【GUI】基于Python的文本数据处理(串口解析 0D 0A结尾)
如有串口数据:
[37;22mD/NO_TAG [2023-04-24 23:01:06 ] ------------------------------------------------->>>>>> M_DADAT_GET_DAMAGE_INFO
[0m
2023/04/24 23:01:06 m_radar_parse_msg: 0000-000F: 23 55 00 85 52 01 42 04 00 00 00 D9 FD A5 02 00
2023/04/24 23:01:06 m_radar_parse_msg: 0010-001F: 00 89 FD 68 0A DA FF C1 FD 19 03 00 00 71 FD 95
2023/04/24 23:01:06 m_radar_parse_msg: 0020-002F: 05 66 FF F8 FD F2 FD 00 00 A8 FD C9 0E C6 01 D7
2023/04/24 23:01:06 m_radar_parse_msg: 0030-003F: FD B1 02 00 00 87 FD 5E 09 CA FF DB FD B4 02 00
2023/04/24 23:01:06 m_radar_parse_msg: 0040-004F: 00 8B FD DA 0B BE FF 00 00 00 00 00 00 00 00 00
2023/04/24 23:01:06 m_radar_parse_msg: 0050-005F: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
要求提取m_radar_parse_msg后的内容;
"""
Created on Fri Apr 28 09:26:36 2023
@author: ZHOU
"""
import re
def new_judg(s):
if s[-5]+s[-4]+s[-3]+s[-2]+s[-1]=="0D 0A":
s=s+'\n'
return s
path = "m_radar_parse_msg.txt"
output_path="out_m_radar_parse_msg.txt"
f=open(path, 'r', encoding="utf-8")
f_list=f.readlines()
f.close()
try:
f=open(output_path, 'w', encoding="utf-8")
except:
f=open(output_path, 'a', encoding="utf-8")
for i in f_list:
try:
s=i.split('m_radar_parse_msg: ')[1]
s=s.split('\n')[0]
s=s.split(': ')[1]
s=s.replace(' ', '')
s=re.sub(r"(?<=\w)(?=(?:\w\w)+$)", " ", s)
f.write(new_judg(s))
except:
pass
f.close()
f=open(output_path, 'r', encoding="utf-8")
f_list=f.readlines()
f.close()
f=open(output_path, 'w', encoding="utf-8")
for i in f_list:
s=i.replace(' ', '')
s=re.sub(r"(?<=\w)(?=(?:\w\w)+$)", " ", s)
f.write(s)
f.close()
输出结果:

同样的:
2023-04-25 13:37:27.983 3304 7031 D #ST2303_STI1#: [(I1CommunicationHandler.java:1079)#postSensorReport] 雷达请求主动拍摄照片
2023-04-25 13:37:27.984 3391 3852 V #ST2303_sensor#: [(LDCJOneSensor.java:207)#run] wirte package len = 11
2023-04-25 13:37:27.986 3304 7031 I #ST2303_STI1#: [(I1CommunicationHandler.java:1084)#postSensorReport] 拍照间隔不到60秒,不拍!
2023-04-25 13:37:27.986 3391 3852 V #ST2303_sensor#: [(LDCJOneSensor.java:215)#run] 收状态
2023-04-25 13:37:28.028 3391 3853 V #ST2303_sensor#: [(LDCJOneSensor.java:306)#run] ldcj mReadRunnable read returned 108
2023-04-25 13:37:28.031 3391 3853 I #ST2303_sensor#: [(Utils.java:412)#printSerialData] 23 55 01 01 52 01 49 00 00 e2 ff 32 00 a0 00 b6 00 70 00 50 00 78 00 78 00 f8 11 00 00 eb 07 eb 07 10 05 cc 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 04 00 20 0a 98 07 91 01 00 00 4b ff 36 08 3e ff 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
2023-04-25 13:37:28.033 3391 3853 V #ST2303_sensor#: [(LDCJOneSensor.java:413)#fetchPacket] buffer start:0, end:0
2023-04-25 13:37:28.034 3391 3853 V #ST2303_sensor#: [(LDCJOneSensor.java:306)#run] ldcj mReadRunnable read returned 84
2023-04-25 13:37:28.036 3391 3853 I #ST2303_sensor#: [(Utils.java:412)#printSerialData] f1 00 c7 2c d6 15 aa 09 d9 00 a7 88 fe 6e e5 92 fe 68 c5 10 e2 00 9a 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
则采用printSerialData:
"""
Created on Fri Apr 28 09:26:36 2023
@author: ZHOU
"""
import re
def new_judg(s):
if s[-5]+s[-4]+s[-3]+s[-2]+s[-1]=="0D 0A":
s=s+'\n'
return s
path = "printSerialData.txt"
output_path="out_printSerialData.txt"
f=open(path, 'r', encoding="utf-8")
f_list=f.readlines()
f.close()
try:
f=open(output_path, 'w', encoding="utf-8")
except:
f=open(output_path, 'a', encoding="utf-8")
for i in f_list:
try:
s=i.split("#printSerialData] ")[1]
s=s.split('\n')[0]
s=s.replace(' ', '')
s=re.sub(r"(?<=\w)(?=(?:\w\w)+$)", " ", s)
f.write(new_judg(s))
except:
pass
f.close()
f=open(output_path, 'r', encoding="utf-8")
f_list=f.readlines()
f.close()
f=open(output_path, 'w', encoding="utf-8")
for i in f_list:
s=i.replace(' ', '')
s=re.sub(r"(?<=\w)(?=(?:\w\w)+$)", " ", s)
f.write(s)
f.close()

还有radarOriginDataHexString:
{"damageCount":0,"damagePointInfoList":[],"originDataLength":1744,"radarFirmwareVersion":"1887f73","radarOriginDataHexString":"235500855201420100000000000000000024001B00C0FF000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000003910D0A235501015201490000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000800738040000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001D90D0A23550291520100000000000000087D0000000100020000F2011000D756C0004D2202B88006CB36000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000003F8000003D76C47043C000004179EC46000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000D1B0D0A23550291520101000000000000087C0000000100020000BF010300F253C00046EC02837FFACD10000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000003F8000003D76C47043C000004179EC46000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000E500D0A"}
"""
Created on Fri Apr 28 09:26:36 2023
@author: ZHOU
"""
import re
def new_judg(s):
if s[-5]+s[-4]+s[-3]+s[-2]+s[-1]=="0D 0A":
s=s+'\n'
return s
path = "radarOriginDataHexString.txt"
output_path="out_radarOriginDataHexString.txt"
f=open(path, 'r', encoding="utf-8")
f_list=f.readlines()
f.close()
try:
f=open(output_path, 'w', encoding="utf-8")
except:
f=open(output_path, 'a', encoding="utf-8")
for i in f_list:
try:
s=i.split('radarOriginDataHexString":"')[1]
s=s.split('"}')[0]
s=s.replace(' ', '')
s=re.sub(r"(?<=\w)(?=(?:\w\w)+$)", " ", s)
f.write(new_judg(s))
except:
pass
f.close()
f=open(output_path, 'r', encoding="utf-8")
f_list=f.readlines()
f.close()
f=open(output_path, 'w', encoding="utf-8")
for i in f_list:
s=i.replace(' ', '')
s=re.sub(r"(?<=\w)(?=(?:\w\w)+$)", " ", s)
f.write(s)
f.close()

整合起来:
"""
Created on Fri Apr 28 10:39:48 2023
@author: ZHOU
"""
import tkinter as tk
from tkinter import ttk
from tkinter.filedialog import askopenfilename
import tkinter.messagebox
import os
import re
import threading
import time
key_list = ['m_radar_parse_msg','radarOriginDataHexString','printSerialData']
def new_judg(s):
try:
strings=s[-5]+s[-4]+s[-3]+s[-2]+s[-1]
if strings=="0D 0A" or strings=="0d 0a":
s=s+'\n'
else:
s=s+' '
except:
s=s+' '
return s
def ctrl_str(s,key):
if key==key_list[0]:
s=s.split('m_radar_parse_msg: ')[1]
s=s.split('\n')[0]
s=s.split(': ')[1]
elif key==key_list[1]:
s=s.split('radarOriginDataHexString":"')[1]
s=s.split('"}')[0]
elif key==key_list[2]:
s=s.split("#printSerialData] ")[1]
s=s.split('\n')[0]
else:
s=s.split('\n')[0]
s=s.replace(' ', '')
s=re.sub(r"(?<=\w)(?=(?:\w\w)+$)", " ", s)
s=new_judg(s)
return s
def ctrl_txt(path,key):
dir_path=os.path.split(path)[0]
output_path=os.path.join(dir_path,'out_'+str(key)+'.txt')
try:
f=open(path, 'r', encoding="utf-8")
except:
return
f_list=f.readlines()
f.close()
try:
f=open(output_path, 'w', encoding="utf-8")
except:
try:
f=open(output_path, 'a', encoding="utf-8")
except:
return
for i in f_list:
try:
s=ctrl_str(i,key)
f.write(s)
except:
pass
f.close()
return output_path
def central_win(win):
win.resizable(0,0)
screenwidth = win.winfo_screenwidth()
screenheight = win.winfo_screenheight()
win.update()
width = win.winfo_width()
height = win.winfo_height()
size = '+%d+%d' % ((screenwidth - width)/2, (screenheight - height)/2)
win.geometry(size)
def gui_start():
gui=tk.Tk()
gui.title("txt串口数据处理")
gui.attributes('-topmost',0)
guifram=tk.Frame(gui,width=880, height=300)
guifram.grid_propagate(0)
guifram.grid()
central_win(gui)
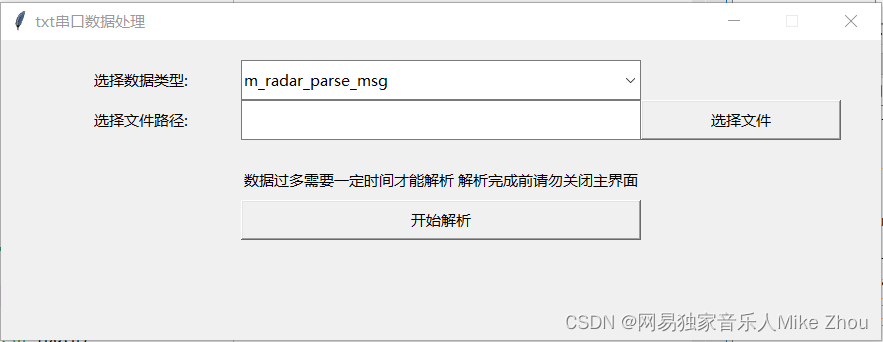
labelName=tkinter.Label(gui, text='选择数据类型:', justify=tkinter.LEFT)
labelName.place(x=40, y=20, width=200, height=40)
labelName=tkinter.Label(gui, text='选择文件路径:', justify=tkinter.LEFT)
labelName.place(x=40, y=60, width=200, height=40)
labelName=tkinter.Label(gui, text='数据过多需要一定时间才能解析 解析完成前请勿关闭主界面', justify=tkinter.LEFT)
labelName.place(x=240, y=120, width=400, height=40)
s0 = ttk.Combobox(guifram)
s0['value'] = key_list
s0['state'] = 'read-write'
s0.delete(0, tk.END)
s0.insert(0, key_list[0])
s0.place(x=240, y=20, width=400, height=40)
s1 = ttk.Entry(guifram)
s1.delete(0, tk.END)
s1['state'] = 'read-write'
s1.place(x=240, y=60, width=400, height=40)
filetype_list=[("文本文件","*.txt")]
def filefound():
filepath= askopenfilename(filetype=filetype_list)
print (filepath)
s1.delete(0, tk.END)
s1.insert(0, filepath)
def txt():
path=str(s1.get())
key=str(s0.get())
if os.path.exists(path) and key!='':
ti=time.time()
output_path=ctrl_txt(path,key)
print(output_path)
if output_path:
tk.messagebox.showinfo('解析已完成', "文件保存路径:\n"+output_path+"\n耗时:\n"+str(time.time()-ti))
else:
tk.messagebox.showinfo('关键词格式错误','关键词格式错误')
return
tk.messagebox.showinfo('文件不存在', "文件路径:\n"+path)
def doing_txt():
t=threading.Thread(target=txt)
t.setDaemon(True)
t.start()
tk.Button(guifram,text="选择文件",command=filefound).place(x=640, y=60, width=200, height=40)
tk.Button(guifram,text="开始解析",command=doing_txt).place(x=240, y=160, width=400, height=40)
gui.mainloop()
if __name__ == '__main__':
gui_start()
py打包
Pyinstaller打包exe(包括打包资源文件 绝不出错版)
依赖包及其对应的版本号
PyQt5 5.10.1
PyQt5-Qt5 5.15.2
PyQt5-sip 12.9.0
pyinstaller 4.5.1
pyinstaller-hooks-contrib 2021.3
Pyinstaller -F setup.py 打包exe
Pyinstaller -F -w setup.py 不带控制台的打包
Pyinstaller -F -i xx.ico setup.py 打包指定exe图标打包
打包exe参数说明:
-F:打包后只生成单个exe格式文件;
-D:默认选项,创建一个目录,包含exe文件以及大量依赖文件;
-c:默认选项,使用控制台(就是类似cmd的黑框);
-w:不使用控制台;
-p:添加搜索路径,让其找到对应的库;
-i:改变生成程序的icon图标。
如果要打包资源文件
则需要对代码中的路径进行转换处理
另外要注意的是 如果要打包资源文件 则py程序里面的路径要从./xxx/yy换成xxx/yy 并且进行路径转换
但如果不打包资源文件的话 最好路径还是用作./xxx/yy 并且不进行路径转换
def get_resource_path(relative_path):
if hasattr(sys, '_MEIPASS'):
return os.path.join(sys._MEIPASS, relative_path)
return os.path.join(os.path.abspath("."), relative_path)
而后再spec文件中的datas部分加入目录
如:
a = Analysis(['cxk.py'],
pathex=['D:\\Python Test\\cxk'],
binaries=[],
datas=[('root','root')],
hiddenimports=[],
hookspath=[],
hooksconfig={},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
而后直接Pyinstaller -F setup.spec即可
如果打包的文件过大则更改spec文件中的excludes 把不需要的库写进去(但是已经在环境中安装了的)就行
这些不要了的库在上一次编译时的shell里面输出
比如:
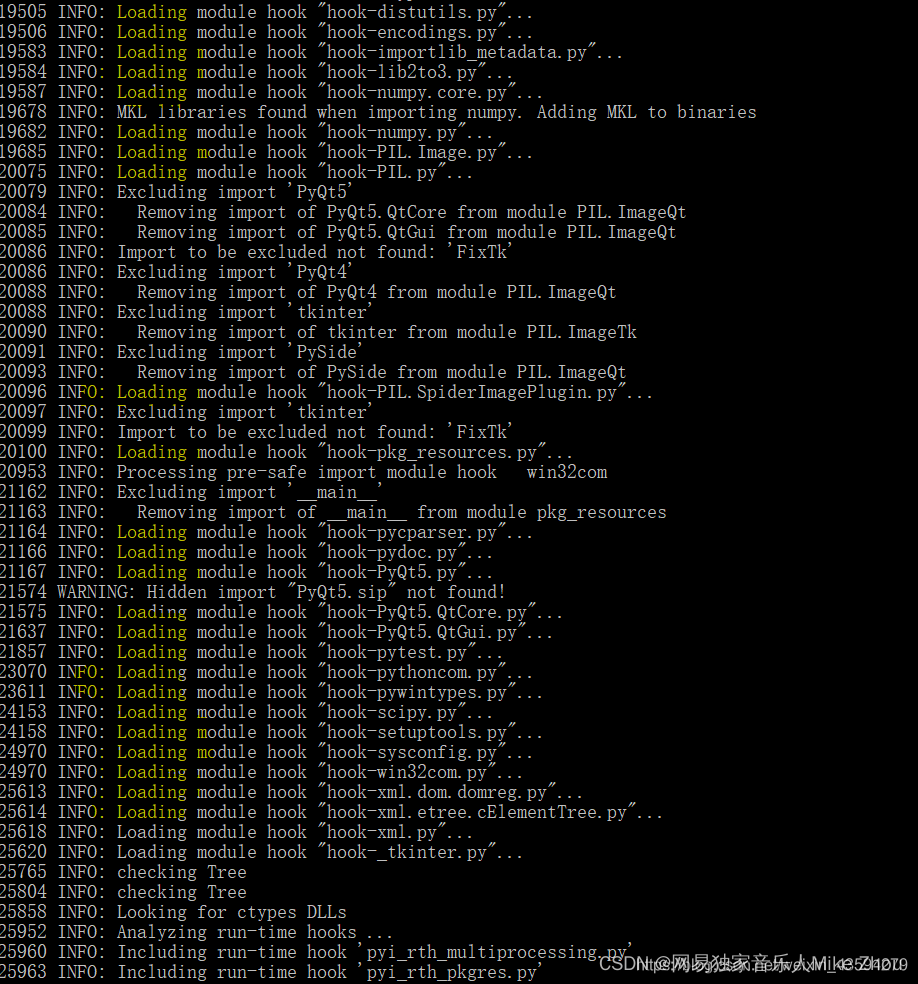

然后用pyinstaller --clean -F 某某.spec
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)