static DECLARE_WORK(poweroff_work, do_poweroff);
即创建了一个全局静态变量:static work_struct poweroff_work,且被初始化了,其执行函数为do_poweroff。
4.2.2 动态初始化工作(work_struct)
先定义一具struct work_struct 变量,在需要使用时调用INIT_WORK进行初始化,然后便可以使用。
#define INIT_WORK(_work, _func) \
do { \
__INIT_WORK((_work), (_func), 0); \
} while (0)
举例:
void __cfg80211_scan_done(struct work_struct *wk)
{
struct cfg80211_registered_device *rdev;
rdev = container_of(wk, struct cfg80211_registered_device,
scan_done_wk);
cfg80211_lock_rdev(rdev);
___cfg80211_scan_done(rdev, false);
cfg80211_unlock_rdev(rdev);
}
struct cfg80211_registered_device {
struct work_struct scan_done_wk;
struct work_struct sched_scan_results_wk;
struct work_struct conn_work;
struct work_struct event_work;
struct cfg80211_wowlan *wowlan;
}
struct cfg80211_registered_device *rdev;
rdev = kzalloc(alloc_size, GFP_KERNEL);
INIT_WORK(&rdev->scan_done_wk, __cfg80211_scan_done); // 其执行函数为: __cfg80211_scan_done
INIT_WORK(&rdev->sched_scan_results_wk, __cfg80211_sched_scan_results);
4.3 对工作进行调度
现在工作已经被创建,我们可以调度它了。想要把给定工作的待处理函数提交给缺省的events工作线程,只需调用: int schedule_work(struct work_struct *work);
它把work放入全局工作队列:system_wq,其定义如下:
static inline bool schedule_work(struct work_struct *work)
{
return queue_work(system_wq, work);
}
extern struct workqueue_struct *system_wq;
queue_work:把一个工作放入工作队列:
static inline bool queue_work(struct workqueue_struct *wq,
struct work_struct *work)
{
return queue_work_on(WORK_CPU_UNBOUND, wq, work);
}
bool queue_work_on(int cpu, struct workqueue_struct *wq,
struct work_struct *work)
{
bool ret = false;
unsigned long flags;
local_irq_save(flags);
if (!test_and_set_bit(WORK_STRUCT_PENDING_BIT, work_data_bits(work))) {
__queue_work(cpu, wq, work);
ret = true;
}
local_irq_restore(flags);
return ret;
}
把work放入工作队列,work马上就会被调度,一旦其所在的处理器上的工作者线程被唤醒,它就会被执行。有时候并不希望工作马上就被执行,而是希望它经过一段延迟以后再执行。在这种情况下,可以调度它在指定的时间执行:
static inline bool schedule_delayed_work(struct delayed_work *dwork,
unsigned long delay)
{
return queue_delayed_work(system_wq, dwork, delay);
}
#define DECLARE_DELAYED_WORK(n, f) \
struct delayed_work n = __DELAYED_WORK_INITIALIZER(n, f, 0)
#define INIT_DELAYED_WORK(_work, _func) \
__INIT_DELAYED_WORK(_work, _func, 0)
4.4 创建工作者线程
工作放入工作队列之后,由管理此工作队列的工作者来执行这些work,通过alloc_workqueue或create_singlethread_workqueue来创建工作者线程,它最后调用kthread_create创建线程,其线程名为alloc_workqueue中指定的name,其举例如下:
int __init workqueue_init_early(void)
{
int std_nice[NR_STD_WORKER_POOLS] = { 0, HIGHPRI_NICE_LEVEL };
int hk_flags = HK_FLAG_DOMAIN | HK_FLAG_WQ;
int i, cpu;
WARN_ON(__alignof__(struct pool_workqueue) < __alignof__(long long));
BUG_ON(!alloc_cpumask_var(&wq_unbound_cpumask, GFP_KERNEL));
cpumask_copy(wq_unbound_cpumask, housekeeping_cpumask(hk_flags));
pwq_cache = KMEM_CACHE(pool_workqueue, SLAB_PANIC);
for_each_possible_cpu(cpu) {
struct worker_pool *pool;
i = 0;
for_each_cpu_worker_pool(pool, cpu) {
BUG_ON(init_worker_pool(pool));
pool->cpu = cpu;
cpumask_copy(pool->attrs->cpumask, cpumask_of(cpu));
pool->attrs->nice = std_nice[i++];
pool->node = cpu_to_node(cpu);
mutex_lock(&wq_pool_mutex);
BUG_ON(worker_pool_assign_id(pool));
mutex_unlock(&wq_pool_mutex);
}
}
for (i = 0; i < NR_STD_WORKER_POOLS; i++) {
struct workqueue_attrs *attrs;
BUG_ON(!(attrs = alloc_workqueue_attrs()));
attrs->nice = std_nice[i];
unbound_std_wq_attrs[i] = attrs;
BUG_ON(!(attrs = alloc_workqueue_attrs()));
attrs->nice = std_nice[i];
attrs->no_numa = true;
ordered_wq_attrs[i] = attrs;
}
system_wq = alloc_workqueue("events", 0, 0);
system_highpri_wq = alloc_workqueue("events_highpri", WQ_HIGHPRI, 0);
system_long_wq = alloc_workqueue("events_long", 0, 0);
system_unbound_wq = alloc_workqueue("events_unbound", WQ_UNBOUND,
WQ_UNBOUND_MAX_ACTIVE);
system_freezable_wq = alloc_workqueue("events_freezable",
WQ_FREEZABLE, 0);
system_power_efficient_wq = alloc_workqueue("events_power_efficient",
WQ_POWER_EFFICIENT, 0);
system_freezable_power_efficient_wq = alloc_workqueue("events_freezable_power_efficient",
WQ_FREEZABLE | WQ_POWER_EFFICIENT,
0);
BUG_ON(!system_wq || !system_highpri_wq || !system_long_wq ||
!system_unbound_wq || !system_freezable_wq ||
!system_power_efficient_wq ||
!system_freezable_power_efficient_wq);
return 0;
}
int __init workqueue_init(void)
{
struct workqueue_struct *wq;
struct worker_pool *pool;
int cpu, bkt;
wq_numa_init();
mutex_lock(&wq_pool_mutex);
for_each_possible_cpu(cpu) {
for_each_cpu_worker_pool(pool, cpu) {
pool->node = cpu_to_node(cpu);
}
}
list_for_each_entry(wq, &workqueues, list) {
wq_update_unbound_numa(wq, smp_processor_id(), true);
WARN(init_rescuer(wq),
"workqueue: failed to create early rescuer for %s",
wq->name);
}
mutex_unlock(&wq_pool_mutex);
for_each_online_cpu(cpu) {
for_each_cpu_worker_pool(pool, cpu) {
pool->flags &= ~POOL_DISASSOCIATED;
BUG_ON(!create_worker(pool));
}
}
hash_for_each(unbound_pool_hash, bkt, pool, hash_node)
BUG_ON(!create_worker(pool));
wq_online = true;
wq_watchdog_init();
return 0;
}
如:cfg80211_wq = create_singlethread_workqueue(“cfg80211”);创建了一个名为cfg80211的kernel线程。
4.5 工作队列的简单应用
#include <linux/module.h>
#include <linux/init.h>
#include <linux/workqueue.h>
static struct workqueue_struct *queue = NULL;
static struct work_struct work;
static void work_handler(struct work_struct *data)
{
printk(KERN_ALERT "work handler function.\n");
}
static int __init test_init(void)
{
queue = create_singlethread_workqueue("helloworld");
if (!queue)
goto err;
INIT_WORK(&work, work_handler);
schedule_work(&work);
return 0;
err:
return -1;
}
static void __exit test_exit(void) {
destroy_workqueue(queue);
}
MODULE_LICENSE("GPL");
module_init(test_init);
module_exit(test_exit);
参考
[1] https://blog.csdn.net/myarrow/article/details/9287169
[2] https://blog.csdn.net/yhb1047818384/article/details/63687126
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)