在json模块中
将json转换为dict数据的方法有:load()、loads()
其中,load()方法从文件中提取数据进行转换
将dict转换为json数据的方法有:dump()、dumps()
其中,dump()方法将转换为的json数据写入文件
参考python官方文档
https://docs.python.org/zh-cn/3/library/json.html
一、load()的使用
load()方法完整定义:
json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
使用son.load(file)将 fp (一个支持 .read() 并包含一个 JSON 文档的 text file 或者 binary file) 反序列化为一个 Python 对象。
>>>import json
>>>f2=open('./test.json','r')
>>>dict = json.load(f2)
>>>print(dict)
[u'foo', {u'bar': [u'baz', None, 1.0, 2]}]
二、loads()的使用
son.loads()的完整定义:
json.loads(s, *, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
使用son.loads(s)将dict类型变量s转换为json类型
>>> import json
>>> json.loads('["foo", {"bar":["baz", null, 1.0, 2]}]')
['foo', {'bar': ['baz', None, 1.0, 2]}]
三、dump()的使用
完整dump()函数定义
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
简单使用json.dump(obj,fp)将obj转变为json格式并输出到fp中,注意fp必须支持write()方法
>>>import json
>>>f=open('./test.json','w')
>>>json.dump(['foo', {'bar': ('baz', None, 1.0, 2)}],f)
>>>f.close()
然后,打开test.json文件查看结果:

如果 skipkeys 是 true (默认为 False),那么那些不是基本对象(包括 str, int、float、bool、None)的字典的键会被跳过;否则引发一个 TypeError。
如果 ensure_ascii 是 true (即默认值),输出保证将所有输入的非 ASCII 字符转义。如果 ensure_ascii 是 false,这些字符会原样输出。
如果 check_circular 是false (默认为 True),那么容器类型的循环引用检验会被跳过并且循环引用会引发一个 OverflowError (或者更糟的情况)。
如果 allow_nan 是 false(默认为 True),那么在对严格 JSON 规格范围外的 float 类型值(nan、inf 和 -inf)进行序列化时会引发一个 ValueError。如果 allow_nan 是 true,则使用它们的 JavaScript 等价形式(NaN、Infinity 和 -Infinity)。
如果 indent 是一个非负整数或者字符串,那么 JSON 数组元素和对象成员会被美化输出为该值指定的缩进等级。如果缩进等级为零、负数或者 “”,则只会添加换行符。
>>>import json
>>>f=open('./test.json','w')
>>>json.dump(['foo', {'bar': ('baz', None, 1.0, 2)}],f,indent=2)
>>>f.close()
打开test.json文件查看结果:
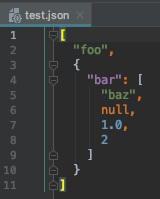
四、dumps()的使用
dumps()方法的完整定义
json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
json.dumps()将 obj 序列化为 JSON 格式的 str。 其参数的含义与 dump() 中的相同。
>>> import json
>>> json.dumps([1, 2, 3, {'4': 5, '6': 7}], separators=(',', ':'))
'[1,2,3,{"4":5,"6":7}]'
>>>print(json.dumps({'4': 5, '6': 7}, sort_keys=True, indent=4))
{
"4": 5,
"6": 7
}
其中,JSON 中的键-值对中的键永远是 str 类型的。当一个对象被转化为 JSON 时,字典中所有的键都会被强制转换为字符串。这所造成的结果是字典被转换为 JSON 然后转换回字典时可能和原来的不相等。换句话说,如果 x 具有非字符串的键,则有 loads(dumps(x)) != x。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)