所有的系统I/O都分为两个阶段:等待就绪和操作.读就是等待系统可读和真正的读;写就是等待系统可写和真正的写.
1.网络io模型
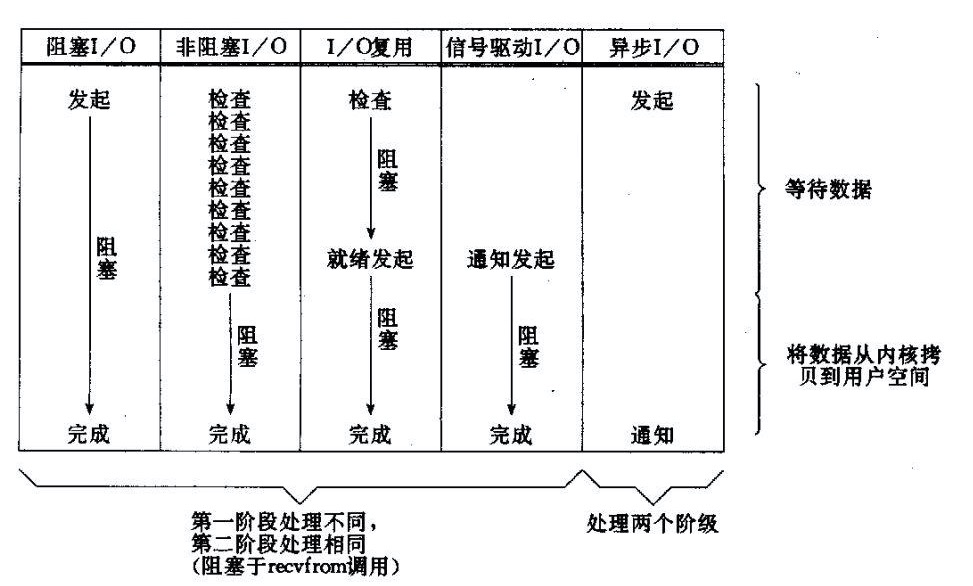
这是我们常见的一张图.
1.传统的bio,就是同步阻塞的.当调用socket.read的时候.会阻塞. 直到系统可读/写;当真正去执行读的时候(内核-->用户),还是阻塞. 对应的优化方式有ppc/tpc(下面的1.1 和 1.2)
2.非阻塞io,当调用read时,如果不可读,那么直接返回一个标识,告诉你等会再来问.现在不可读嘞.那么好的,你就过一会问一下.当可读时,去调用recvFrom系统调用.不过此时还是阻塞的.
3. 而多路复用是操作系统提供了一个函数.可以创建一个selector,用于遍历你传入的fd(也就是socket,万物皆文件).再注册你关注的事件.同时你会阻塞selector.select().这个会返回你感兴趣的事件.例如某个fd可读了.那么就是说,这个socket有数据发送到了读缓冲区.你可以拿走了,你拿走我的滑块好滑起来.写同理. 实现上就是selector线程死循环的去读取事件(当然这里可以分为多个线程 对应下面的1.3.3),分发给处理器,处理线程可以是单线程(1.3.1)也可以是多线程(1.3.2/1.3.3)
4.前面3种在读的时候,都是同步读取的.你必须要不断的问操作系统,好了没,好了没.,那么Aio是可以用户程序啥都不管.操作系统会在数据可读的时候,把数据从内核空间拷贝到用户空间.并调用用户的回调函数.执行
1.1 ppc
针对bio模型,在早期的编程中,对每个连接可以fork一个子进程(process per connection)
流程:
- 父进程接收连接
- 当收到一个连接后,fork一个子进程去处理请求
- 子进程处理完毕后,close
缺点:
- fork代价高.创建进程需要很多资源.而且需要copy父进程资源到子进程,例如页表,内存等,而且会阻塞.释放进程消耗也不小
- 父子进程通信很复杂.需要ipc进行通信.例如子进程告诉父进程处理了几个请求,耗时等等.
- cpu一共就那么几个核.来100个连接就要有100多个进程.进程切换成本也不小
1.2 tpc
对每个连接创建一个线程(thread per connnection).听起来线程比进程代价小,而且进程间通信也很快,但是缺点仍然很大
流程:
- 主线程接收连接
- 当accpet到一个连接后,创建一个线程去处理
- 为了避免不断创建线程,可以使用线程池来处理
缺点:
- 实际上和ppc一样.只不过用的是线程,不过很多操作系统(linux).线程就是用的进程
- 虽然使用了连接池,但是一旦池子满了,还是阻塞的
1.3reactor
反应堆,理解为事件反映.就是我们只关注事件,当一个连接来,一个连接可写,一个连接可读时,对事件作出反应,分发给handler去处理.Reactor 模式的核心组成部分包括 Reactor 和处理资源池.reactor用来处理连接,接收到连接后,会调用资源池去处理这个连接.有些文章也称之为dispatch模式.
根据reactor和资源池多少可以分为以下几种类型
1.3.1 单reactor单进程/线程
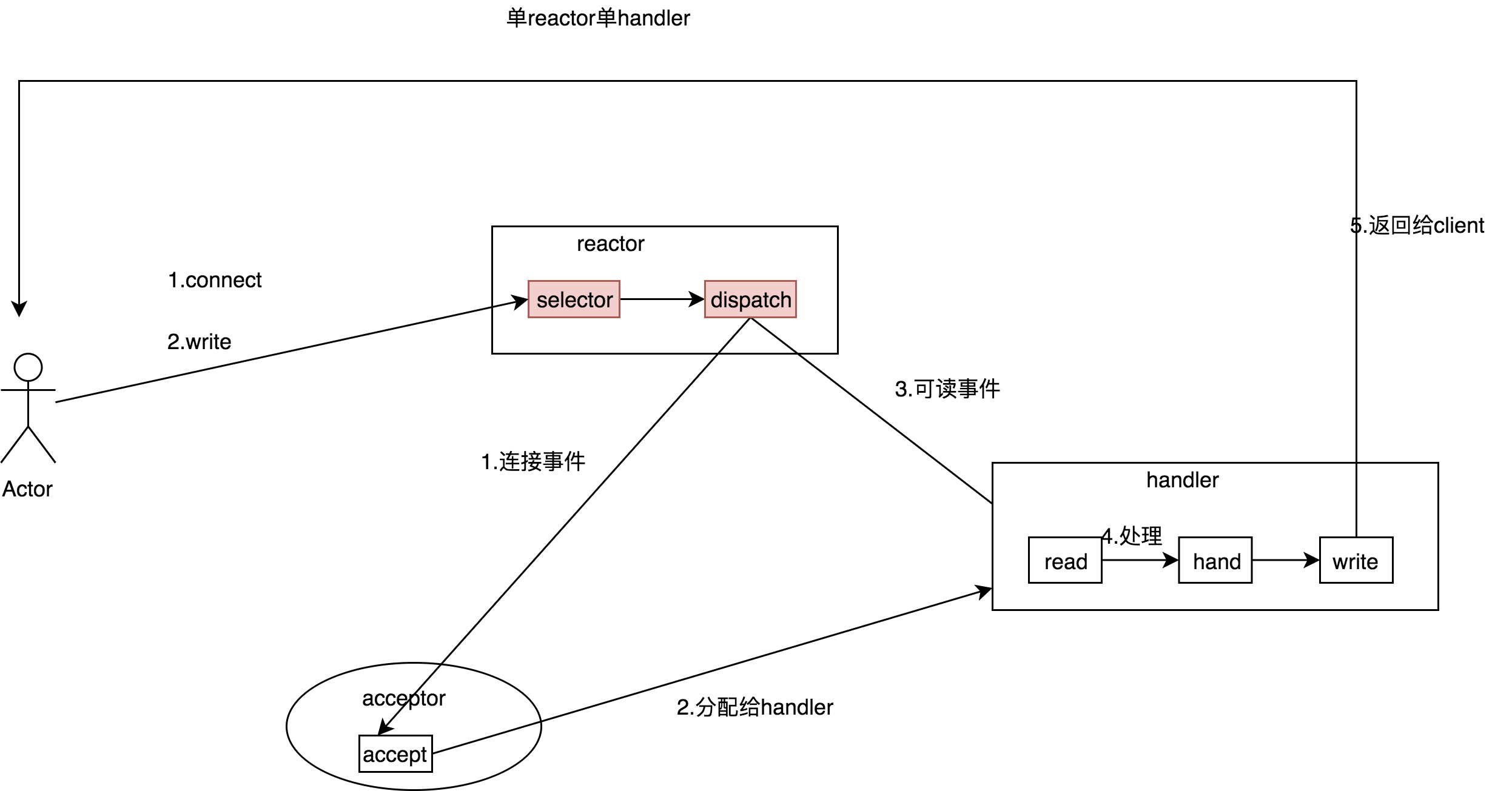
a.reactor用于监听事件.当监听到连接事件后,分发给acceptor处理;当监听到读写事件后,分发给handle
b:acceptor接收完连接后,会分配handler处理后续请求.并注册读写到selector
c:当可读后,handler读取数据,进行处理,然后发送给client
缺点:可以看到只有一个线程在selector.当可读后,只有一个线程处理请求.无法使用到多核优势.redis在用.不过redis最近也要搞多线程.
1.3.2单reactor多线程

事件的监听还是在主线程.不过处理事件,会交给其他线程,可以搞一个线程池
1.3.3多reactor和多线程
netty就是这么实现,有多个reactor在监听事件.监听到之后,分配给线程池去处理.避免io处理和业务处理相互影响.

对比下netty实现,就很容易理解了.
1.一个reactor用来监听连接事件(boss线程).当监听到连接事件后,调用accept.同时把channel注册到work reactor中(work线程),
2.work reactor用来监听读写.当监听到可读后,调用业务线程池,进行处理,处理结束后,调用channel.write(msg);此时work reactor监听到可写事件.将数据发给client.ending
1.4 proactor
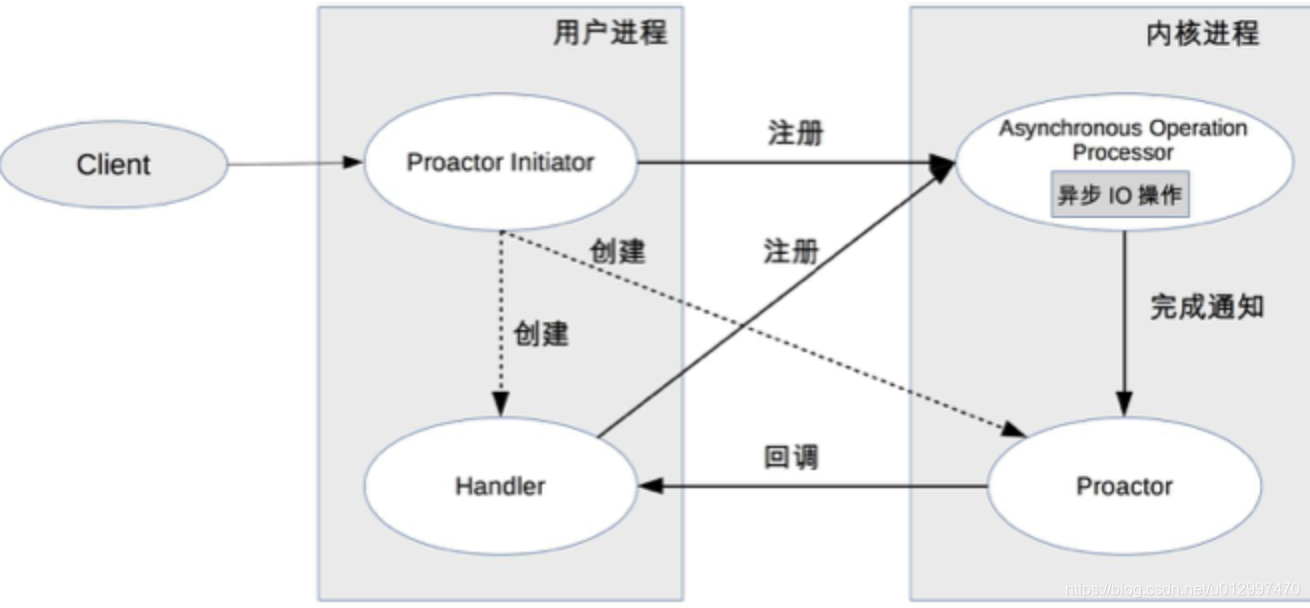
copy一个图,大概意思就是
1.用户会把事件和回调函数注册到内核
2.当有对应的事件时(这里指io事件,连接/可读/可写),会自动执行连接/读数据/写数据.并调用注册的回调函数
想法是好的,不过操作系统没有实现完美,因此很少有用proactor的
2.IO分类
网络io的时候,都是在操作内存,如果从磁盘读写一个文件的时候,操作系统又分为哪几种模式呢
2.1.直接io
直接io:直接把磁盘数据读取到用户态内存.
例如我们在代码中读取一个文件
Byte[] byteArray=new Byte[1024];
byteArray=file.read("/data/test.txt")
这里byteArray就是申请一块用户态内存.
我们把磁盘数据直接读到用户态内存,可能耗时很慢.我们知道磁盘的操作和内存的操作速度不是一个级别的.尤其如果是随机读,那么会更慢!但是,很多数据库都会用直接读写,为啥呢?它可以自己做控制,
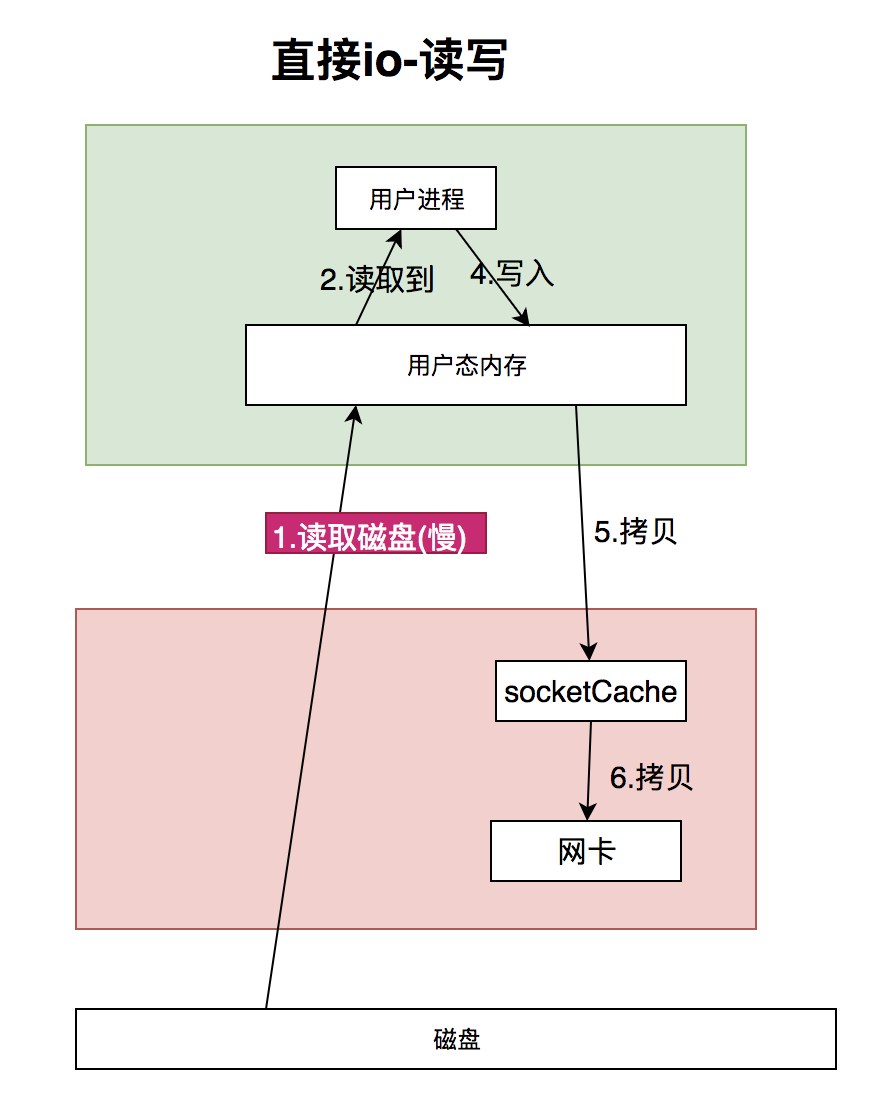
直接i
2.2缓存io(标准 I/O)
由于从磁盘读取到用户内存很慢.因此操作系统给我们做了一层优化,那就是再加一层缓存.这种设计也是随处可见的,例如为了解决cpu和内存的性能差异,引入了L1,L2,L3缓存.
就是pageCache.默认情况下,我们读写磁盘数据都会使用pageCache,是不是使用直接io一定错嘞?NO!,总结下直接io的优缺点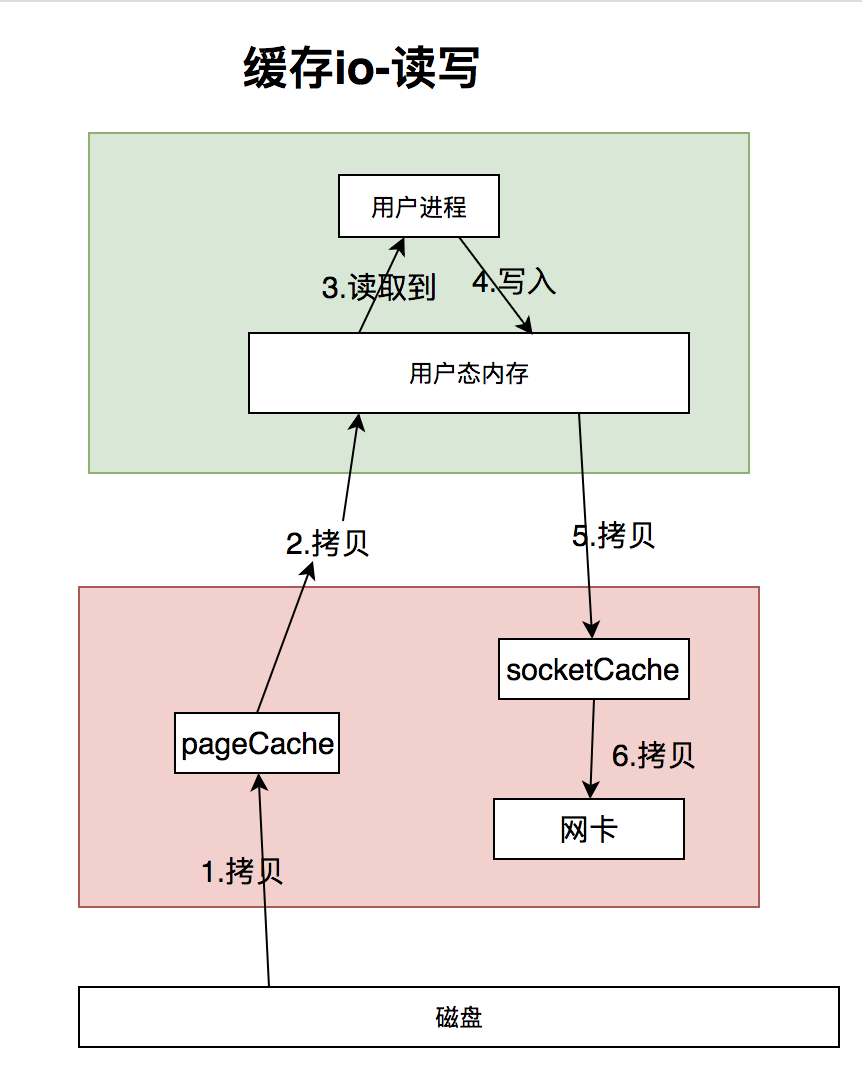
优点:
1.节约内存.少了一个pageCache的开销(可以free 查看pageCache).
2.可以自己控制.更灵活.例如一些自缓存的系统,可以自己设计缓存实现,比较常见的是数据库系统.
缺点:
1.无法直接从pageCache读取,pageCache是内存读取,比较快,pageCache做了预读优化,减少读盘次数.
2.读的话需要读取磁盘,慢;写的话,需要刷盘成功,也慢.
例如,mysql中写binlog为什么很快,其实默认就是写到了pageCache中,然后通过设置fSync策略,设置什么时候刷新到磁盘.
pageCache刷盘有一定条件.
- 用户进程调用sync()或者fsync()
- 系统调用空闲内存低于特定阈值
- 脏页的数据在内存中驻留的时间超过一个特定阈值
3.如果读大文件,会浪费,因为大文件不会读很多次.浪费内存,导致小的文件也用不了pageCache,而且大文件都连续存储,读磁盘也可以.即使用了pageCache,还是得读到内存,多了一次拷贝
缓存io
2.3 mmap
从缓存io中可以看到,使用pageCache多了一次内存拷贝.那么我们能不能优化这次拷贝呢?使用mmap,可以把用户态的内存映射到内核态.回忆一下,用户虚拟地址的布局.
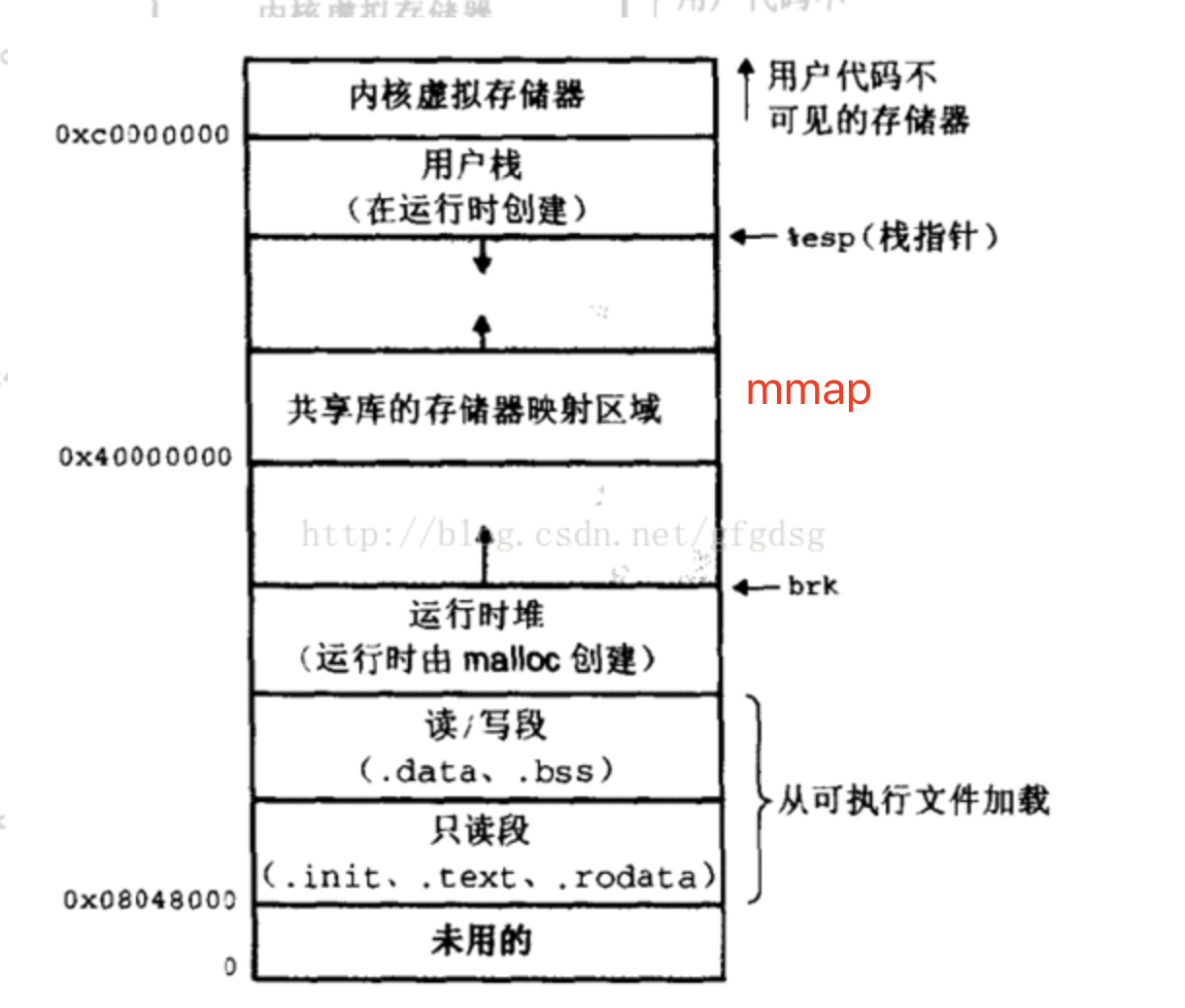
虚拟地址布局
其中在用户区有一段是用来做内存映射的.我们也是基于这段可以申请一段内存,和用户态内存映射在同一个地址.
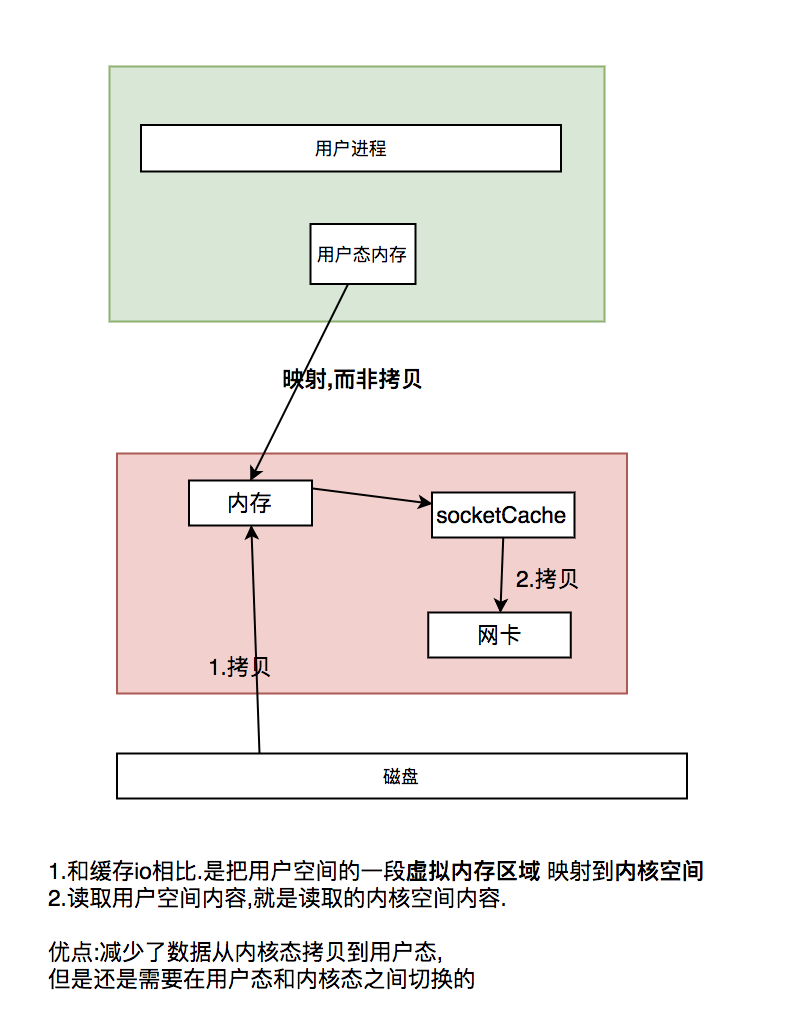
mmap 中内核缓存就是pageCache.
2.4 sendFile
mmap减少了一次内核空间到用户空间的拷贝.但是还是避免不了程序从用户态到内核态的切换.
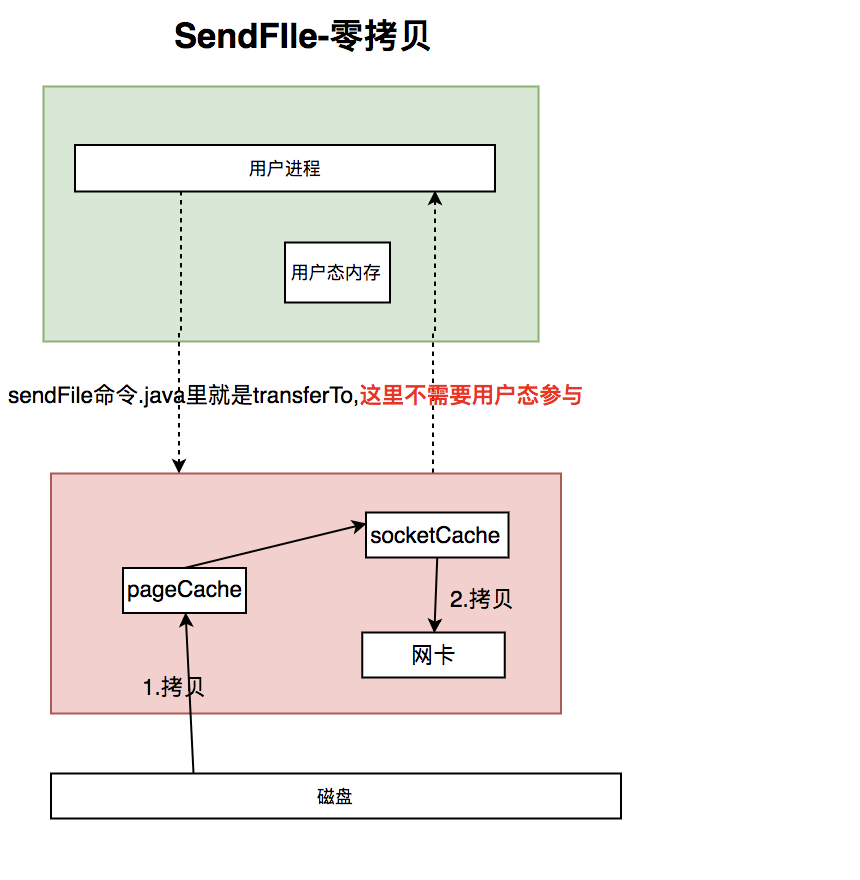
sendFile
可以看到,只需要磁盘-->pageCache-->socket缓冲区--->网卡缓冲区.不需要用户态/内核态切换.
例如:
kafka的broker到consumer的消息发送,就是使用的sendFile,即零拷贝. 扩展下知识点:producer到broker可以用sendFile吗?不行,因为有校验逻辑,或者压缩策略不一致的话需要解压缩和重新压缩.所以必须得读到用户空间,这个没办法,除非你的producer的数据读过来之后,你可以不操作,并且直接指定写到哪个磁盘文件里.
扩展: socket缓冲区到网卡的拷贝,可以省去吗?
其实socketCache和网卡直接的拷贝,也可以去除.需要用到一个支持收集操作的网络接口。主要的方式是待传输的数据可以分散在存储的不同位置上,而不需要在连续存储中存放。这样一来,从文件中读出的数据就根本不需要被拷贝到 socket 缓冲区中去,而只是需要将缓冲区描述符传到网络协议栈中去,之后其在缓冲区中建立起数据包的相关结构,然后通过 DMA 收集拷贝功能将所有的数据结合成一个网络数据包。网卡的 DMA 引擎会在一次操作中从多个位置读取包头和数据。Linux 2.4 版本中的 socket 缓冲区就可以满足这种条件,这种方法不但减少了因为多次上下文切换所带来开销,同时也减少了处理器造成的数据副本的个数。对于用户应用程序来说,代码没有任何改变。
2.5.socket缓冲区
再说下socket缓冲区,以write为例,当用户调用socket.write时,其实会把数据从用户空间拷贝到内核空间.也就是socket缓冲区.每个socket创建时,都会分配一定大小的读缓冲区和写缓冲区这两个互不影响.大小可以自由配置.可以参考另一篇socket缓冲区/sk_buffer/滑动窗口关系_责任全在mg的博客-CSDN博客_sk_buffer
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)