所有的分类与回归算法中心思想大致是一样的,那就是根据现有带标签的数据集训练一个分类器模型,然后对待未知的样本,根据训练好的分类模型来判定它属于哪个类。分类与回归的区别在我看来就是标签连续与否的区别,若标签连续,则是回归,若标签离散,则是分类。
数据集中的每个样本的特征都是相同维度的,生活中我们常遇到的是根据某个样本少量的特征就可以确定这个样本属于哪个类,比如可以根据一个人的长相、身高、文凭、收入、爱好、性格等特征来决定是否与其进一步交往。当这些特征的特征值确定下来之后,就能唯一的确定是否与其交往。
像这样的决策我们每个人每天都在面对,如果今天不下雨,科研搞完了、有人的情况下晚上去打球吧;如果这周工作完成了,没有意外情况发生、那么周末去看场电影吧等等不胜枚举。
决策树是一种基本的分类与回归方法。本文主要讨论用于分类的决策树。决策树模型呈树形结构,在分类问题中,表示基于特征对样本进行分类的过程。决策树最著名的有ID3算法和C4.5算法,本文主要介绍ID3算法。
ID3算法是决策树的一种,它是基于奥卡姆剃刀原理的,即用尽量用较少的东西做更多的事。ID3算法, 即Iterative Dichotomiser 3,迭代二叉树3代,是Ross Quinlan发明的一种决策树算法,这个算法的基础就是上面提到的奥卡姆剃刀原理,越是小型的决策树越优于大的决策树,尽管如此,也不总 是生成最小的树型结构,而是一个启发式算法。
在信息论中,期望信息越小,那么信息增益就越大,从而纯度就越高。ID3算法的核心思想就是以信息增益来度量属性的选择,选择分裂后信息增益最大的属性进行分裂。该算法采用自顶向下的贪婪搜索遍历可能的决策空间。
下面以一个例子展开讲解:
下表是一个由15个样本组成的贷款申请训练数据。数据包括贷款申请人的4个特征:第1个特征是年龄,有三个可能值:青年,中年,老年;第2个特征是有工作,有2个可能值:是,否;第3个特征是有自己的房子,有两个可能值:是,否;第四个特征是信贷情况,有3个可能值:非常好,好,一般。表的最后一列是类别,是否同意贷款,取二个值:是,否。
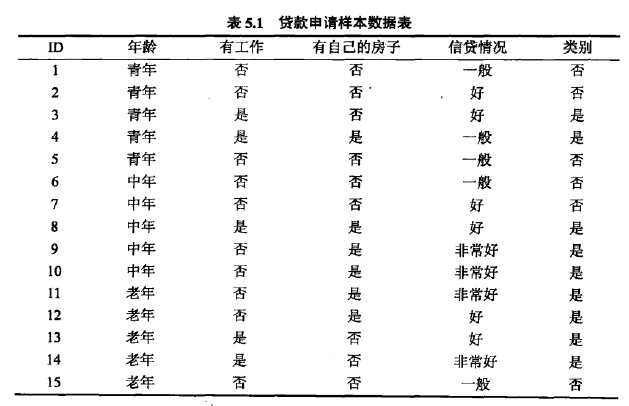
希望通过所给的训练数据学习一个贷款申请的模型,用以对未来的贷款申请进行分类,即当新的客户提出贷款申请时,根据申请人的特征利用该模型决定是否批准贷款申请。
由上可见,我们可以根据一个用户的年龄、有工作、有自己的房子以及信贷情况等来唯一的确定是否通过这个用户的贷款申请。但是我们仔细观察以上这张表,凡是有自己的房子的用户都会通过贷款申请,而没有房子的其他用户则会继续考虑其他因素。
根据以上问题,我们可以构建许多的决策树模型来解决,但是怎样构建一颗高效的决策树即使用尽量小的计算复杂度来决定一个样本属于那个类呢?反应在决策树中则是该选择哪个特征来作为头结点是需要考虑的问题。
ID3算法使用信息增益来解决这个问题,ID3算法特征选取时,是选择信息增益最大的特征,其中信息增益的计算方式如下:
g(D,A)=H(D)−H(D|A)
g
(
D
,
A
)
=
H
(
D
)
−
H
(
D
|
A
)
定义数据集D的信息熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差。
H(D)=−615log615−915log915
H
(
D
)
=
−
6
15
l
o
g
6
15
−
9
15
l
o
g
9
15
其中选择有工作这一特征来计算经验条件熵:
| 条件 | 有工作(总量 = 5) | 无工作(总量 = 10) |
|---|
| 能否贷款 | 是,是,是,是,是 | 否,否,否,否,否,否 |
| | 是,是,是,是 |
H(有工作)=−55log55=0
H
(
有
工
作
)
=
−
5
5
l
o
g
5
5
=
0
H(无工作)=−610log610−410log410
H
(
无
工
作
)
=
−
6
10
l
o
g
6
10
−
4
10
l
o
g
4
10
H(D|A)=H(有工作)+H(无工作)
H
(
D
|
A
)
=
H
(
有
工
作
)
+
H
(
无
工
作
)
在决策树的每一个非叶子结点划分之前,先计算每一个属性所带来的信息增益,选择最大信息增益的属性来划分,因为信息增益越大,区分样本的能力就越强,越具有代表性,很显然这是一种自顶向下的贪心策略。以上就是ID3算法的核心思想。
ID3算法计算流程如下:
输入:训练数据集D,特征集A,阈值ϵ
输出:决策树T
(1) 若D中所有实例属于同一类Ck,则T为单结点树,并将类Ck作为该结点的类标记,返回T;
(2) 若A=∅,则T为单结点树,并将D中实例数最大的类Ck作为该结点的类标记,返回T;
(3) 否则,计算A中各特征对D的信息增益,选择信息增益最大的特征Ag;
(4) 如果Ag的信息增益小于阈值ϵ,则置T为单结点树,并将D中实例数最大的类Ck作为该结点的类标记,返回T;
(5) 否则,对Ag的每一个可能值ai,依Ag=ai将D分割为若干非空子集Di,将Di中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
(6) 对第i个子子结点,以Di为训练集,以 A−{Ag}为特征集,递归地调用步(1)~(5),得到子树Ti,返回Ti;
ID3算法的python实现
ID3算法py文件ID3Tree.py:
"""
Created on Sat Aug 25 10:39:22 2018
@author: aoanng
"""
from math import log
def createDataSet():
"""
创建数据集
"""
dataSet = [['青年', '否', '否', '一般', '拒绝'],
['青年', '否', '否', '好', '拒绝'],
['青年', '是', '否', '好', '同意'],
['青年', '是', '是', '一般', '同意'],
['青年', '否', '否', '一般', '拒绝'],
['中年', '否', '否', '一般', '拒绝'],
['中年', '否', '否', '好', '拒绝'],
['中年', '是', '是', '好', '同意'],
['中年', '否', '是', '非常好', '同意'],
['中年', '否', '是', '非常好', '同意'],
['老年', '否', '是', '非常好', '同意'],
['老年', '否', '是', '好', '同意'],
['老年', '是', '否', '好', '同意'],
['老年', '是', '否', '非常好', '同意'],
['老年', '否', '否', '一般', '拒绝'],
]
featureName = ['年龄', '有工作', '有房子', '信贷情况']
return dataSet, featureName
def splitDataSet(dataSet,axis,value):
"""
按照给定特征划分数据集
:param axis:划分数据集的特征的维度
:param value:特征的值
:return: 符合该特征的所有实例(并且自动移除掉这维特征)
"""
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reduceFeatVec = featVec[:axis]
reduceFeatVec.extend(featVec[axis+1:])
retDataSet.append(reduceFeatVec)
return retDataSet
def calcShannonEnt(dataSet):
"""
计算训练数据集中的Y随机变量的香农熵
:param dataSet:
:return:
"""
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] =0
labelCounts[currentLabel] +=1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries
shannonEnt -= prob * log(prob,2)
return shannonEnt
def calcConditionalEntropy(dataSet,i,featList,uniqueVals):
"""
计算x_i给定的条件下,Y的条件熵
:param dataSet: 数据集
:param i: 维度i
:param featList: 数据集特征列表
:param unqiueVals: 数据集特征集合
:return: 条件熵
"""
ce = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet) / float(len(dataSet))
ce += prob * calcShannonEnt(subDataSet)
return ce
def calcInformationGain(dataSet,baseEntropy,i):
"""
计算信息增益
:param dataSet: 数据集
:param baseEntropy: 数据集中Y的信息熵
:param i: 特征维度i
:return: 特征i对数据集的信息增益g(dataSet | X_i)
"""
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = calcConditionalEntropy(dataSet,i,featList,uniqueVals)
infoGain = baseEntropy - newEntropy
return infoGain
def chooseBestFeatureToSplitByID3(dataSet):
"""
选择最好的数据集划分
:param dataSet:
:return:
"""
numFeatures = len(dataSet[0]) -1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
infoGain = calcInformationGain(dataSet,baseEntropy,i)
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def createTree(dataSet,featureName,chooseBestFeatureToSplitFunc = chooseBestFeatureToSplitByID3):
"""
创建决策树
:param dataSet: 数据集
:param featureName: 数据集每一维的名称
:return: 决策树
"""
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) ==1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplitFunc(dataSet)
bestFeatLabel = featureName[bestFeat]
myTree ={bestFeatLabel:{}}
del (featureName[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = featureName[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree
dataSet,featureName = createDataSet()
myTree = createTree(dataSet,featureName)
print(myTree)
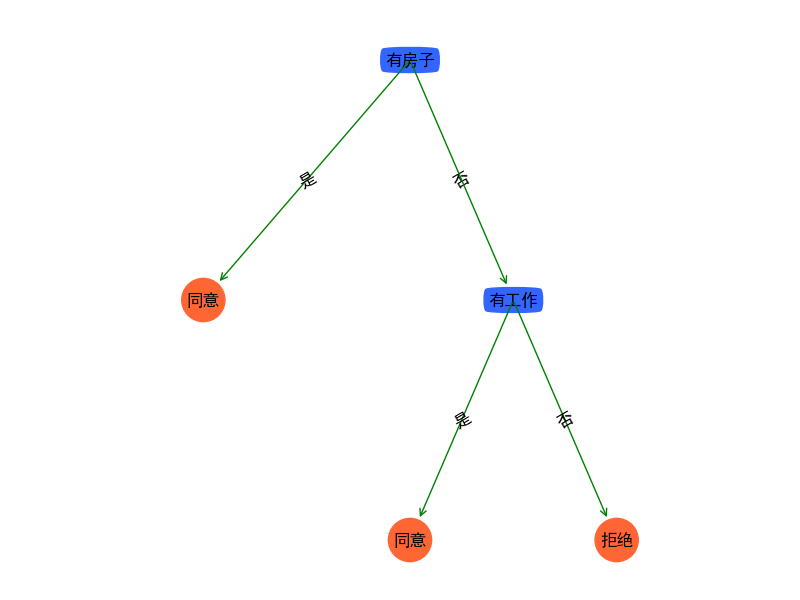
可视化treePlotter.py文件:
"""
Created on Sat Aug 25 11:04:40 2018
@author: aoanng
"""
import matplotlib.pyplot as plt
decisionNode = dict(boxstyle="round4", color='#3366FF')
leafNode = dict(boxstyle="circle", color='#FF6633')
arrow_args = dict(arrowstyle="<-", color='g')
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree)
firstStr = list(myTree.keys())[0]
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5 / plotTree.totalW;
plotTree.yOff = 1.0;
plotTree(inTree, (0.5, 1.0), '')
plt.show()
完整调用main.py:
"""
Created on Sat Aug 25 10:00:16 2018
@author: aoanng
"""
from pylab import *
import treePlotter
from ID3Tree import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
myDat, labels = createDataSet()
myTree = createTree(myDat, labels)
treePlotter.createPlot(myTree)
参考:
https://blog.csdn.net/u014688145/article/details/53212112
https://blog.csdn.net/fly_time2012/article/details/70210725
https://www.zhihu.com/question/41252833?utm_source=qq&utm_medium=social
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)