开篇几句题外话:
Lecture03——Gradient Descent 梯度下降(cost function)
说在前面:这部分分两块,一个是基于cost function的,也就是全数据集上的代价函数,另一个是从中随机抽取一个数据,基于loss function的,也就是损失函数,二者在forward、loss的函数构建、训练过程中的数据加载环节都有所区别,要注意区分,搞清搞透;
详细过程:
- 本课程的主要任务是构建第一个带有初始权重和训练过程的梯度下降模型:
- 导入
numpy和matplotlib库; - 导入数据
x_data 和 y_data; - 定义前向传播函数:
- 定义代价函数:
cost:损失函数定义为MSE:均方根误差- 此处要使用循环,把数据集中的数据对儿,一组一组地取出来,再做计算;
- 返回值需要归一化至单个数据的损失值;
- 定义梯度计算函数:
- 这个函数
gradient很有意思,也不简单:需要根据反向传播,计算出代价函数对于权重的梯度,计算结果为grad += 2 * x * (x * w - y); - 返回值同样需要归一化至单个数据的梯度;
- 创建两个空列表,因为后面绘图的时候要用:
- 开始训练:
- 循环的次数
epoch可以自定义:
- 首先调用代价函数
cost计算数据集的代价值,注意,这里要传入所有数据,而不是再去用·zip·函数配合·for·循环每次取一个,因为在`cost·函数当中,已经写过单个数据对儿从数据集调出的过程; - 再调用梯度计算函数
grad,与上个函数相同; - 核心来了——更新权重:
- 就是最经典的权重更新公式,用现有权重,减去学习率乘以梯度的乘积,每轮(epoch)训练都要循环更新;
- 此处尚不涉及权重清零的问题,这个问题后面也要详细记录,务必搞得非常透彻,因为它涉及到计算图的是否构建,以及tensor数据类型具有data和grad两个属性的问题(TBD);
- 随意打印想要看到的内容,一般是打印
x_val、y_val、loss_val; - 在循环中要把计算的结果,放进之前的空列表,用于绘图;
- 在获得了打印所需的数据列表只有,模式化地打印图像:
-略
Lecture03——Gradient Descent 梯度下降(loss function)
详细过程:
- 回头仔细看了看代码,其实区别并不大;
- 之前没理解的原因,不在于
cost和loss的区别,而在于权重更新那里我没有懂透; - 区别:
forward函数没有变化;loss、gradient函数有变化,把cost当中,原本需要把数据对儿从数据集中取出的过程,全部转移到训练过程中,这个过程不是难点,不过刚动手写的时候,就会很困惑,尤其是别的地方也有困惑,就觉得难度很大,应付不过来;
完整代码:
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
def cost(xs, ys):
cost = 0
for x, y in zip(xs, ys):
y_hat = forward(x)
cost += (y_hat - y) ** 2
return cost / len(xs)
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y)
return grad / len(xs)
print('Predict (before training)', 4, forward(4))
epoch_list = []
cost_list = []
for epoch in range(100):
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
print('Epoch:', epoch, 'w=', w, 'loss=', cost_val)
cost_list.append(cost_val)
epoch_list.append(epoch_val)
print('Predict (after training)', 4, forward(4))
plt.plot(epoch_list, cost_list)
plt.xlabel('epoch')
plt.ylabel('cost')
plt.show()
运行结果:
(后经过对比发现此图有错误,并不是想要的epoch横轴的训练损失输出曲线,正确的结果请往后文看)
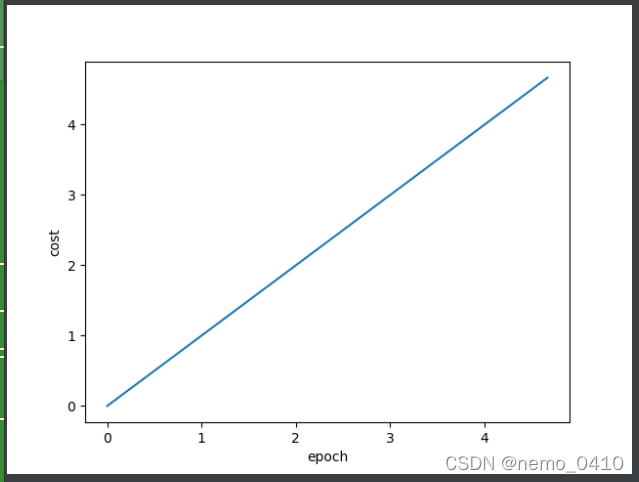
默写出的错误:
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
def cost(xs, ys):
cost = 0
for x, y in zip(xs, ys):
y_hat = forward(x)
cost += (y_hat - y) ** 2
return cost / len(xs)
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y)
return grad / len(xs)
print('Predict (before training)', 4, forward(4))
cost_list = []
grad_list = []
for epoch in range(100):
for x, y in zip(x_data, y_data):
cost_val = cost(x,y)
grad_val = gradient(x,y)
w -= 0.01 * grad_val
print('Predict (after training)', 'w=', w, 'loss=', cost_val)
cost_list.append(cost_val)
grad_list.append(grad_val)
plt.plot(epoch, cost_list)
plt.xlabel('epoch')
plt.ylabel('cost')
plt.show()
-
训练那里,不需要再去x_data和y_data当中提取数据了,直接把数据集扔进去就可以了;
-
原因是:在cost和gradient两个函数当中,已经有对数据集的提取了;
-
复原老师的代码也有错误:那个横坐标写的不对;横坐标应该是epoch的值,而不是原来写的cost_val;
-
有个错误是导致我运行失败的原因:
- 我传入
cost和gradient函数的,不再是上一篇文章中说的单个数据,而是数据集;
-
在cost和gradient函数内部也出过问题,我没有写成+=的形式,而是直接用了=;导致曲线下降趋势一直平缓;
-
+=这样写的原因在于要累加cost和grad,不是更新;这是原理没有懂透;
-
return grad / len(xs) # 这里缩进错了,导致最终输出曲线不对,非常细节的问题;return跟for循环并列缩进;作为def函数的结尾,应该是def下仅仅一级的缩进就可以了;
经过修改之后的代码:
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
def cost(xs, ys):
cost = 0
for x, y in zip(xs, ys):
y_hat = forward(x)
cost += (y_hat - y) ** 2
return cost / len(xs)
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y)
return grad / len(xs)
print('Predict (before training)', 4, forward(4))
cost_list = []
epoch_list = []
for epoch in range(100):
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
print('Predict (after training)', 'w=', w, 'loss=', cost_val)
cost_list.append(cost_val)
epoch_list.append(epoch)
plt.plot(epoch_list, cost_list)
plt.xlabel('epoch')
plt.ylabel('cost')
plt.show()
修改之后的结果:
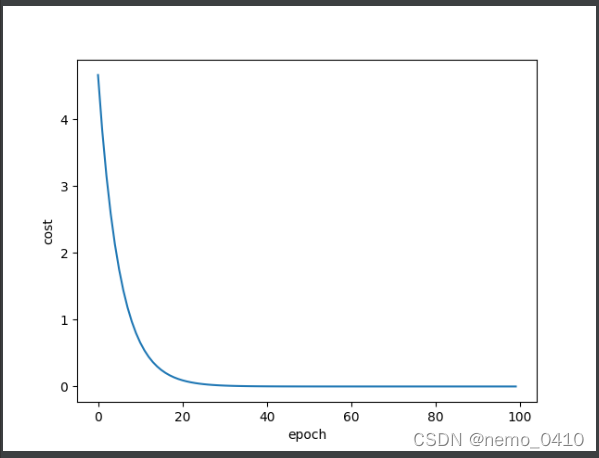
以上是整个数据集上的计算,下面是单个数据进行权重更新的计算:
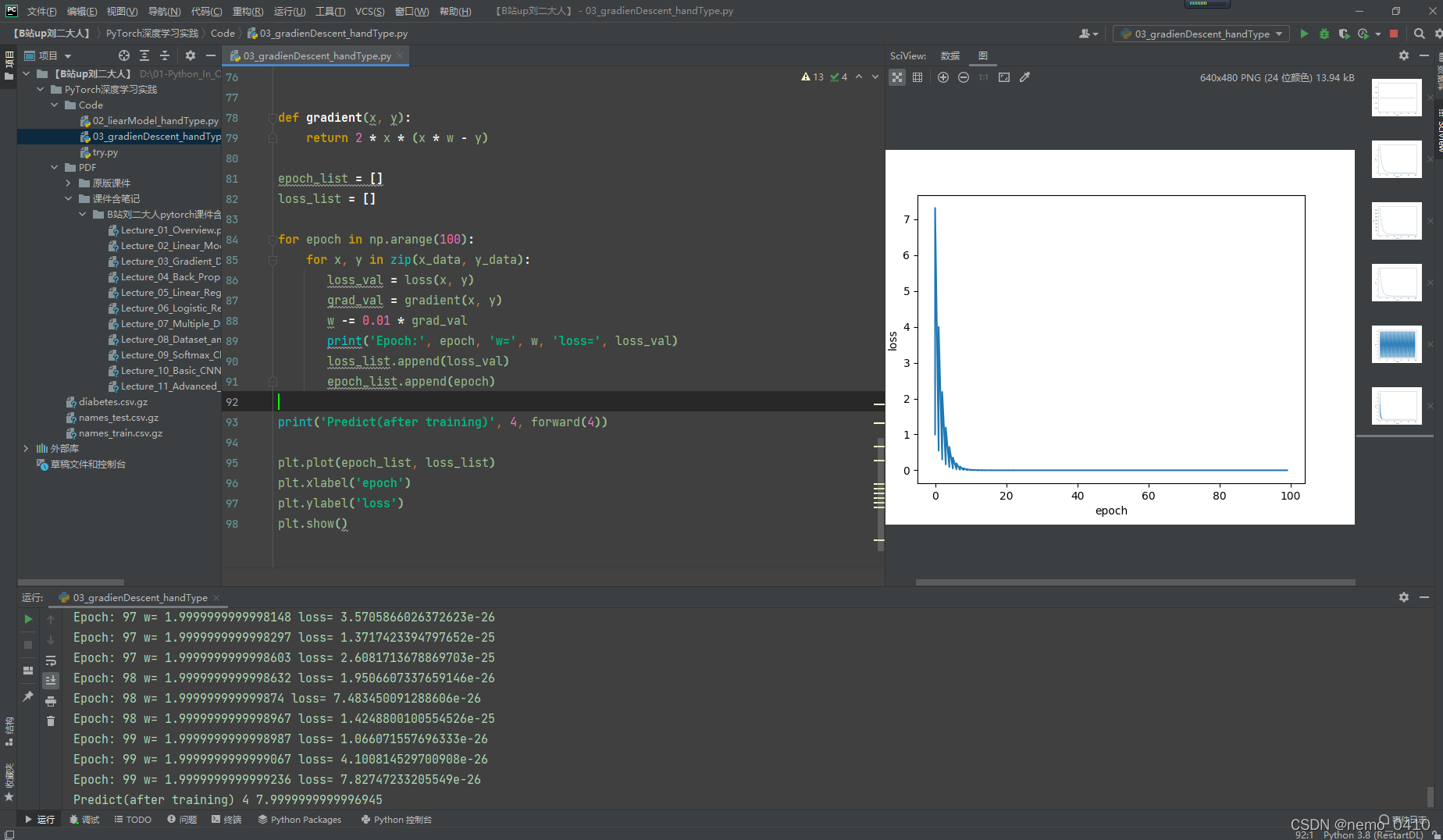
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
def loss(x, y):
y_hat = forward(x)
return (y_hat - y) ** 2
def gradient(x, y):
return 2 * x * (x * w - y)
epoch_list = []
loss_list = []
for epoch in np.arange(100):
for x, y in zip(x_data, y_data):
loss_val = loss(x, y)
grad_val = gradient(x, y)
w -= 0.01 * grad_val
print('Epoch:', epoch, 'w=', w, 'loss=', loss_val)
loss_list.append(loss_val)
epoch_list.append(epoch)
print('Predict(after training)', 4, forward(4))
plt.plot(epoch_list, loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
运行效果:
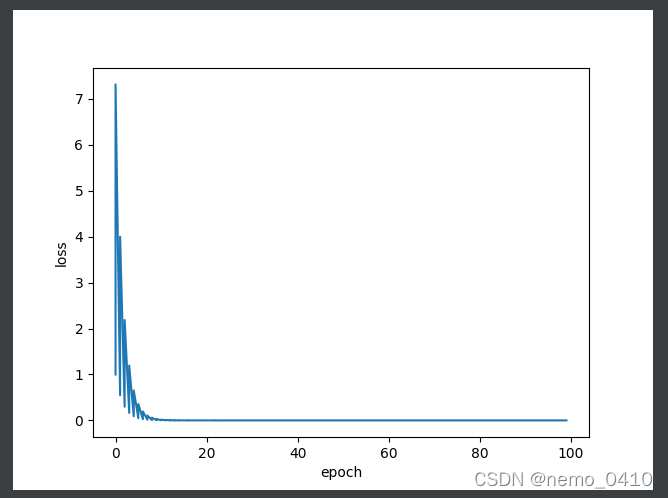
上一篇:
【Pytorch深度学习实践】B站up刘二大人之LinearModel -代码理解与实现(1/9)
下一篇:
【Pytorch深度学习实践】B站up刘二大人之 BackPropagation-代码理解与实现(3/9)
目录:
【Pytorch深度学习实践】B站up刘二大人课程笔记——目录与索引(已完结)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)