背景
单片机端常用的中文显示字符集是GB2312, 相对于UTF-8表示中文时更节省空间, 但是Linux端为了通用及兼容性常采用UTF-8作为字符编码, 为了保持编码的的统一, 网络通信时单片机内部将GB2312转为UTF-8发送给Linux, 于是就有了这个动机;
常见字符编码介绍
GB2312
GB/T 2312,GB/T 2312–80 或 GB/T 2312–1980 是中华人民共和国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,通常简称GB(“国标”汉语拼音首字母),又称GB0。
GB/T 2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符。其收录的汉字已经覆盖中国大陆99.75%的使用频率。但对于人名、古汉语等方面出现的罕用字和繁体字,GB/T 2312不能处理,因此后来GBK及GB 18030汉字字符集相继出现以解决这些问题。
有两种不同的GB/T 2312实现,在它们之间存在少量的差别,其中至少有一个是错误的。GBK子集与GBK/GB 18030兼容,GB2312.TXT则不兼容。
分区表示
GB/T 2312 中对所收汉字进行了“分区”处理,每区含有94个汉字/符号,共计94个区。实际上,GB/T 2312 只使用了87区。
用所在的区和位来表示字符(实际上就是码位)的方法称为区位码(或许叫“区位号”更为恰当)。例如“万”字在45区82位,所以“万”字的区位码是 45-82(45是“区码”,82是“位码”)。在储存进电脑时,电脑会在区位码上加上特定数字后才保存进内存以确保和其他编码兼容(如 ASCII)。转码后,区位码的“区码”会变成“高位字节”,而“位码”会变成“低位字节”。
下列是 GB/T 2312 分区后在区段内储存的字符:
- 01~09区(682个):特殊符号、数字、英文字符、制表符等,包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母等在内的682个全角字符;
- 10~15区:空区,留待扩展;在附录3,第10区推荐作为 GB 1988–80 中的94个图形字符区域(即第3区字符之半形版本)。
- 16~55区(3755个):常用汉字(也称一级汉字),按拼音排序;
- 56~87区(3008个):非常用汉字(也称二级汉字),按部首/笔画排序;
- 88~94区:空区,留待扩展。
字节结构
在 GB 2312 内,每个汉字及符号的码位使用两个字节来表示。第一个字节称为“高位字节”,对应分区的编号(把区位码的“区码”加上特定值);第二个字节称为“低位字节”,对应区段内的个别码位(把区位码的“位码”加上特定值)。
把“区码”和“位码”分别加上160(十六进制为0×A0)也可以得到相同的机内码表示,这种格式也就是EUC。使用GB/T 2312的程序通常采用 EUC 储存方法,以便兼容于 ASCII。这种格式称为EUC-CN(此外还有ISO 2022-CN)。浏览器编码表上的“GB2312”就是指这种表示法。
GBK
汉字内码扩展规范,简称GBK,全名为《汉字内码扩展规范(GBK)》1.0版。GBK收录21886个汉字和图形符号,其中汉字(包括部首和构件)21003个,图形符号883个。GBK的K为“扩展”的汉语拼音(kuòzhǎn)第一个声母。
GBK 只为 “技术规范指导性文件”,不属于国家标准。国家质量技术监督局于2000年3月17日推出了GB 18030-2000标准,以取代GBK。GB 18030-2000除保留全部GBK编码汉字,在第二字节把能使用范围再度进行扩展,增加了大约一百个汉字及四字节编码空间,但是 将GBK作为子集全部保留。
根据微软资料,GBK是对GB2312-80的扩展,也就是CP936字码表(Code Page 936)的扩展(之前CP936和GB 2312-80一模一样),最早实现于Windows 95简体中文版。
编码方式
字符有一字节和双字节编码,00–7F范围内是第一个字节,和ASCII保持一致,此范围内严格上说有96个文字和32个控制符号。
之后的双字节中,前一字节是双字节的第一位。总体上说第一字节的范围是81–FE(也就是不含80和FF),第二字节的一部分领域在40–7E,其他领域在80–FE。
具体来说,定义的是下列字节:
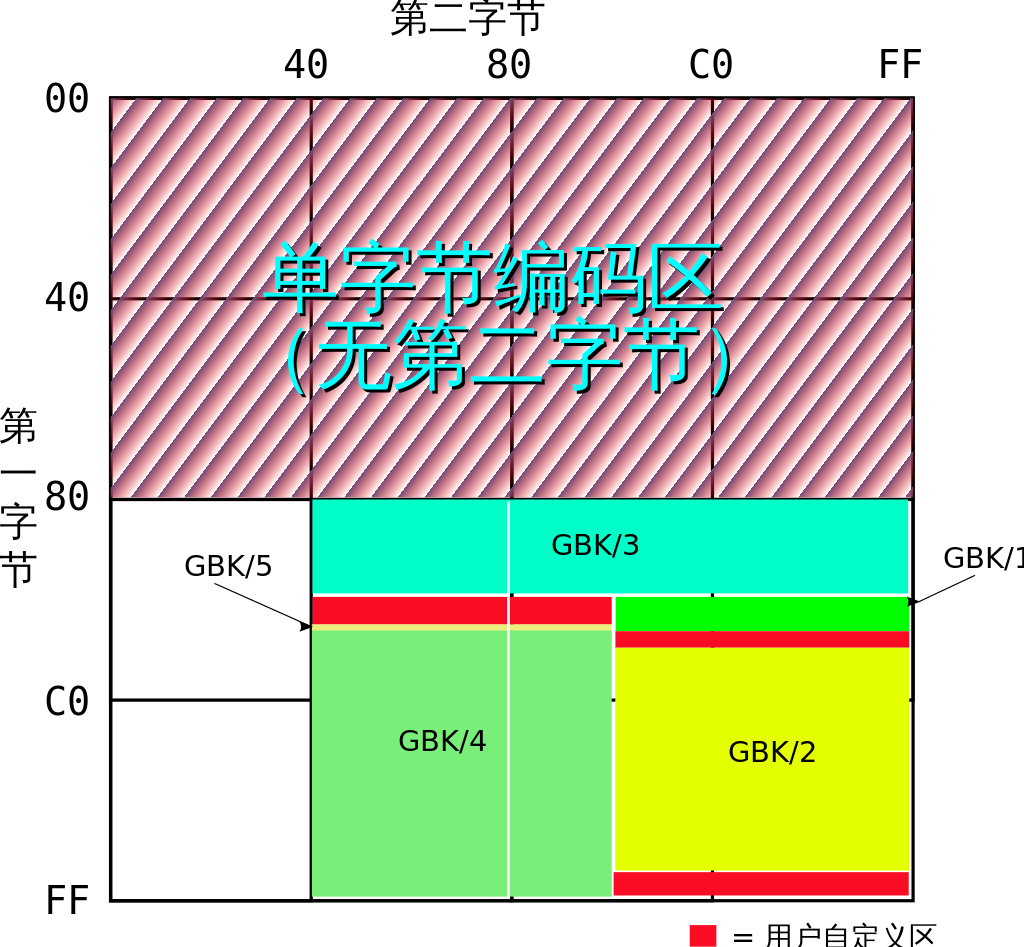
GBK的编码范围
| 范围 | 第1字节 | 第2字节 | 编码数 | 字数 |
|---|
| 水准GBK/1 | A1–A9 | A1–FE | 846 | 717 |
| 水准GBK/2 | B0–F7 | A1–FE | 6,768 | 6,763 |
| 水准GBK/3 | 81–A0 | 40–FE (7F除外) | 6,080 | 6,080 |
| 水准GBK/4 | AA–FE | 40–A0 (7F除外) | 8,160 | 8,160 |
| 水准GBK/1 | A8–A9 | 40–A0 (7F除外) | 192 | 166 |
| 用户定义 | AA–AF | A1–FE | 564 | |
| 用户定义 | F8–FE | A1–FE | 192 | |
| 用户定义 | A1–A7 | 40–A0 (7F除外) | 672 | |
| 合计 | | | 23,940 | 21,886 |
双字节符号可以表达的64K空间如下图所示。绿色和黄色区域是GBK的编码,红色是用户定义区域。没有颜色区域是不正确的代码组合。
GB18030
GB 18030,全称《信息技术 中文编码字符集》,是中华人民共和国国家标准所规定的变长多字节字符集。其对GB 2312-1980完全向后兼容,与GBK基本向后兼容,并支持Unicode(GB 13000)的所有码位。GB 18030共收录汉字70,244个。
GB 18030主要有以下特点:
- 采用变长多字节编码,每个字可以由1个、2个或4个字节组成。
- 编码空间庞大,最多可定义161万个字符。
- 完全支持Unicode,无需动用造字区即可支持中国国内少数民族文字、中日韩和繁体汉字以及emoji等字符。
- GB 18030在微软视窗系统中的代码页为54936。
字节结构
GB 18030包含三种长度的编码:单字节的ASCII、双字节的GBK(略带扩展)、以及用于填补所有Unicode码位的四字节UTF区块。GBK双字节部分通过查表定义,而四字节部分则根据之前两个部分没有提到的通用字符集码位顺序填补。
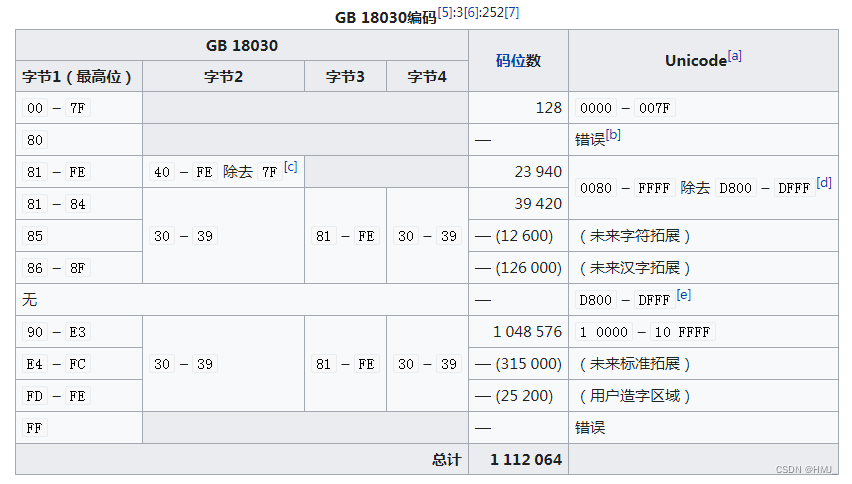
一、二字节区块基本就是GBK编码,另外加上了专门的欧元字符、竖排版本的标点符号,以及造字区对Unicode造字区的对应。四字节区块可以视作两段形似GBK二字节区块结构的部分,每段的第一字节可以为0x81到0xFE,第二字节为0x30到0x39。由于结构类似,能够安全于GBK的字符串搜索程序对于GB 18030来说也基本安全(正如基于字节的搜索程序对于EUC、UTF-8也基本安全一般。)

Unicode
Unicode,联盟官方中文名称为统一码,是计算机科学领域的业界标准。它整理、编码了世界上大部分的文字系统。
在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符。在基本多文种平面里的所有字符,要用四个数字(即2字节,共16位,例如U+4AE0,共支持六万多个字符);在零号平面以外的字符则需要使用五或六个数字。旧版的Unicode标准使用相近的标记方法,但却有些微小差异:在Unicode 3.0里使用“U-”然后紧接着八个数字,而“U+”则必须随后紧接着四个数字。
编码方式
统一码的编码方式与ISO 10646的通用字符集概念相对应。目前实际应用的统一码版本对应于UCS-2,使用16位的编码空间。也就是每个字符占用2个字节。这样理论上一共最多可以表示216(即65536)个字符。基本满足各种语言的使用。实际上当前版本的统一码并未完全使用这16位编码,而是保留了大量空间以作为特殊使用或将来扩展。
上述16位统一码字符构成 基本多文种平面。最新的统一码版本定义了16个辅助平面,两者合起来至少需要占据21位的编码空间,比3字节略少。但事实上辅助平面字符仍然占用4字节编码空间,与UCS-4保持一致。未来版本会扩充到ISO 10646-1实现级别3,即涵盖UCS-4的所有字符。UCS-4是更大而尚未填充完全的31位字符集,加上恒为0的首位,共需占据32位,即4字节。理论上最多能表示231个字符,完全可以涵盖一切语言所用的符号。
基本多文种平面的字符的编码为U+hhhh,其中每个h代表一个十六进制数字,与UCS-2编码完全相同。而其对应的4字节UCS-4编码后两个字节一致,前两个字节则所有位均为0。
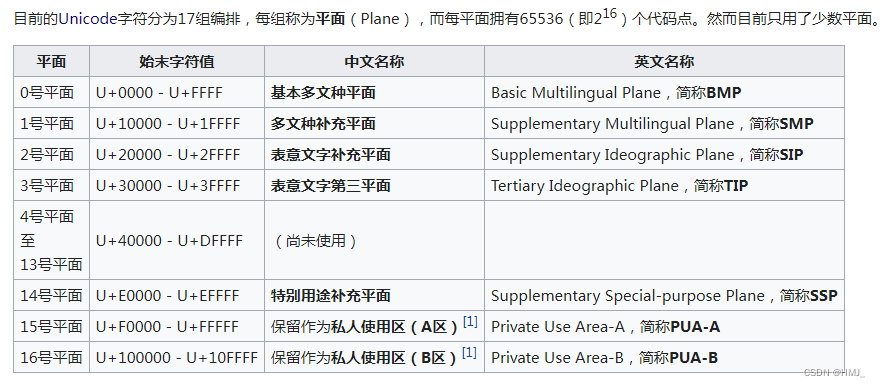
第 0 平面(或者说基本多文种平面)中的码点,都可以用一个 UTF-16 单位来编码,或者以 UTF-8 来编码的话,会使用一、二或三个字节。而第 1 到 16 平面(或称辅助平面)中的码点,UTF-16 会以代理对的方式来使用,而 UTF-8 则会编码成 4 个字节。
在每个平面中,会先将相关的字符集结为区段的形式。虽然区段可以是任意大小,但会以 16 个码点的倍数,且通常是 128 个码点的倍数。而一份文稿中使用到的区段,可能会散布在多个区段中。
实现方式
Unicode的实现方式不同于编码方式。一个字符的Unicode编码确定。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)。
例如,如果一个仅包含基本7位ASCII字符的Unicode文件,如果每个字符都使用2字节的原Unicode编码传输,其第一字节的8位始终为0。这就造成了比较大的浪费。对于这种情况,可以使用UTF-8编码,这是变长编码,它将基本7位ASCII字符仍用7位编码表示,占用一个字节(首位补0)。而遇到与其他Unicode字符混合的情况,将按一定算法转换,每个字符使用1-3个字节编码,并利用首位为0或1识别。这样对以7位ASCII字符为主的西文文档就大幅节省了编码长度(具体方案参见UTF-8)。类似的,对未来会出现的需要4个字节的辅助平面字符和其他UCS-4扩充字符,2字节编码的UTF-16也需要通过一定的算法转换。
UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。属于Unicode标准的一部分。
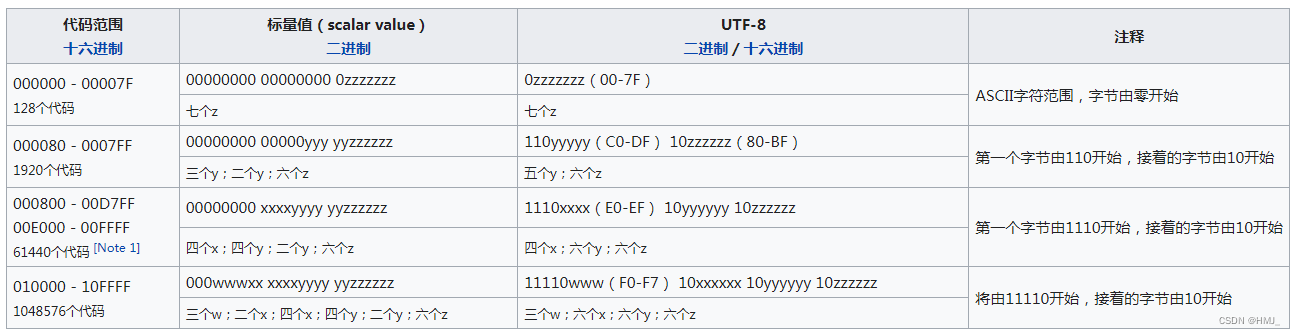
UTF-8使用一至六个字节为每个字符编码:
- 128个US-ASCII字符只需一个字节编码(Unicode范围由
U+0000至U+007F)。 - 带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要两个字节编码(Unicode范围由
U+0080至U+07FF)。 - 其他基本多文种平面(BMP)中的字符(这包含了大部分常用字,如大部分的汉字)使用三个字节编码(Unicode范围由
U+0800至U+FFFF)。 - 其他极少使用的Unicode 辅助平面的字符使用四至六字节编码(Unicode范围由
U+10000至U+1FFFFF使用四字节,Unicode范围由U+200000至U+3FFFFFF使用五字节,Unicode范围由U+4000000至U+7FFFFFFF使用六字节)。
对上述提及的第四种字符而言,UTF-8使用四至六个字节来编码似乎太耗费资源了。但UTF-8对所有常用的字符都可以用三个字节表示,而且它的另一种选择,UTF-16编码,对前述的第四种字符同样需要四个字节来编码,所以要决定UTF-8或UTF-16哪种编码比较有效率,还要视所使用的字符的分布范围而定。
2003年11月UTF-8被RFC 3629重新规范,只能使用原来Unicode定义的区域,U+0000到U+10FFFF,也就是说 最多四个字节。

编码方式
实现思路及代码
参考暴力法获得gb2312和utf-8互转的查找表文章中, 利用Python中的编码库, 进行转换解析打印出可用的对应表;
import struct
global table_file, count
count = 0
table_file = open("gbk_to_utf8.c", "w+")
table_file.write("static const unsigned short gbkUcs2Tab[][2]={\n")
for i in range(65536):
hi_byte = i >> 8
lo_byte = i & 0xff
hz = struct.pack('<BB', hi_byte, lo_byte)
try:
hz = hz.decode(encoding='gb2312')
if len(hz) == 1:
code_gb2312 = hz.encode(encoding='gb2312')
gb_val = code_gb2312[0] * 256 + code_gb2312[1]
str = '\t{' + hex(gb_val) + ', ' + hex(ord(hz)) + '}, //' + hz + '\n'
print(str, end='')
table_file.write(str)
count+=1
except UnicodeError as unierr:
pass
print('valid num %d' % count)
table_file.write("};\n")
table_file.close()
然后在生成的gb2312_to_utf8.c中添加以下函数:
unsigned short gbk_to_ucs2(unsigned short gbk)
{
int low = 0, high = sizeof(gbkUcs2Tab)/4 - 1;
while(low <= high){
int mid = (high - low) / 2 + low;
int num = gbkUcs2Tab[mid][0];
if (num == gbk) {
return gbkUcs2Tab[mid][1];
} else if (num > gbk) {
high = mid - 1;
} else {
low = mid + 1;
}
}
return 0;
};
int enc_ucs2_to_utf8_one(unsigned short unic, unsigned char *pOutput)
{
if ( unic <= 0x007F )
{
*pOutput = (unic & 0x7F);
return 1;
}
else if ( unic >= 0x0080 && unic <= 0x07FF )
{
*(pOutput+1) = (unic & 0x3F) | 0x80;
*pOutput = ((unic >> 6) & 0x1F) | 0xC0;
return 2;
}
else if ( unic >= 0x0800 && unic <= 0xFFFF )
{
*(pOutput+2) = (unic & 0x3F) | 0x80;
*(pOutput+1) = ((unic >> 6) & 0x3F) | 0x80;
*pOutput = ((unic >> 12) & 0x0F) | 0xE0;
return 3;
}
return 0;
}
int gbk_convert_to_utf8(unsigned char* gbk, unsigned char* utf8, int utf8_size)
{
int i, gbk_len, gbk_val, ucs2_val, utf8_len, ret;
unsigned char tmp[4];
gbk_len = strlen((char *)gbk);
utf8_len = 0;
for(i = 0; i < gbk_len; i++)
{
ret = 0;
if(gbk[i] <= 0xA0) {
tmp[0] = gbk[i];
ret = 1;
}
else if ((i+1 < gbk_len) && gbk[i+1] > 0xA0)
{
gbk_val = (gbk[i] << 8) + gbk[i+1];
i++;
ucs2_val = gbk_to_ucs2(gbk_val);
ret = enc_ucs2_to_utf8_one(ucs2_val, tmp);
}
else
{
continue;
}
if(utf8_len + ret > utf8_size) {
return -2;
}
memcpy(utf8+utf8_len, tmp, ret);
utf8_len += ret;
}
return utf8_len;
}
然后使用gbk_convert_to_utf8进行转换即可;
参考文章
- GB2312
- 汉字内码扩展规范
- Code page 936 (Microsoft Windows)
- GB18030
- Unicode
- Unicode字符平面映射
- UTF-8
- GB2312、GBK、GB18030 这几种字符集的主要区别是什么
- 暴力法获得gb2312和utf-8互转的查找表
10.stm32单片机平台上ASCII(GBK,GB2312)转unicode转UTF-8
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)